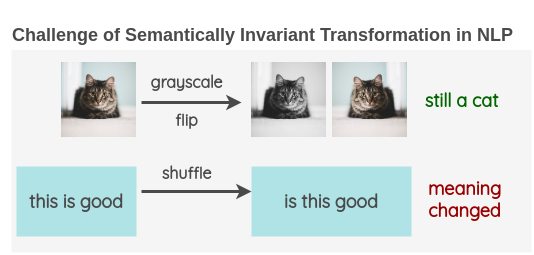
I reviewed the literature and have written a survey article on this recently. Please check it out.
4 Likes
Hi, and good to see you around here!
In fact, a college shared your article yesterday with my work team. Definitely thanks for your contribution, it’s the best review I’ve come across.
While I have you here, could you please expand a bit on Unigram Noising? You say:
The idea is to perform replacement with words sampled from the unigram frequency distribution. This frequency is basically how many times each word occurs in the training corpus.
So do you swap words for others of similar frequency? I don’t really get this one.
Again, thanks and good job!
1 Like
Hi,
Sorry that it was not clear in the article. The idea is basically to randomly select words in the original text and replace it with a random word from the uni-gram distribution. So, frequent words would have a higher chance of being selected than non-frequent ones. The papers uses it as a very simple noising technique only. The resulting sentence might not sound coherent when read by a human.
But, what you described could also be an interesting thing to try out. Swapping words for others of similar frequency.
1 Like
I see! Interesting, thanks for the clarification 