@yinterian yes, same for me. I have not investigate this yet, but it looks like c=children(m) should have returned empty list so c[-1].num_features cant slice a single element of a list.
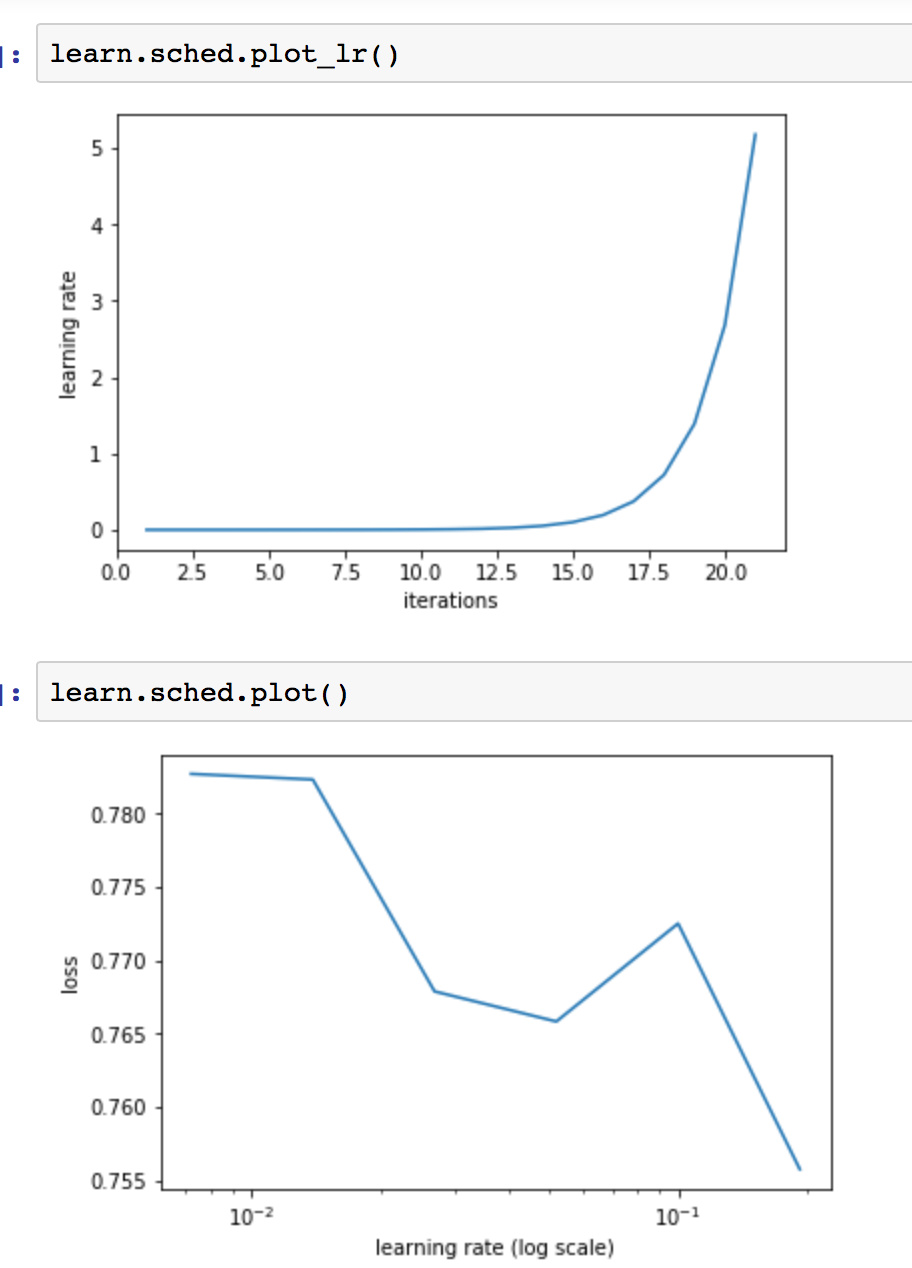
Question 1: What should I make off plot of loss vs. learning rate? Loss starts to increase with learning rate as in dogs vs cats but drops again at high learning rate. If I manually set learning rate to >0.1 in the fit I get bad results. The best I could get was using learning rate 0.003.
