i agree with you just not sure why it works correctly if that is the case.
It works correctly because we explicitly state it for our metric (and why they’re different)
Is there a way in fastai v2 to provide a different thresh value to different classes in the multi-class classification? rather than just a single value for all classes. While theoretically this could be useful and have seen this usage in some Kaggle kernels, I would also like to know whether anyone has actually used such an approach of different thresh for different classes in practice.
This would be done via some form of a custom loss function to some degree or metric. (And this would also be PyTorch code). You’d have to explicitly say what each thresh is and check that tensor but it could be done.
Probably similar to something like a weighted loss function
I was re-visiting some of the notebooks, most precisely pets. I realized we create the dataloaders using 2 different methods
Method 1
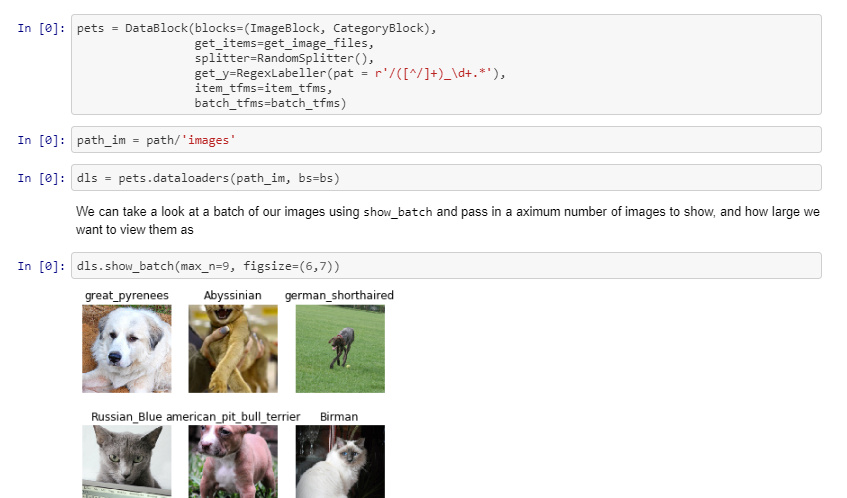
Method 2
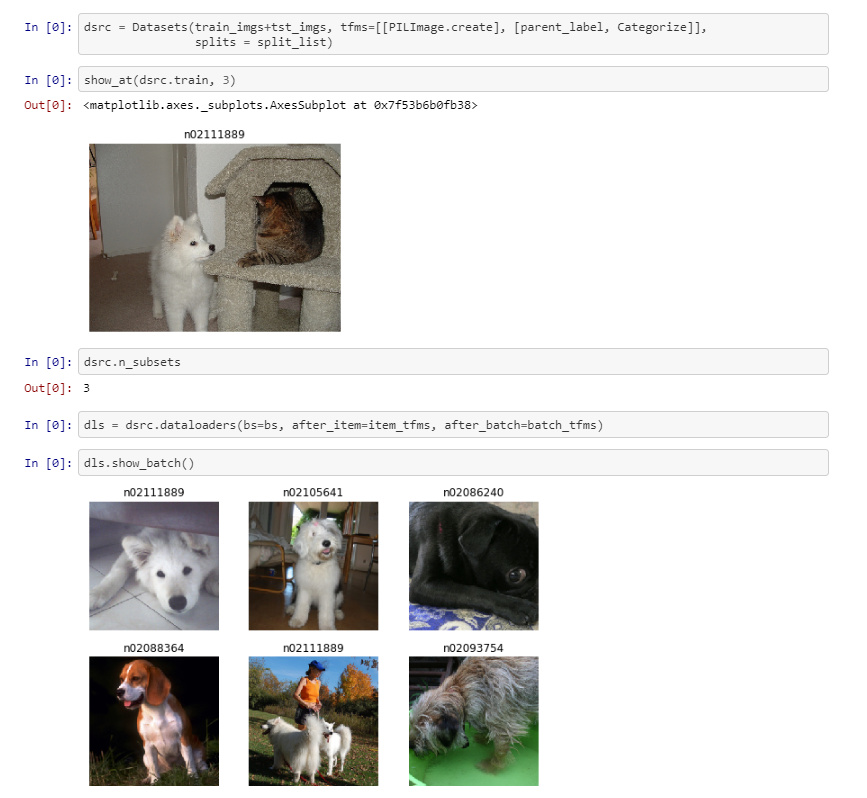
Note the change Datablock -> Datasets
I am however not able to map it in the slides (where is Datasets?):
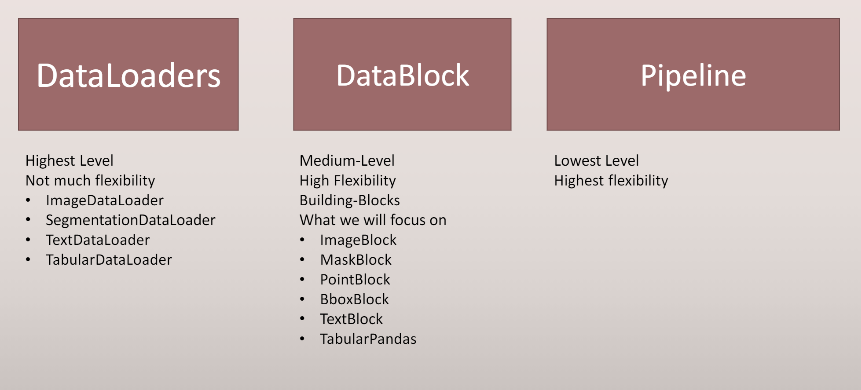
Thanks a lot for sharing your wisdom 
2 Likes
Thanks a lot for that catch @mgloria! Datasets should be the lowest level (instead of PipeLine). I’ll try to put that edit in before class if I can.
