So I have been searching for a way to combine and train tabular + text data with all the good stuff from fastai (databunch api, 1 cycle training, callbacks …) to do some Kaggle competitions and came across this awesome blog post by @wgpubs in which he created a tabular + text databunch using databunch API. I changed few line of codes to get it to work on fastai 1.0.51+ and then built a custom model to combine RNN/LSTM and MLP (neural net layers) for end-to-end training.
Tested on Kaggle Mercari competition, it trained successfully and loss did go down but very slowly and the overall result is kinda underwhelming (middle of the LB). I am planning to debug this during next week.
Anyway, I think it works and since there are lots of folks asking for a mixed databunch + model, I hope this can be a starting point. Here is the code and notebook: https://github.com/anhquan0412/fastai-tabular-text-demo
I’d love if someone can test it on other dataset to see whether it’s effective to combine the model the way I did. Thanks!
Hi @quan.tran
Thanks a lot for sharing this. I am currently working on a model that extends ULMFiT to take numerical input features into account. I am a machine learning engineer at reply.ai and I am working on a product to classify customer support tickets based on text + metadata (things like warehouse status of the order). I am absolutely sure that only the combination of these two feature types can lead to creating a good model. So it is a very good test case.
I can not share the data with you . But I will let you know how it goes.
Did you check to compare if combining the text + tabular improves upon either one just by themselves? i.e., does the combined model improve upon just the text data?
I think it’s key to have a good test dataset. This is why I am excited about trying it out.
They way my dataset is structured it is absolutely clear that only the combination of tex and numerical features can lead to a good model.
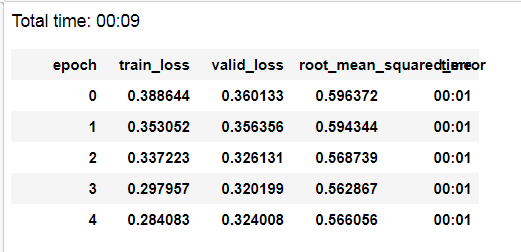
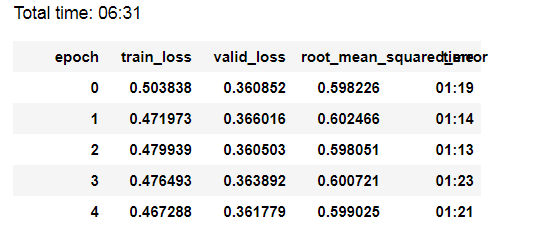
So I had few hours to spend today and run a bunch of different models on this Mercari dataset. Here’s what I found:
(all models are run on 2% of dataset for experiment)
Only tabular model: .562 on val set
Only text model: .599 on val set (with gradually unfreezing training)
Model is massively underfitting, and I already try to increase model complexity with 1 hidden layer size 1000. With >1 hidden layers for ULMFIT text regression, there’s a bug in the fastai code and my custom fix does not make model learn anything, so I will come back to this later when I have time)
Tabular + Text model: .557 on val set (with gradually unfreezing)
So, combining tabular+text model is the best option, but it’s still very average on the competition LB. Tabular model on 100% dataset only yields .548 on the LB (kaggle link for kernel)
I am thinking of analyzing outputs of the tabular model outputs and text outputs so I can add some weights before combining them.
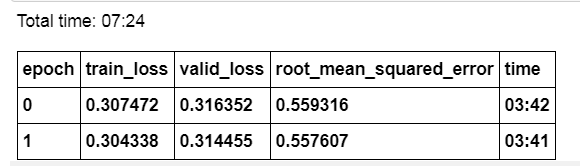
Just to let you know. I tried out your implementation and it improved my validation accuracy substantially. I trained on text + 1 categorical feature. I went from 40% acc with the only text Model to 45% acc with the text + tabular model.
I will have more categorical features available for training soon and I am confident that the model will further improve with more categorical input data. I will let you know how it goes.
@quan.tran
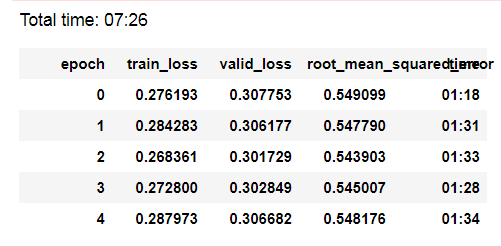
Update: I added more meta data to the model (categorical and continuous) and could get a even better result. 62% acc.
I have detected that learn.export() doesn’t work with your implementation I also had problems to make learn.predict() work. If you like we can team up and I can work on making your implementation production ready. I could also take a look at how we can compile the trained model with PyTorch.jit
That sounds great! I’d love to collaborate on this. There are still few things to improve though: the export and predict functions, my code is still running really slow compared to the other model and I leave out a small portion of ULMFIT model (the SortishSampler). I will come back to this soon.
@quan.tran
Wow. Version 2 runs much faster. Before it took around 28 min to train one epoch of the fully unfrozen model and now it takes only around 10 min!! I used a slightly different model with more fully connected layers on top. And my problem is classification so I used CE and softmax.
Here is my model head before the softmax layer:
I noticed that some of the fastai databunch default funcionality is getting lost. But it shouldn’t be too hard to add stuff to print out data summaries and add a model.data.classes property.
I hope I have time this week to look into extending your code and make model.predict and model.export work.
Hey @quan.tran! It’s me again!
I did some minor tweaks to your code to make TabularTextProcessor.process_one work.
Do you want me to submit a pull request so you cab review the code?
Hi, silly question, I’m a bit new to this API. How do I train a classification model instead of a regression model using your code? Can’t seem to figure it out, I’ve tried changing the label_cls to CategoryList and using CrossEntropyFlat but to no avail.
I just tried to do classification with the petfinder dataset and it is still working. Make sure you have the label type as integer train['target']= train['target'].astype(np.int8) . If you do this you don’t even need to worry about the label_cls or loss function because the fastai library will auto detect them. For reference, this is how I set the learner for tabular-text classification task
Hey @quan.tran
How is it going? Are you still interested in working on this?
Currently it is not possible to make a prediction on a single data point with version 2. This means it is impossible to put the model in production. I am very interested in making this work!!!
So, I’ve got a bunch of pricing lists that I have to put into a specific format constantly. Would it be possible to use this to create a training dataset from the finalized version of formatting, to classify dep_var without matching label columns and predict cont and categorical variables based on the trained dataset?
Hey @Andreas_Daiminger I was busy on other things and haven’t had a chance to look back at it. Do you have a list of functionality you want to have (beside the single data point prediction), as I have some time this weekend to play around with version 2 a bit (though I am not sure whether I’d be able to make v2 have all the functionalities as in v1 because v2 is fundamentally different)
So essentially, I’ve got a database of 48,000 e-commerce items, vendors send me price sheets with updated pricing information on them, and none of the columns are ever labeled consistently. The only thing that is generally consistent is the SKU or Model number, which I have trained as the dep_var from the database. These SKU’s share the same row as the pricing information, but since the labels on columns can change it makes it a bit tricky. Any insights would be greatly appreciated!
Hey @quan.tran!
I would like to use v2 in production. So everything related with that would be a top priority.
First single data point prediction and then model.export (difficult … I know!!)
I had a look myself, but could not come up with a simple way to make single data point prediction work. If you point in the right direction I can help you develop a solution.
Thanks for keeping interest!
 . But I will let you know how it goes.
. But I will let you know how it goes.