where can i ask about an error i am getting while going through the deep learning course?
Hello,
I am a programmer at a large school district and I want to use the longitudinal data I have to predict who is at risk for dropping out and what remediation efforts are best for the student who is at risk.
I am watching the videos and I see the benefit of layered machine learning and want to apply this to my work. Where can I go to find AI models used with education data and not get information about teaching AI topics in education? By the way, I have a tendency to learn how to swim by jumping into the deep end. Thanks in advance for any help.
Hi,
Noob here.
Here’s the dataset that I’m working on https://www.kaggle.com/arpitjain007/game-of-deep-learning-ship-datasets
and I’m using fastai, I’ve successfully built the model but I have no idea how to test it with ‘test.csv’ file.
Here’s my code
from fastai import *
from fastai.vision import *
path = '../input/train'
path = Path(path)
path.ls()
df = pd.read_csv(path/'train.csv')
data = ImageDataBunch.from_df('../input/train/images', df, ds_tfms=get_transforms(), size=224, bs=64 ).normalize(imagenet_stats)
learn = cnn_learner(data, models.resnet50, metrics=accuracy, model_dir='/kaggle/working/models')
learn.fit_one_cycle(5)
df_test = pd.read_csv('../input/test_ApKoW4T.csv')
I don’t know how to use the Test Dataframe to predict.
did you figure out how to post a question?
We use Discourse (a free, open source discussion platform) for these forums, and discourse relies on a system of trust levels. New users can only create a topic after they first spend 10 minutes (total) reading at least 3 different posts on the forum. We have these limits in place to encourage you to get acquainted a bit with the discussions and some of the existing content before you start posting, and to discourage spammers. After spending 10 minutes reading at least 3 different posts,
maybe you are a new user?
New Kaggle competition
Ciphertext Challenge III: Wherefore Art Thou, Simple Ciphers?
"In this new decryption competition’s dataset, we’ve gone… to a time before computers… Shakespeare’s plays are encrypted, and we time travelers must un-encrypt them so people can do innovative stage productions with intricate makeup, costumes…
As in previous ciphertext challenges, simple classic ciphers have been used to encrypt this dataset, along with a slightly less simple surprise that expands our definition of “classic” into the modern age. The mission is the same: to correctly match each piece of ciphertext with its corresponding piece of plaintext."
Hello, I’m currently working on the XRAY dataset to predict the pathologies.
Is there a way to find masks using maskrcnn on the image data bunch created using the data block api ?
Also, can we use a unet architecture without annotations or masks and directly on the xray images ?
Thanks.
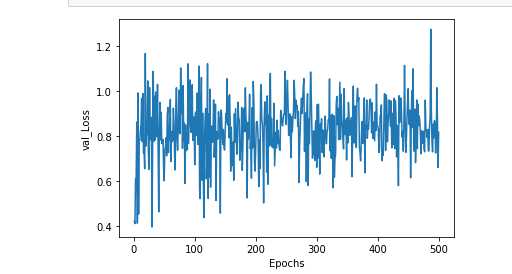
Why does my validation_loss plot have many fluctuation? Also, its loss range is from 0.4 to 1.2?
And also, why does it start from low to high? Isn’t that weird?
