@leaf I guarantee you it is working, I ran it earlier that day, exactly as the notebook is detailed. I run through each that day to ensure everything is working top-down. It’s set up exactly how I did do it, not a would
What issues are you having? At which part of the code? That can help us figure out what’s going wrong and narrow it down
Comments like this are extremely unhelpful to everyone, including you, and to the people who are volunteering their time to build things you are using.
With the new API change (DataBunch etc) I’ll update the notebooks when the official version update is out as son as I can (along with update the PPT diagrams)
Hi @muellerzr i had a few questions in regards to 02_MNIST.ipynb:
1)...and nf is equivalent to how many filters we will be using. (Fun fact this always has to be divisible by the size of our image). Does this mean Width and height of the image has to be divisible by nf?
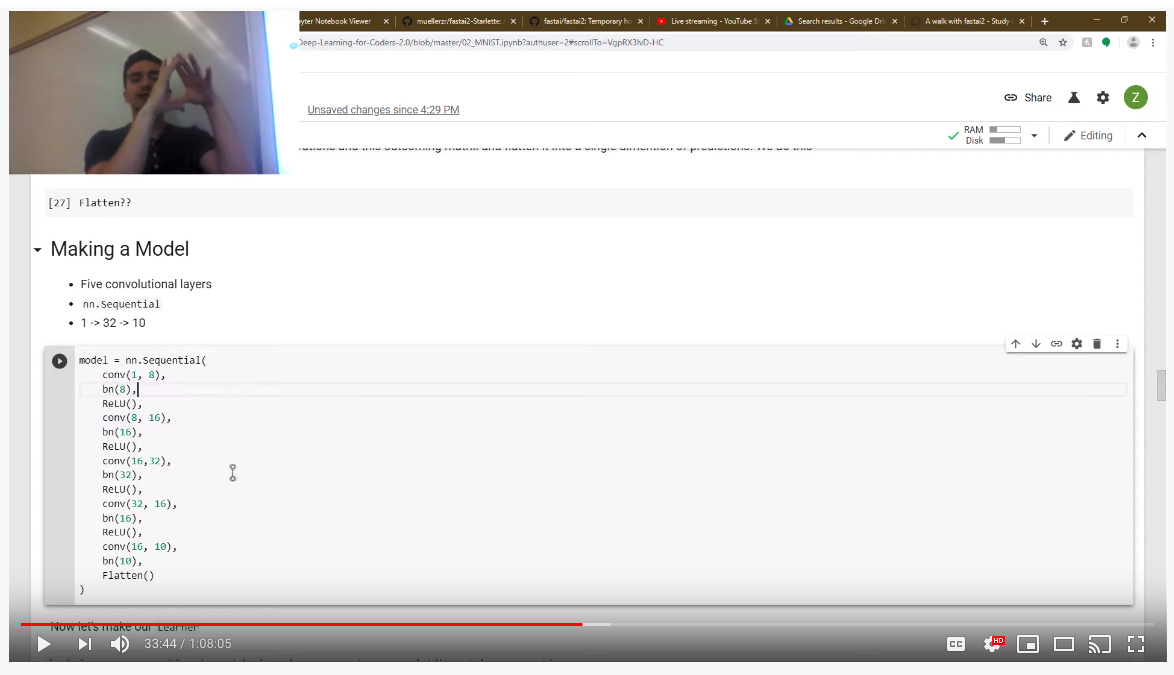
2) The 1,8, 16, 32 passed to the convs are : conv(number_input_filters, number_output_filters) not the size of the kernel. (Kernel size has been set to 3 by default). (at 33:10 in the video)
3)
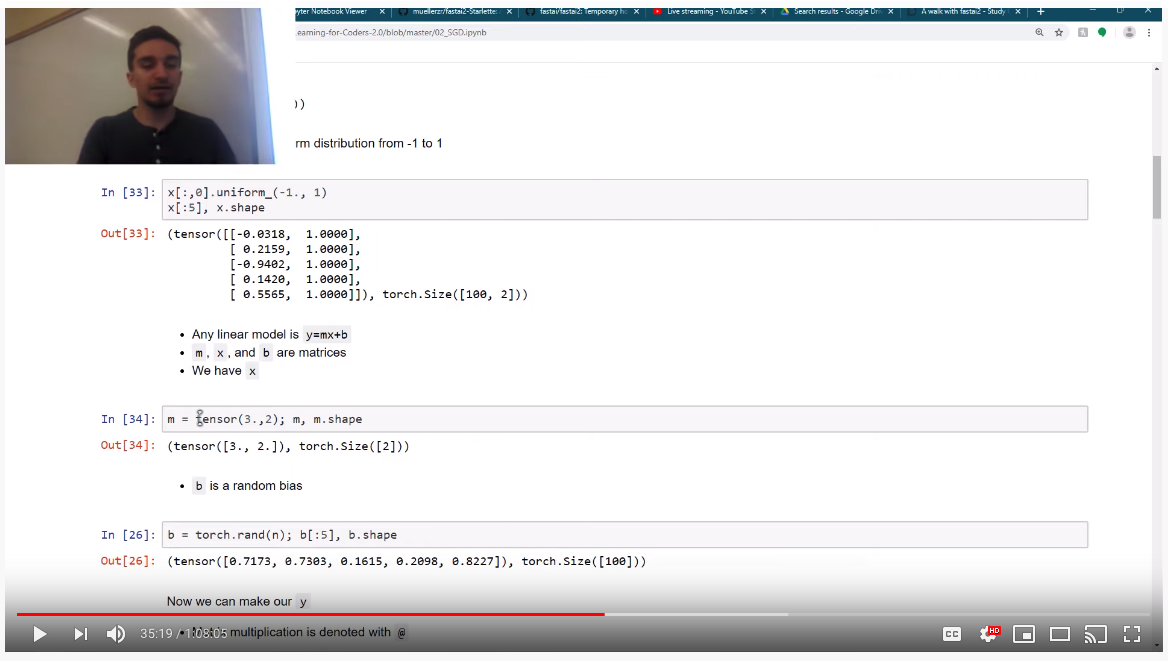
In the SGD notebook, m=tensor(3.,2) this is where b is set to 2. b=torch.rand(n) (this is not really b ?). I thought this random noise was just added so we don’t have a straight line. (Doesn’t really change anything else in the code)
Again a big THANK YOU for the effort you have been putting in creating this series.
I would like to try to help you out with question 1) by recommending you this video from professor Andrew Ng who has a fantastic course. I recommend you watching this video and the next two and then you will totally get it. I started watching in youtube the videos for free and I end up paying in coursera for the full course. I believe it is a fantastic complement to the fastai course from Jeremy Howard and the fantastic tutorials from Zachary Mueller. It is my understanding the W/H image does not have to be divisible by nf so I do not understand the reason behind Fun fact this always has to be divisible by the size of our image. To me this could actually refer to the kernel/filter size (f): formula (H +2p - f)/s + 1
I have not yet had the chance to watch the lecture 2 videos but if I get the chance to day I will try to also look into your other points! Great questions and greetings from Switzerland
