If CNN was designed to take square input then the kernel operating on the input will need some way of covering the whole square area - eg would need to pad rectangular out to square.
On top of the images you show above are bounding boxes for object detection- which above are pretty commonly rectangular. The convolution operator/s is/are smaller than the image and is/are moved about the image - so can identify smaller parts of the image
@kodzaks - The answer is unfortunately, yes and no. I’ll try to explain:
In fully convolutional CNNs, nothing “breaks” with non regular sized images as long as the pixel dimensions in height/width are a perfect multiple of the factor by which the CNN reduces spatial size by the last layer. For example, with YOLO v2 and v3, this factor is 32X, so all images need to have width = height as a multiple of 32.
Assuming that this condition is met, a lot of object-detection algorithms can be run on different sized images and still produce an output featuremap that is larger than the regular one for the “recommended” image size. This larger featuremap is equivalent to having run the algorithm several times on different crops of the original larger image. As long as the final step for classification/ROI determination doesn’t make any hard assumptions about the size of the output featuremap, the CNN architecture should be able to handle different dimensions.
In reality though, what could very well be happening in the images above is that the images could simply be squished along the longer dimension to make a square and then resized to the network recommended size (for example, default size for YOLOv3 is 416x416) and then all the object detection/classification starts from there. Since the truth ROIs are typically specified as a fraction of the original image X and Y dimensions, these still remain valid even after the image is rescaled. I’m most familiar with YOLO, and the reference implementation simply resizes any input image into a 416x416 image and performs the detections on it accordingly. The output ROIs can directly be applied to the original image since they are specified as fractions of the image width/height to recover the classifications/detections on what appears to be rectangular images.
In reality though, depending on the details of the implementation/architecture, some of these CNNs should be able to work directly with rectangular images.
Ok, thank you very much for the explanation, the question is can lesson 3 model work with rectangular images? I have a very similar to lesson 3 dataset, spectrogram images with annotations of what is in there. The only difference is that they are rectangular. If I just use them now, will they be cut? If so, the important info will be lost and the accuracy might suffer. I am just trying to figure out in practical terms what I should do here.
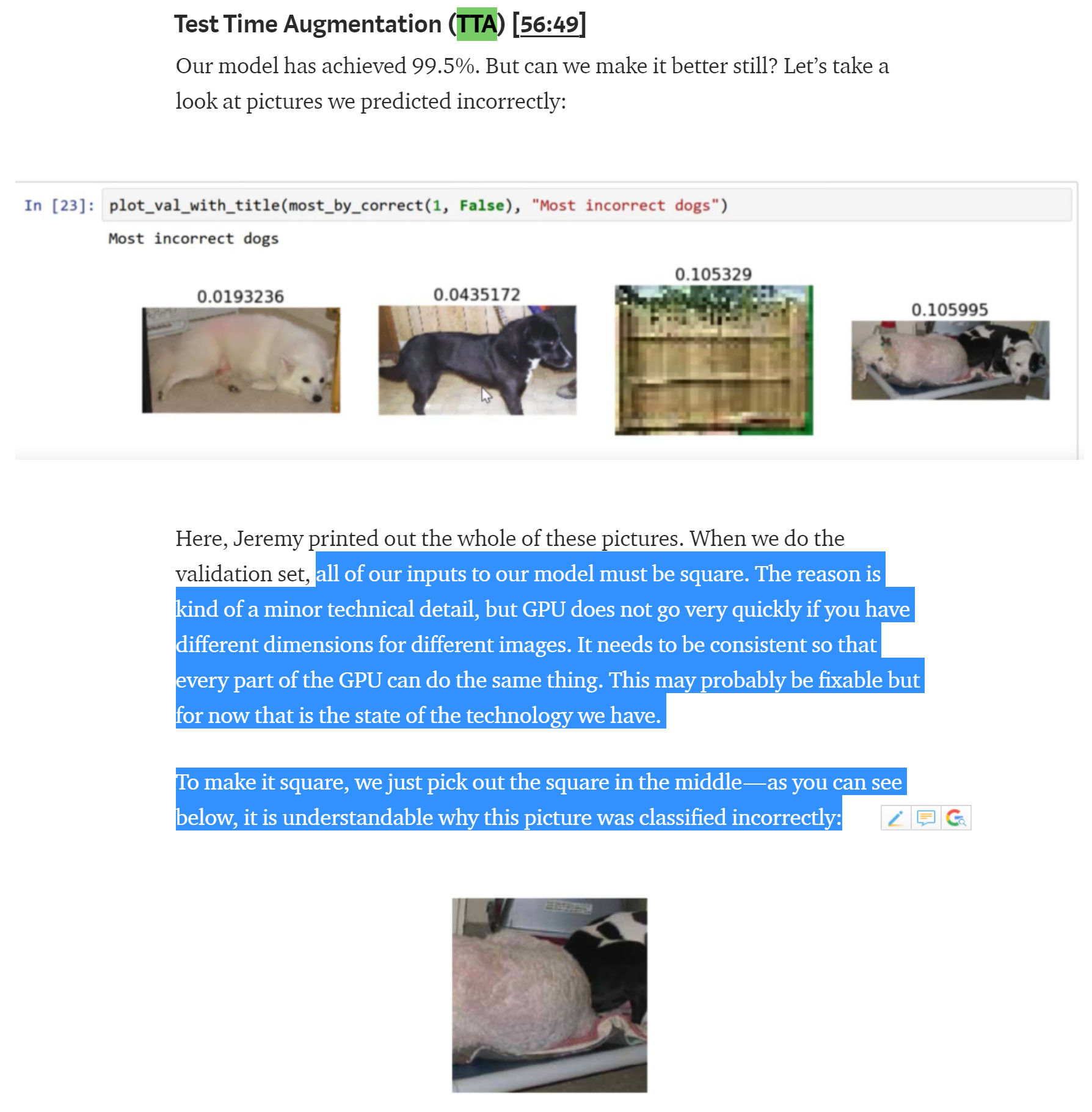
Is this still correct ? Does fastai v1 still crops the images as square in the middle?
Because in the wide rectangular spectrogram image, how about if the spoken word differs only at the end or the beginning of the spectrogram, which will be lost if square cropped during training or testing?
Does that new rectangular cropping method instead of square apply also on training and not only validation?
I found this related paragraph from the Dawnbench blog post , but it was not very clear whether the enhanced rectangular crop of fastai instead of square is used in fastai in prediction only or training as well. The post seems keeps saying in validation , in prediction and did not mention training.
