https://drive.google.com/file/d/1UvuULD4PzdfULmO6PQ4PjSR5S1UrbZlm/view?usp=drivesdk
Found this PDF…
That depends entirely on the problem and data. There’s no “right answer” here. Do you think the time period, or the start date, is the important choice for this model?
I can’t fail to notice that the lectures stopped coming! 
Still, the ones that were published were very, very educational! Thank you! Just what I needed on Random Forests
BTW gearing up to do the linalg course Ah the good things from @fastai just keep on coming! 
(kind of hard to believe a person / group of people can be so generous with others from half across the globe these days without any strings attached - definitely a very inspiring role model)
Expecting one today lately…
it’s been a week since Jeremy’s last post…
Be great but be Grateful ![]()
Definitely the best course and community that ever happened to my student life and online courses-side life!
Yes, this is pretty much what I wanted to say ![]() Even if those are all the lectures that we get, that has been already beyond amazing
Even if those are all the lectures that we get, that has been already beyond amazing ![]()
So much great material to work through! ![]()
Just added the lesson 9 video
There wasn’t one last Thursday due to the Thanksgiving holding in the US.
Just added the lesson 10 video.
Just posted another new ML lesson (we did an extra one this week after missing one with Thanksgiving last week).
Hi all,
I’m lucky enough to be in the MSAN program. To help you navigate the videos, i’ve attached my outline of the topics. Let me know if the video to topic list is out of sync.
Cheers
Introductions and class basics
Python basics
Git, Symlink, AWS
Python notebook basics
Crash course on pandas
FastAI introduction
add_datepart
train_cats
Feather Format
Run your first Random Forest
R^2 accuracy
How to make validation sets
Test vs. Validation Set
Diving into RandomForests
Examination of One tree
What is 'bagging’
What is OOB Out-of-Box score
RF Hyperparameter 1: Trees
RF Hyperparameter 2: max Samples per leaf
RF Hyperparameter 3: max features