My code:
import tensorflow as tf
import scipy.io as spio
import random as rn
import numpy as np
import os
from keras import backend as K
mat=spio.loadmat('32_32/X_train123.mat', squeeze_me=True)
mat1=spio.loadmat('32_32/Y_train123.mat',squeeze_me=True)
mat2=spio.loadmat('32_32/X_test123.mat',squeeze_me=True)
mat3=spio.loadmat('32_32/Y_test123.mat',squeeze_me=True)
x_train=mat['x_test'] # x_test is x_train. typo
y_train=mat1['y_train']
x_test=mat2['x_test']
y_test=mat3['y_test']
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
#########################################################################################################################
os.environ['PYTHONHASHSEED']='0'
np.random.seed(37)
rn.seed(1254)
tf.set_random_seed(89)
session_conf = tf.ConfigProto(intra_op_parallelism_threads=1, inter_op_parallelism_threads=1)
sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
K.set_session(sess)
#############################################################################################################################
model=tf.keras.models.Sequential()
#model.add(tf.keras.layers.Flatten()) ###############don't delet
model.add(tf.keras.layers.Dense(256,input_dim=3001,activation=tf.nn.tanh))
model.add(tf.keras.layers.Dense(256,activation=tf.nn.tanh))
#model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(128,activation=tf.nn.tanh))
model.add(tf.keras.layers.Dense(128,activation=tf.nn.tanh))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(1, activation=tf.nn.sigmoid))
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])
history = model.fit(x_train, y_train,
validation_data=(x_test, y_test),
epochs=300)
###########################################################################################3
val_loss,val_acc =model.evaluate(x_test,y_test)
In this plot the epochs is 500.And as you see ,it seems that something is repeated frequently.
Have people checked out Groq?
Would love to know what @Jeremy and @Rachel think
Is it going to be a massive breakthrough in terms of deep learning applications?
Thanks
Yes, machine learning is a part of data science. So there’s plenty of relations between them. The machine learning algorithms train on data delivered by data science to become smarter and more informed in giving back business predictions. The main difference lies in the fact that data science covers the whole spectrum of data processing. It’s not limited to the algorithmic or statistical aspects. Read this article to learn the difference between data science, machine learning and artificial intelligence: https://www.cleveroad.com/blog/data-science-vs-machine-learning-vs-ai
It’s very useful!! Thanks!
Hi I am working on a cats vs dogs classifier, but for some reason my loss function is not decreasing and it is stuck at 69%. I am using
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 3)
self.max_pool = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(16, 32, 3)
self.conv3 = nn.Conv2d(32, 64, 3)
self.conv4 = nn.Conv2d(64, 32, 3)
self.conv5 = nn.Conv2d(32, 16, 3)
self.batch_norm2 = nn.BatchNorm2d(16)
self.fc1 = nn.Linear(784, 128)
self.fc3 = nn.Linear(128, 64)
self.fc4 = nn.Linear(64, 2)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.max_pool(x)
x = F.relu(self.conv2(x))
x = self.max_pool(x)
x = F.relu(self.conv3(x))
x = self.max_pool(x)
x = F.relu(self.conv4(x))
x = self.max_pool(x)
x = F.relu(self.conv5(x))
x = self.max_pool(x)
x = x.view(-1, 16*7*7)
x = F.relu(self.fc1(x))
x = F.relu(self.fc3(x))
x = F.relu(self.fc4(x))
return F.softmax(x)
for epoch in range(EPOCHS):
for j, sample in enumerate(dataset_loader['train']):
running_loss = 0.0
optimizer.zero_grad() #zero the parameter gradients
output = net(sample['image'].to(device))
loss = criterion(output, sample['label'].to(device))
loss.backward()
optimizer.step()
running_loss += loss.item()
print(epoch, ':', running_loss)
I am using this dataset:
Here is the whole code:
https://drive.google.com/open?id=1o_1YT859FrR2cH7si8kyNmYSDva_xyy-
hi, maybe you can try adding some dropout between your Linear layers.