A lot of people mistakenly believe that convolutional neural networks (CNNs) can only work with one fixed image size, and that that must be rectangular. However, most libraries support “adaptive” or “global” pooling layers, which entirely avoid this limitation. It doesn’t help that some libraries (such as Pytorch) distribute models that do not use this feature – it means that unless users of these libraries replace those layers, they are stuck with just one image size and shape (generally 224x224 pixels). The fastai library automatically converts fixed-size models to dynamically sized models .
I’ve never seen anyone try to train with rectangular images before, and haven’t seen them mentioned in any research papers yet, and none of the standard deep learning libraries I’ve found support this. So Andrew went away and figured out how to make it work with fastai and Pytorch for predictions.*
P.S.:
I think, found 2 mistakes where it mentioned rectangle but the correct is square which is I think a bit confusing for the reader:
"… were doing something really dumb: we were taking rectangular images "
"…lot of people mistakenly believe that convolutional neural networks (CNNs) can only work with one fixed image size, and that must be rectangular. "
We don’t have the clever version of rect training working yet - for now, we’re just squishing the image to the dims requested, if they’re not square. Rect cropping will be done for part 2.
So current version of fastai for rectangular images in training they are squashed, for validation and test they are not squashed according to :
But does that mean, currently it is better to avoid rectangular images, until further development, when the training will be able to deal with rectangular images in the same way test and validation do? Because if squashed here and not there, the accuracy will suffer?
Or is it squashed everywhere (in training, validation and test set)?
You could also try to make your spectrogram more rectangular by playing with resampling your signal, adjusting the fft size (for the vertical resolution) or the hopsize (for the horizontal resolution). This can all easily be done in librosa. You can then compare the results with just resizing the images.
It is good idea to check if it is squashed to 224x224 resolution or made changes to the FFT to make it less wide, that there is no significant loss in the image info.
I suggest that you compare one sample before and after this modification, and hear these two. You should transform back into time domain and play it and check that you can understand what is it and that there is no significant degredation to the extent that you cannot recognize what it is.
Usually if not always, if a domain expert cannot recognize your samples then DL model will not be able to do so too!
This is indeed a good idea. The amount of degradation the DL model can handle will also depend on the question asked. It wil presumably need far less info ( and can thus handle a far more squashed image) on the question “Is this a manatee or is this a boat” than on the question is this the manatee called “A” or is it “B”.
Actually, this is something I was wondering about. Our dataset is labeled, so the file will be coded as having manatee calls, having mastication (chewing) sounds, both or none. The none category is extremely broad as it includes all kinds of noises, water splashing, powertools noises, even people talking. Manatee calls and mastication sounds are variable as well, so in a sense we are asking DL model to generalize a lot. So how does this play into degradation issue due to squashing? Will it make it easier or harder to classify the file?