Sure @marcossantana, the code was in the link I posted, but here it is as a callback without using an END token.
> class SampleSMILES(LearnerCallback):
> def __init__(self, learn:Learner, path, vocab, debug, num_sample):
> super().__init__(learn)
> print('we have created smiles sampler callback')
> self.path, self.vocab, self.debug = path, vocab,debug
> self.encode_dict = MolTokenizer(lang='en').encode_dict
> self.max_seq_length = 150
> self.batch_size = 1024
> self.go_int = self.vocab.stoi['GO']
> self.num_sample = num_sample
> def confirm_vocab(self, epoch):
> if( self.learn.data.train_ds.x.vocab != self.vocab):
> print('non equal vocabs in sample smiles on epoch:', epoch )
> else:
> print('we have passed vocab check in sample smiles on epoch:', epoch )
> print('print vocab for epoch end:', epoch, self.vocab.stoi)
> def log_sampler_results(self, smiles, batch_sample, epoch):
> #----log number of valid compounds made on this epoch
> valid = 0
> for smi in smiles:
> mol = Chem.MolFromSmiles(smi)
> if( smiles != '' and mol is not None and mol.GetNumAtoms() > 0 ):
> valid+=1
> return valid
> def decode_smi(self, smiles ):
> #---replace encoded tokens with chemicals
> temp_smiles = smiles
> for symbol, token in self.encode_dict.items():
> temp_smiles = temp_smiles.replace(token,symbol)
> return temp_smiles
> def action_to_smiles(self, array, epoch):
> #---convert action tensor to smiles
> smiles_strings = []
> for row in array:
> predicted_chars = []
> for j in row:
> next_char = self.vocab.itos[j.item()]
> if next_char == 'GO':
> break
> predicted_chars.append(next_char)
> smi = ''.join(predicted_chars)
> smi = self.decode_smi(smi)
> smiles_strings.append(smi)
> return smiles_strings
> def sampler(self, epoch, current_batch_size):
> #---sample batch of compounds at end of epoch
> seqs_gen = ['']*self.batch_size
> go_int = learner.data.train_ds.vocab.stoi['GO']
> xb = np.array( [go_int]*self.batch_size )
> xb = torch.from_numpy(xb).to(device='cuda').unsqueeze(1)
> actions = torch.zeros((self.batch_size, self.max_seq_length), dtype=torch.long).to(device='cuda')
> learner.model.eval()
> learner.model.reset()
> with torch.no_grad():
> for i in range(0, self.max_seq_length):
> output = learner.model(xb)[0].squeeze()
> output_probs = F.softmax(output, dim=-1)
> output_probs[:,learner.data.train_ds.x.vocab.stoi[UNK] ] = 0
> action = torch.multinomial(output_probs,num_samples=1)
> xb = action
> actions[:,i] = action.squeeze()
> if( torch.sum(action) == 0):
> break
> smiles = self.action_to_smiles(actions, epoch)
> return smiles
> def reset_model(self):
> self.learn.model.reset()
> self.learn.model.train()
> def run(self, num, epoch):