Question 2: Sine training set is rather small (~1600 images divide 70:30 between train/valid), is the above drop just fluctuation? Would it make sense to do k-fold cross-validation or data augmentation during this step as well?
I continued with remaining steps:
Train last layer with data augmentation (i.e. precompute=False) for 2-3 epochs with cycle_len=1
Unfreeze all layers
Set earlier layers to 3x-10x lower learning rate than next higher layer
Train full network with cycle_mult=2 until over-fitting
Question 3: During first iterations the training loss was much higher than the validation one (see below). Why? I didn’t study resnet34 yet in details, but is this connected with Dropout or any other form of regularization used in the model?
Question 1 : You want to pick the largest learning rate just before your loss increases. Idea here is to optimize the speed without losing model performance. (gives me 0.01)
Question 2: You can decrease the batch size to get more number of iterations since learning rate finder only scans your data ones = 1 epoch. So fluctuation is rather related with having less training data / bs. You can always go with cross validation I assume especially when training data is few.
Question 3: I am not certain of this part but in general as you tune any kind of ML model without overfitting you tend to get closer training and validation scores, the lowest bias-variance. I assume it has to do with initialization of the model in this case and randomness of the train-val split. Since your train-val splits may had been reversed and it wouldn’t matter, which would give the opposite scenario - having much more higher loss in validation than training.
Anze,
Since you don’t have that much data I would experiment with not unfreezing all layers (it may be that you are trying to learn way too many parameters). It is very weird that you are not overfitting.
Yes, which is definitely not what you want! You never want to increase the original size of your images, since it wastes compute time with no benefit.
Nothing wrong with using a 7x7 kernel size - I suspect based on this question you may be misunderstanding how kernels work… Maybe you could explain more about what you think might be the problem with this kernel size?
In general, you should set sz to the size of your input images, unless they are too large to handle directly on your GPU.
There are no arguments to those specific things - they are predefined sets of transforms to use as-is. Have a look at how each of those are defined, to see how to configure your own transform list. @yinterian maybe you could show a couple of examples?
Those should all be fixed now. git pull, and grab http://files.fast.ai/models/weights.tgz and untar it into the fastai/fastai folder (i.e. where the .py modules are).
Inception_v4 works fine - in 4 iterations it achieves <0.19 loss on dog breeds competition while resnets cant get better than 0.3. Now I am trying to learn.predict(is_test=True) and it looks like predict_with_targs function expects to see both x and y no matter is it valid set or test set (model.py line 120)
preda,targa = zip(*[(get_prediction(m(*VV(x))),y)
for *x,y in iter(dl)])
UPDT: ok, its not about x and y, but it throughs an error.
forgot the error message:
~/fastai/courses/dl1/fastai/model.py in predict_with_targs(m, dl)
119 if hasattr(m, 'reset'): m.reset()
120 preda,targa = zip(*[(get_prediction(m(*VV(x))),y)
--> 121 for *x,y in iter(dl)])
122 return to_np(torch.cat(preda)), to_np(torch.cat(targa))
123
TypeError: 'NoneType' object is not iterable
@jeremy Solved. Sorry for bothering, Jeremy - looks like test images were not loaded correctly. Even restarting a notebook did not help. I changed image size - and processed train/test/valid once again and this helped.
@jeremy inception_v4 with simple pre-tuning gives <0.2 here https://www.kaggle.com/c/dog-breed-identification/leaderboard. Thats currently in top 10 out of 200 (first 5 or so guys are using the whole Stanford dataset to build a model just for fun ). And we are just on the “Lesson 1” stage .
I blended inception_v4 with my previous model which was NN on top of extracted features from Keras inception and xception with pseudo labelling. So its like a blend of fastai part 1 v1 and part 1 v2

 .
.
