Sourcegraph integrates seamlessly into the UI, and even I had problem understanding how to invoke it. Make sure the extension is enabled in chrome://extensions/
Check the following
Do you see this icon called View Repository when you are in a github repository? On clicking this, it takes you to sourcegraph’s portal to view the repo
Is there an option to ask the model take 20% of the data in a given folder (say the train folder itself) as validation data while using ImageClassifierData.from_paths() function?
I know the ImageClassifierData.from_csv() supports the validation indices functionality but it would be awesome and make life a lot simpler if we have that option in the ImageClassifierData.from_paths() function too. This would enable to quickly put together a folder of images and start building a model.
Currently, as a work-around I am using another small python script using glob to move random 20% of images to a separate valid folder.
No there’s currently no such option. But if anyone is interested in adding val_idx param to this function, I’d be happy to merge it . Of course it shouldn’t be possible to set both the val folder and val_idx
Sometimes when you let the model run on AWS for a long time, one might disconnect from the ssh session.
In a case like that even if we connect back to the Notebook server (which is running inside tmux) I cannot see the progress on each iteration (losses and metrics).
Does the learn object retain a history of the metrics?
Is there a way to retrieve the historical loss values from the learn/model object?
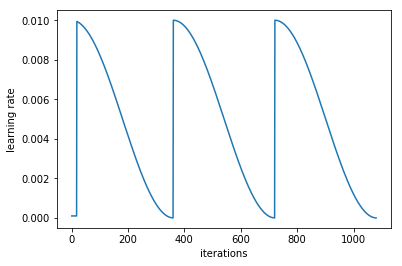
This is the tiny flat line on this graph starting at iterations = 0?
This is the good ol’ trick from part 1 v1 of first training with super small lr to get out of finding easy but sucky optima and then only increasing the learning rate to what we would like to use for training?
Just wanted to confirm I am reading this right and not going crazy Though not sure if reading this right actually precludes the second part of the statement from being true
preds1 = [preds1]*math.ceil(n_aug/4)
preds2 = [predict_with_targs(self.model, dl2)[0] for i in tqdm(range(n_aug), leave=False)]
return np.stack(preds1+preds2).mean(0), targs
The first line seems to be keeping the proportion of augmented images to be at most 80% if I am reading this right? I would assume this is again one of the small best practices that fastai gives us out of the box?
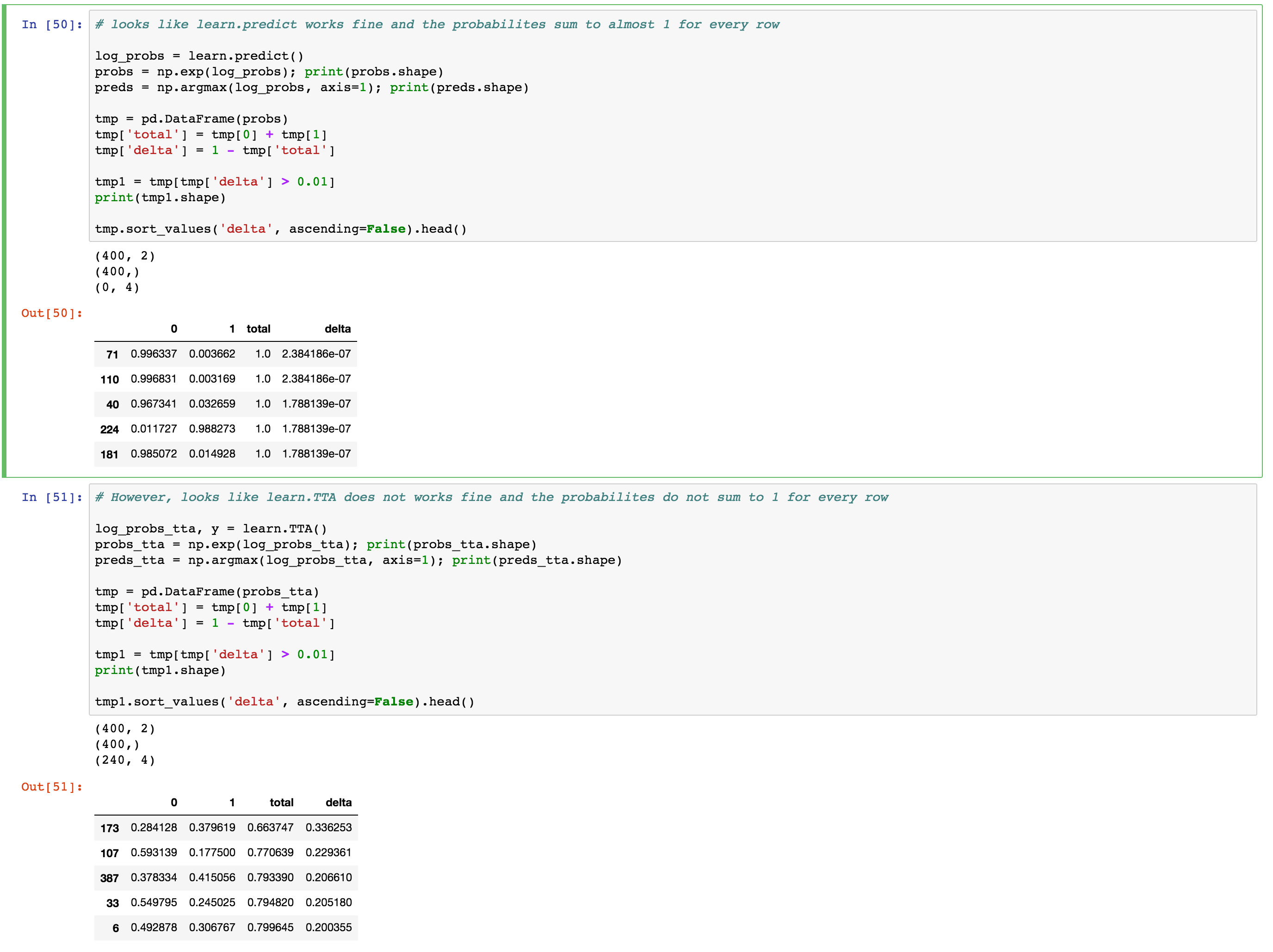
I am training resnet for a binary image classification task using our standard approach on a custom data of 200 images in every class. So in total 800 images (400 training, 200 per class and 400 validation, 200 per class).
I am using both learn.predict and learn.TTA. I have observed that the probabilities (sum of the class probabilities) do not sum to 1 (not even close to 1 in some cases) when I use learn.TTA(). Is this a bug?


 . Of course it shouldn’t be possible to set both the val folder and val_idx
. Of course it shouldn’t be possible to set both the val folder and val_idx