BTW to find this out yourself, you could start typing the first few characters of the architecture you want, eg incep, then hit the Tab key in your notebook. It’ll show you matching function names.
3 Likes
Hello,
So based on the recommendations you gave me for working with smaller sized images, I did research on CIFAR-10 and architectures that people have used and got good results.
I found this link https://www.kaggle.com/c/cifar-10 and started reading interviews of the winners, then one of the top-3 architectures seemed to be reasonable to implement in PyTorch.
Here is the link to the notebook I’ve created (this is my first time trying this so it may be erroneous, though it seemed to work  ):
):
https://github.com/KeremTurgutlu/myCNN/blob/master/CUSTOM%20CNN%20WITH%20PYTORCH.ipynb
Thanks in Advance
3 Likes
Nice! You can use this with fastai.model.fit without doing anything special - that is a low level function that’s designed to work with pretty much anything. The only thing you need to do is ensure your data is in a ModelData object of some kind (as all our data has been so far).
To use the full fastai fun, I think you just need to update fastai.conv_learner.model_meta, which is a dictionary that maps a function (which in turn creates your model) to an array with two values: the layer number to cut off to allow fine tuning (generally this is a global pooling layer), and the layer number where you want your 2nd layer group to start (for differential learning rates). It should be as easy as:
fastai.conv_learner.model_meta[my_model] = [o1,o2]
(where o1 and o2 are the two layer numbers I mention above).
I haven’t done this myself, so if something breaks, just holler!
I also found this resource for models that performed best on CIFAR-10. So some of these models might be better options when working with smaller images sizes.
1 Like
That’s perfect ! Thank you so much, I will definitely try this as soon as possible and let everyone know how it goes 
BTW I posted this in another thread - must more up to date than that Kaggle comp: https://github.com/kuangliu/pytorch-cifar
2 Likes
Thanks a lot, that makes sense. This makes the inceptionresnet_2 fairly accurate
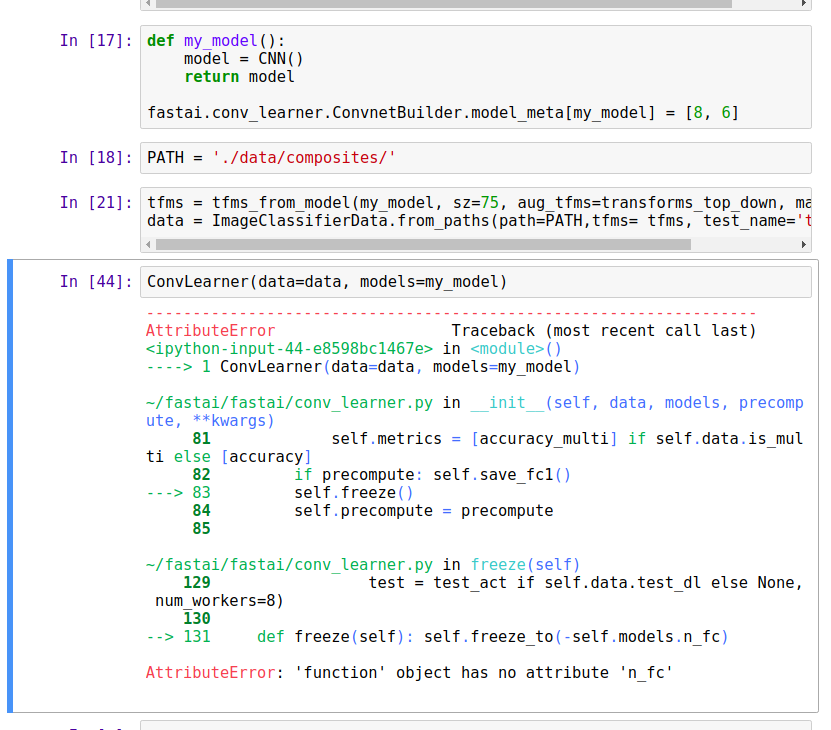
I’ve added my model class to model_meta but couldn’t figure out how to initialize it as a learn object
Hi, not be rude,however, can we have separate threads for each of the different project that we are working, e.g: one for iceberg challenge, one for dog breed , another one for cifar. Its hard to catch the flow of the threads.
That’s a good idea - although things aren’t always so separated - e.g. cifar is probably the best dataset to study for the purpose of tackling iceberg…
1 Like
Use the classmethods like from_paths and from_csv, not the constructor.