Just want to share a great read on Geoffrey Hinton, Yann LeCun, and Yoshua Bengio’s talks at AAAI 2020. AAAI 2020 | A Turning Point for Deep Learning? Hinton, LeCun, and Bengio Might Have Different Approaches
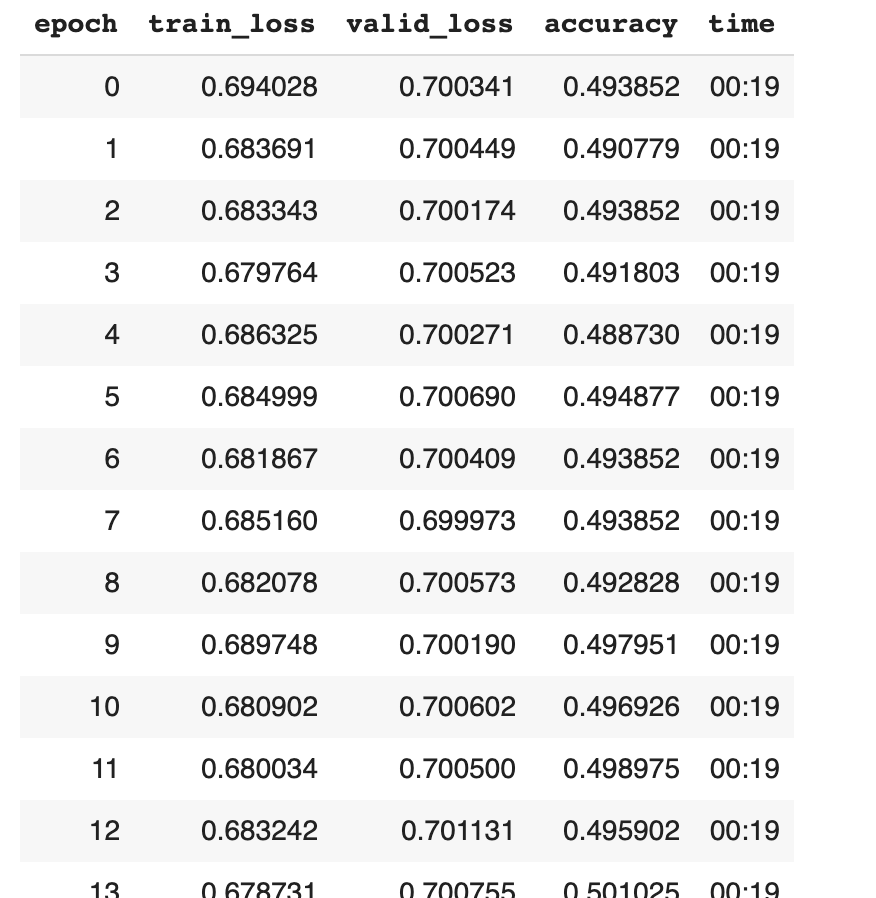
Hi, I use the resnet to classify images. But I get the a question that the accuracy is always around 0.5. I use the resnet50 and the dataset are 2 classes(0 and 1). I have tried the loss_func = LabelSmoothingCrossEntropy, but it did not work. And I have used the lr_find. Do anyone face the same question and find some solutions?


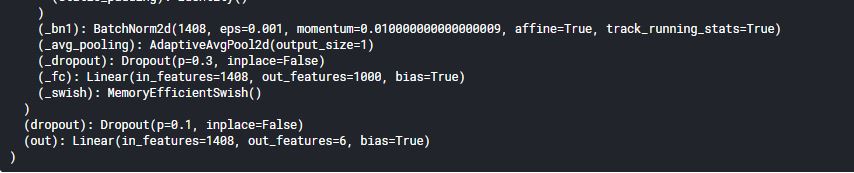
What does bias=True mean in last layer of efficient net.
Belwo is picture for more clarity.
And can we give out_features more than our classes in classification task.
Suppose I have 4 types of flowers in dataset. Can I use out_features=6 in efficient net.
If yes what are its pros or cons.
A picture of efficientNetB2.
thanks for the specifics
How can I increase the accuracy of perceptron model? I already done data normalisation by which i got a good result! My model jumped from 0.75 to 0.79. I want to increase it more till its possible. Shall I get some tips and techniques to do so?
MLP and CNN:
Recently I trained CNNs for image classification, and I have an idea about CNNs.
I’ve read the book which said that CNNs are trained by transforming to
MLPs with shared weights.
However, if we can train a good CNN, say ‘N’, by transforming it to M_N,
then we can also train an MLP ‘M’ that performs as good as ‘N’.
At least ‘M’ is the same as ‘M_N’.
We can even train ‘M’ to be better than ‘M_N’ since ‘N_M’ is restricted to share weights, while ‘M’ can be in any form.
What is the main reason that CNN can obtain good results on image classification while MLP can not?