1 Like
I think fastai2 having a threshold in the loss function definition for decodes is going to cause some confusion. BCEWithLogitsLoss doesn’t use a threshold, as cross entropy loss wouldn’t work with one (or wouldn’t work nearly as well).
I assume its used for display purposes such as show_results and for the class tensor in get_preds?
class BCEWithLogitsLoss(_Loss):
def __init__(self, weight=None, size_average=None, reduce=None, reduction='mean', pos_weight=None):
super(BCEWithLogitsLoss, self).__init__(size_average, reduce, reduction)
self.register_buffer('weight', weight)
self.register_buffer('pos_weight', pos_weight)
def forward(self, input, target):
return F.binary_cross_entropy_with_logits(input, target,
self.weight,
pos_weight=self.pos_weight,
reduction=self.reduction)
1 Like
Yes actually, that would make a lot more sense ![]()
Here’s also the documentation for it, which answers a few questions:
https://pytorch.org/docs/stable/nn.html#torch.nn.BCEWithLogitsLoss
When it’s closer to completion, the documentation for fastai2 should make it clear that the threshold in decodes for BCEWithLogitsLossFlat and the argmax in decodes for CrossEntropyLossFlat are not for the loss functions themselves, and are rather for returning results from predictions.
2 Likes
The notebook you could mention this in is the notebook here:
(all documentation is generated from these notebooks).
Here is the link to the livestream tonight:
Bare with me, internet issues again, so we’ll be doing it from my apartment.
1 Like
I’ve added a notebook detailing how the new summary works for the DataBlock API, and how to work with it on a low level API. (Same one we did in class together) Here it is:
3 Likes
Great questions!
I’m not 100% sure of these architectures so I don’t want to provide false answers.
Maybe we should wait for Prof. Zach to share the answers ![]()
3 Likes
Sure, not a problem @init_27 
I’d mostly look at the ImageWoof leaderboard (what we talked about this week) for what’s new. Else the paperswithcode leaderboards show the papers and arch’s that’s the best at certain tasks.
2 Likes
Thanks Zach! I’m yet to get to Lesson 3. Your Lesson 2 made me detour into having/wanting to take some PyTorch tutorials 
2 Likes
I’ll also say (as I’ve done this quite a bit) implementation turns into an art form and you really just gotta practice adjusting these models to the framework (if needed). It’s an excellent skill to have, as we can take absolutely any PyTorch model and convert it to the library. We’ll show an example of this on the pose detection lesson. We may not get to the full inference, as I’m working on that now trying to figure out how to reverse a few things, but that lesson we’ll talk about porting models, datablocks, whole 9 yards
I was hoping to go more into it this lesson but we couldn’t (too many other things on my end). I may next lesson or tag it onto audio.
Actually on said topic, would people rather see something like a computer vision classification model for that (instead of just pose detection)? Or what would be most helpful to you guys? Whatever we do we’ll go over splitting the model, pretrained weights, etc. probably one of the easiest would be like EfficientNet on a classification problem, but let me know!!
4 Likes
Also, minor clarification on a point I made on lesson 3 (nice catch @foobar8675). Let’s say we do the following, we have a list of points (in which going into our block are all one giant string) like so:
pnts = torch.tensor([1,2,3,4])
What our .view(-1,2) is truly doing is converting this to an x,y list:
ten.view(-1,2) ->
tensor([[1,2],
[3,4]])
So now they are paired like you would expect points to be ![]()
view is similar to numpy’s reshape function. For anther example, let’s use a 3x6 tensor like so:
3dten = torch.tensor([[1,2,3,4,5,6],[1,2,3,4,5,6],[1,2,3,4,5,6]])
Now we can do -1,2 again and get the following:
tensor([[1, 2],
[3, 4],
[5, 6],
[1, 2],
[3, 4],
[5, 6],
[1, 2],
[3, 4],
[5, 6]])
We could also do 2,-1 and get this laterally:
tensor([[1, 2, 3, 4, 5, 6, 1, 2, 3],
[4, 5, 6, 1, 2, 3, 4, 5, 6]])
What does this mean? The first value dictates our row, the second how many values we want in each row. The -1 simply means:
If there is any situation that you don’t know how many rows you want but are sure of the number of columns, then you can specify this with a -1. ( Note that you can extend this to tensors with more dimensions. Only one of the axis value can be -1 ).
(taken from: python - What does `view()` do in PyTorch? - Stack Overflow)
Q from the CrossValidation nb: after we create a dataset dsrc we find that dsrc.nsubsets are 3.
What are they?
I thought train, valid and test but I can only see dsrc.train and dsrc.valid through the show_at command.