> """
> Samples the model for the given number of SMILES.
> :params num: Number of SMILES to sample.
> """
> num_batches = math.ceil(num / self.batch_size)
> molecules_left = num
> smiles = []
> for _ in range(num_batches):
> current_batch_size = min(molecules_left, self.batch_size)
> smiles += self.sampler(epoch, current_batch_size)
> molecules_left -= current_batch_size
> valid = self.log_sampler_results( smiles , num, epoch)
> print( valid, num )
> #print('check gradients:', self.learn.model[0].encoder.weight.grad)
> self.reset_model()
> return valid
> def on_epoch_end(self, **kwargs):
> #===unpack kwargs
> print('beginning sample:', self.max_seq_length, epoch)
> epoch = kwargs['epoch']
> self.run(self.num_sample, epoch)
> self.confirm_vocab(epoch)
> print('mode of model:', self.learn.model.training)
> print('check gradients:', self.learn.model[0].encoder.weight.grad)
> print('we have completed sampler')
my tokenizer looked like this
BOS,EOS,FLD,UNK,PAD = 'xxbos','xxeos','xxfld','xxunk','xxpad'
TK_MAJ,TK_UP,TK_REP,TK_WREP = 'xxmaj','xxup','xxrep','xxwrep'
defaults.text_spec_tok = [PAD]
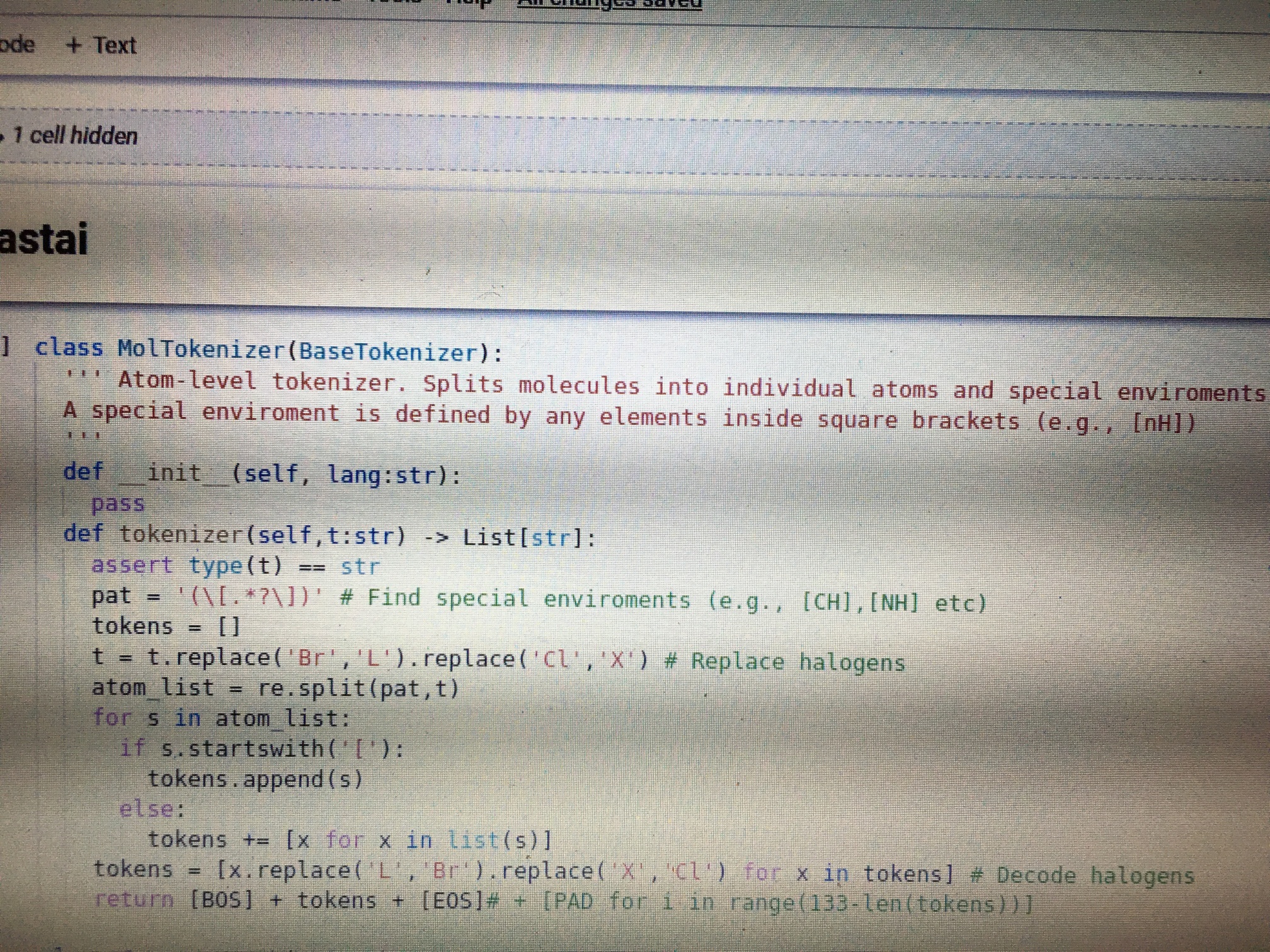
class MolTokenizer(BaseTokenizer):
def __init__(self, lang):
self.encode_dict = {"Br": 'Y', "Cl": 'X', "Si": 'A', 'Se': 'Z', '@@': 'R', 'se': 'E'}
pass
def tokenizer(self, smiles):
temp_smiles = smiles
for symbol, token in self.encode_dict.items():
temp_smiles = temp_smiles.replace(symbol, token)
tokens = list(temp_smiles)
tokens = ['GO'] + tokens
return tokens
def add_special_cases(self, toks):
pass
Another thing to look out for that I have just come across is the padding_idx. When I created a custom vocabulary, my padding_idx was set to zero. But if you look in all of the language model functions, and the awd_lstm_lm_config dict, fastai sets it to 1 as default when constructing the models! It is unfortunate that the padding_idx is hard coded like this, and not read in from the vocab that is present in the databunch when you create the learner. When you construct your learner for language modeling, I believe you should always do this:
config = awd_lstm_clas_config.copy()
config['pad_token'] =data.train_ds.x.vocab.stoi['xxpad']
learner = text_classifier_learner(data, AWD_LSTM, drop_mult=drops, wd=wd, pretrained=False, config=config)
learner.loss_func.ignore_index = learner.data.train_ds.x.vocab.stoi['xxpad']
Have others come across or noticed this padding_index issue? I am not fully sure what the repercussions are for the initial language model. But when transfer learning to create a regressor, if the padding_idx is not set correctly, the model will not account for it correctly when creating the mask.