You’d need to write a custom transform that probably goes on the batch level so you can adjust your x’s but not your y’s. Assuming both X and Y are images
1 Like
I thought that will be the case, Thank you for confirming!
1 Like
@vijayabhaskar (since it’s relevant):
2 Likes
Would people be interested in seeing XGBoost applied during the tabular lessons? This would be in an ensembling example, not on its own (as I still want to keep the focus on fastai’s tabular model), but the powerful TabularPandas let’s us do it very easily
4 Likes
Yep to this!
Far behind in the class but I just got through my first Google Colab and I’m soooo excited. I had difficulty downloading the images from google images, but I read thru the forums and finally got it. I have such a slow brain that I had to watch and transcribe Zach’s notes to make sure I understood everything before I attempted to run on the Colab site.
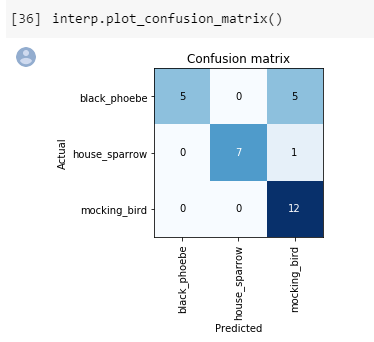
I ended up doing 3 classifications of birds, like his, but chose different ones. My first fun thru fit_one_cycle ended up being 70% error rate. I was like what the??? I didn’t clean up my images or anything, so I guess i should have looked. When I did stage 2 I didn’t realize I couldn’t just run the different learning rates without reloading it from stage 1. Good thing I saved it. Messing around with the learning rates, I was able to get 20%! YES!
When I did the confusion matrix, I understand how I got those huge error rates as I got images of nests and things that aren’t birds! ahh, lesson learned. clean up my data.
Thanks for all the notes on this forum as I read and learn.

4 Likes
I am trying to run the code from notebook 4 multilabel, but running into key errors while creating dls = planet.dataloaders(df).
KeyError: 'c'
or
KeyError: 'a'
I get this error with all 3 methods, unsure what is the issue. My code here
I’m interested too!
Quick question. When trying to get the model to say “I don’t know” you turned it to a multi label classifier so that it wouldn’t output anything lower than a certain interval x. Why not just use a single label classification model and hide low confidence guesses in production?
I’ll take a look at the multi-label example later today and make sure nothing changed with the new version.
1 Like
Because we don’t actually have that ability with the softmax layer, everything is 0-.99. Otherwise we certainly could if we just grabbed the raw outputs. Just this is a much faster way ![]()
1 Like
Sorry, I’m confused. Doesn’t the multi label classifier determine whether or not an answer is confident via the softmax numbers aka the confidence in percent from 0. to .99? Why would I need the raw outputs? Also, can you add sparsifying/pruning models to the course? I think it’s important for people looking to speed up their predictions and save space when using models on restricting devices (raspberry pi for example)
1 Like
I’m saying from the non-multilabel (just using a regular single label classification). To answer the outputs question, when I go test the DataBlock I’ll go look at what the multi-label’s raw outputs are  (as I don’t know!)
(as I don’t know!)
@akschougule could you please try again, it seems to work for me on fastai 2 - ‘0.0.10’
2 Likes
I don’t have experience here, so that’s a no ![]() there’s been a little discussion about pruning fastai models here on the forums that I know of. Let me try to find the link
there’s been a little discussion about pruning fastai models here on the forums that I know of. Let me try to find the link
Edit: found it @mschmit5 Quantisation and Pruning Research with Fast.ai
@mschmit5 Just to add to what Zachary said. we use different loss functions.
Cross entropy loss is used for the single label case. Softmax is the activation for the single label case. Softmax is great when you have exactly one (no more than one and definitely at least one) of the classes. Applying softmax here is just rescaling the raw output to 0-1 range. So you could in fact avoid softmax and make a prediction - ie the class of the highest raw output.
In the multilabel case the loss is binary cross entropy. You are checking for each class whether it is present or not based on a threshold. So i don’t think raw scores can be used here. You will need to convert it to the 0-1 range and then use the threshold. ![]()
2 Likes
Sure, will try.
How do you check the fastai2 version? Trying fastai2.__version__ or fastai.__version__ gives me an error.
Try ‘!pip show fastai2’ in a cell @akschougule
2 Likes
import fastai2
fastai2.__version__
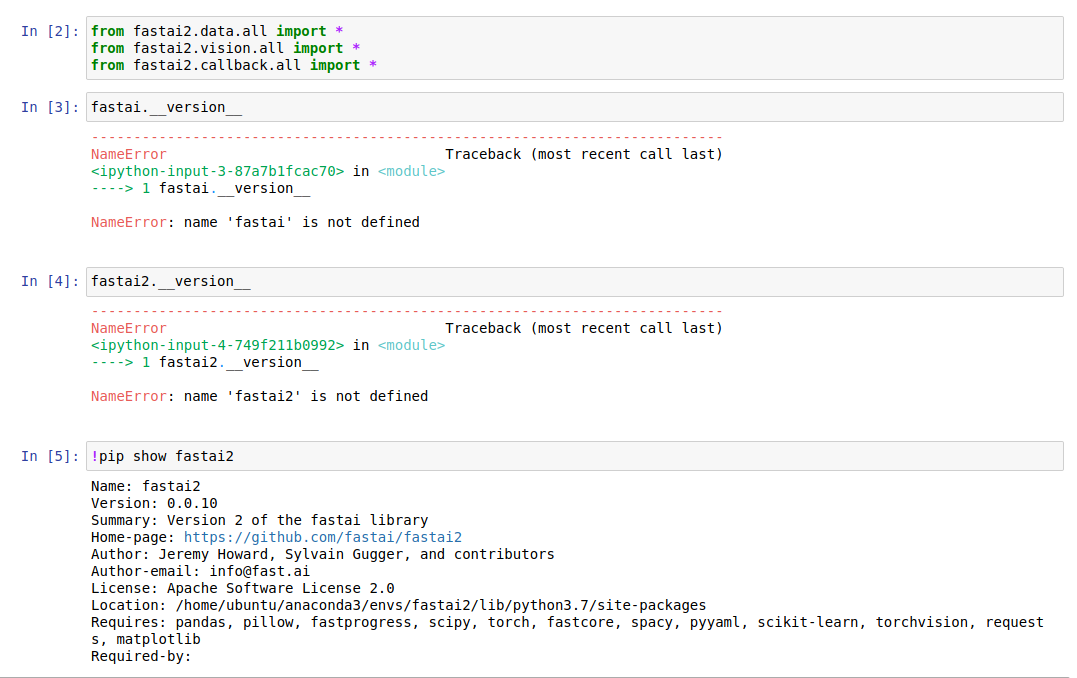
Are you still getting the error?