Forecasting: Grocery Kaggle discussion, Parallel to Rossman stores
Random Forests: Confidence based tree variance
Random Forests: Feature Importance Intro
Random Forests: Decoupled Shuffling
Summary of Random Forests
Data needs to be numeric
Categories go to numbers
Subsampling in different trees
Tree size
Records per node
Information Gain (improvement)
Repeat process for different subsetes
Each tree should be better
Trees should not be correlated
Min Leaf Samples
Max Features
n_jobs
oob
interpretting OOB vs. Training vs. Test score
Feature Importance Deep dive
One hot encoding
Redundant features
Partial Dependence
What makes a good validation set?
What makes a good test set?
Random Forest from scratch : setup framework
Motivations for data science
Thinking about the business implications
Tell the story
Review of Confidence in Tree Prediction Variance, Feature importance, Partial Dependence
Building a Decision Tree from scratch
Optimizing and comparing to SKlearn
How to do 2 levels of decision trees
Fleshing out the RF predict function
Assembling our own decision tree
Cython
Deep Learning
Using pytorch and a 1-level NN
Walkthrough of MNIST number sets
Binary Loss func
Making a LogReg equivalent NN pytorch
Rewriting the 1-layer NN from scratch
Rewrite LinearLayer
Rewrite Softmax
Understanding numpy and torch matrix operations
Understanding Broadcasting rules
Rewriting matrix mult from scratch
Start looking at the fit function
Rewriting fit from scratch
Digression of Momentum
Rewriting gradient and step within fit function
NLP
Bag of words / CountVectorizer
LogisticRegression w. Sentiment
NLP : trigrams
Naive Bayes Classifier
Binarized version of NB
NBSVM - combination of probs
Storage efficiency of 1-hot
RossMan store examination
Introduction to embeddings
Hi,
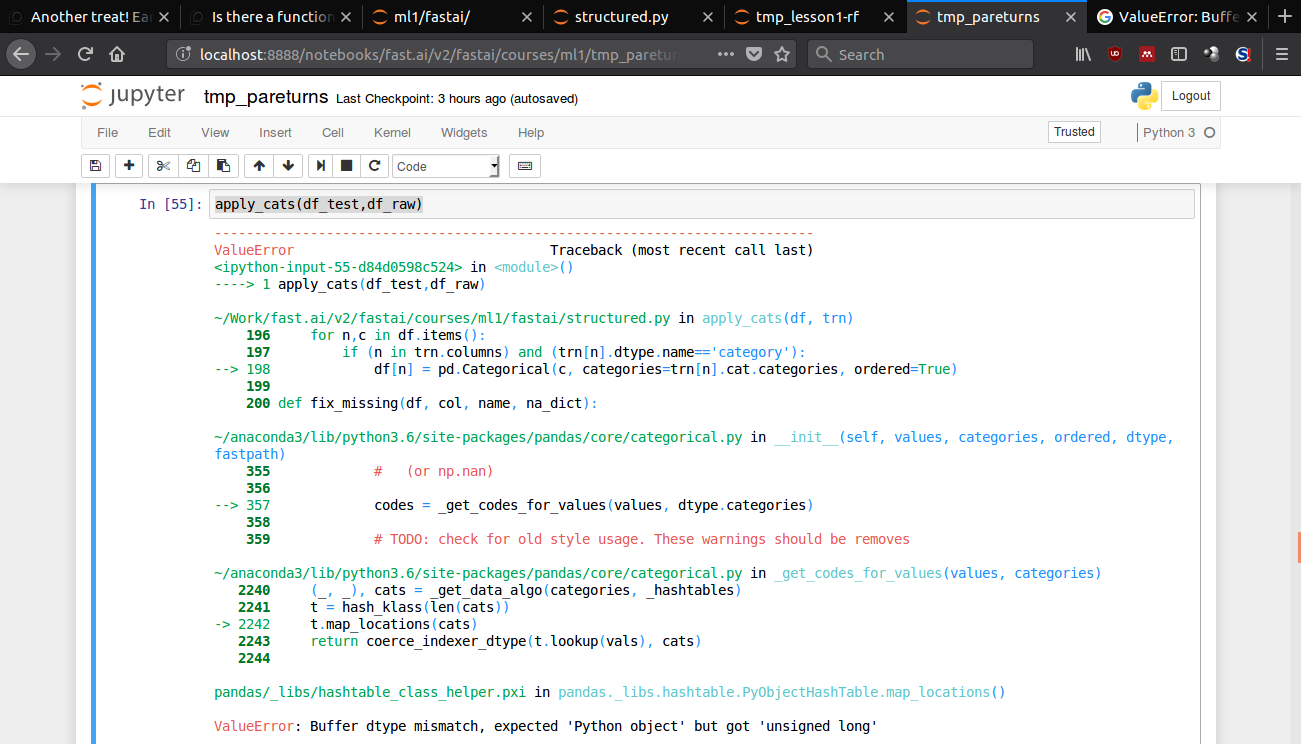
I am trying ML Lesson 1 RF on a different datset.
To convert into categorical values,I have done:
train_cats(df_raw)’
Now to apply same kind of categorical codes to ‘test’ dataset as Jeremy mentioned in video, I am doing:
apply_cats(df_test,df_raw)
But I am receiving below error:
Please help.