@kcturgutlu To anyone working on the Statoil Iceberg competition: How did you manage to get the data into the model for training? Whether by turning it into 2-channel or whatever.
If I send it in as (75,75) dim ndarrays, I’ll get an expectable error message asking for a 3D tensor.
If I img = np.reshape(img, (75,75,1)) – or (1,75,75) – I’ll get a CUDNN_STATUS_BAD_PARAM error, which I’m assuming is because I didn’t put together the images the right way.
I haven’t tested whether my system successfully trains the Lesson 1 notebook, though it was working fine with the dl2v1 course just a few weeks ago. If that turns out to be the case I’ll update here, but in the meantime: ?
Hello,
For the first part assume you used a pretrained network like ResNet…Since these networks are designed to be trained on ImageNet they expect a 3 channel image.
Second part as I understand is reshaping the array into a 1 channel one.
These are the things you can do:
1) Create an extra channel (mean of two channels or HH/HV or even a full 0 channel), then transform this 3d array into an rgb image. For this I’ve provided a kernel, which does the transformations and then saves the images as fastai desires /train/ship /train/iceberg,… so on. You can find the link to the kernel in the links part of this thread.
2) Write a custom CNN class which allows 2 channel inputs. I can also provide a github link for this but I am not quite finished with so I want it to be handsome before sharing Here is the tutorials for PyTorch : http://pytorch.org/tutorials/
3) Read kaggle kernels, see what other’s been doing to deal with this.
Best
Hope that I can help more if you provide more info later as well !
Here is my take on this iceberg challenge -
Statoil Iceberg Kaggle Classifier
There are plenty of room for improvements, even though I got 89% accuracy with overfitting.
I took help from this kaggle kernel for the 3rd band.
I used the fast ai library while doing it.
Couple of comments:
a - Little bit of commenting of fast ai api libraries will definitely be helpful.
b - The log loss of process is way high. I am not able to fix even though I have a good accuracy. Something odd is going on.
c - This thing takes a long time on cpu as well as gpu and the huge RAM on amazon ec2 was definitely helpful.
Finally, I would really appreciate comments on my take on this. Also if somebody can tell me how to reduce the log loss , it would be of great help. Thanks.
2 Likes
I have a question on SGDR process:
We are using the best lr that we found from lr_find() and use that lr as the largest value we will consider during SGDR process as in the function fit(best_lr, number_of_cycles, cycle_len(in_terms_of_epochs), cycle_mult)). So we expect this process combined with best_lr to find different minimas or in other words to escape the ones that are not best maybe.
I am thinking of cases where our best learning rate that we had from lr_find() might not be enough to escape some minimas. So would it be a good practice to do these steps:
1 Do SGDR with best_lr, peak an eye on how training and validation scores changing, if you are satisfied stop.
2 (Reset your weights to step 1) Do SGDR with best_lr, decrease cycle_len so that you have restarts within a epoch which may help to escape that local minima (num_cycles should be > 1 to get sense out of it).
3 Or what if we set a relatively higher learning rate with lots of cycles and with a considerable cycle_len like 1, then keep track of the point that we have minimum validation loss. Then having this information restart the trainnig and train exactly to be at that point.
1 Like
Yes @kcturgutlu those are the kinds of things I play around with. The rule of thumb I showed in class seems to work pretty well most of the time, but a bit of playing around like you describe can improve things further often.
BTW, if anyone comes up with better heuristics for training that seem to work reliably across a range of problems, please say so, since I’m always open to improvements!
1 Like
I have been playing with this competition for the last week. My first hunch feeling was that transfer learning wouldn’t be very useful so I concentrated on building a convolutional network from scratch that is not very complicated that fits the model well. Since I don’t know how to do this with fastai libraries I did it with Keras. Here is my progress so far…

Very nice! We had been putting our bets on pretrained networks with good tuning with @groverpr and @shik1470. After a lot trial and errors, @groverpr got ~0.20 on LB with resnet18. Now we are working on replicating the results to see what works on this data:
Things to consider further:
- Other architectures that worked well on CIFAR-10
- Semi Supervised Learning
- Snapshot Ensembling
2 Likes
This iceberg comp is a bit strange tho cause I can get 0.13 validation loss yet the loss on test set is over 0.2. Using DenseNet.
I think 0.20 is very good and did you consider the fact that 5000 images in test data are machine generated. So trusting your validation score might be a good thing, which means that you are probably better than your LB
1 Like