It’s actually fit(net, md, epochs= 2, opt=opt, metrics=metrics, crit= loss) as I see in fastai/fastai/model.py
Thanks @timlee
What are thoughtful and helpful thing to do ![]()
Hi guys,
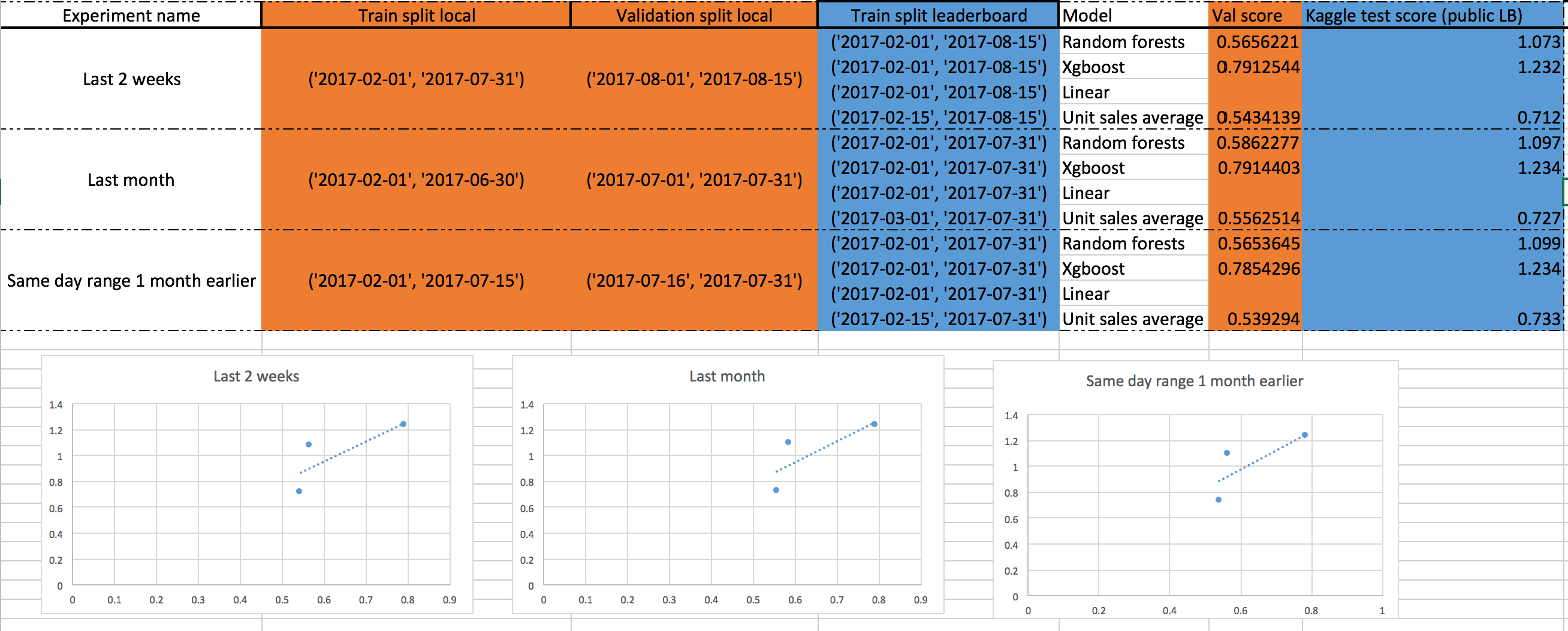
Going back to this timestamp where Jeremy describes how he find a good validation set by plotting the loss of different validation set scores against Kaggle test scores from the public leaderboard. I tried to do this experiment myself on the groceries competition by using the different validation sets Jeremy described in his video but I just feel like there is something wrong with my approach. Here are the results:
I first trained on the splits in the orange columns, saved the results and retrained the model from scratch on the split from the blue column before submitting the results to Kaggle.
As you can see my lines seems to be almost identical even if the validation sets differs. Do you have any clues why it didn’t work? (Or maybe all the validations sets are equally effective? But I doubt so)
Thanks 
Just posted the final machine learning lesson!
Thank you so much for sharing with us the ML Videos. Enjoyed every one of them. But the last one on “Ethics” is the best of all. After empowering us with the methods and knowledge, you have given us the moral compass to guide us forward.
Thank you and the best wishes to all the MSAN students who were fortunate enough to take this class in-person.
Thanks a lot for all you’ve done Jeremy. I really enjoyed every lessons of this mooc (as well as the one on DL). Knowing the lesson 12 being the last one leave me with a little feeling of emptiness. I’m looking forward for DL & ML part 2. Thanks again
Thanks so much Jeremy!! These lessons are extremely valuable. Thanks again a lot for sharing your indepth knowlege…