My problem is then that I do not understand the difference between item_tfms and batch_tfms. Example: normalizing by imagenet stats should be applied to all images so I do not understand why it is passed in batch_tms. Also, why are we random resizing and cropping (e.g. 460) but then still passing a size to aug_transforms?
The final size of the tensors is torch.Size([32, 3, 224, 224]) so [bs C, H, W]
Imagine that we are doing image classification and you are using images (it can also be tabular, text, audio, ect.) You do following steps:
define the file locations, names and the classes they belong to as lists
load image files and classes lists to memory
use small part (chunks) of the lists for training to gpu or cpu
…
item_tfms are used during step 1 and 2. If your images are in different sizes or very big then you want them to be all same size and may be smaller size… Obviously, for less memory reasons etc.
batch_tms are during step 2 and 3 while your image list size might be terabytes and huge, you want to transform your images to gpu and do augmentation etc. in gpu which is faster.
Image net stats can be allied to both item and batch transforms but gpu is faster and applies to small chunks. In some cases, you may want to apply running stats to you images, therefore you want it to be applied to chunks the applying to whole is impossible.
Because, we usually use available models (resnet, etc.) it’s been trained with millions of images. We use that model as bases and adapt it to our problems. We have lets say 1000 images, which might not be enough to learn properly. As a result, we augment (artificially generate new images ) and random resizing and cropping (e.g. 460) is just one of the many ways to generate new images.
Awesome explanation @s.s.o! I love this remote study group. Where can I find the available data augmentations transforms i.e. the parameters item_tfms and batch_tfms for vision can take? It used to behere for fastai v1 but I cannot find it in the new documentation.
e.g. to do some zero or reflection padding
@mgloria thank you for this it left a bad taste in my mouth when I said and wrote that and couldn’t understand why. That would do it. (MNIST is one of the harder lessons for me as I’m still trying to get through understanding that myself as best as I can!) I’ll update that notebook
@s.s.o is exactly right. Anything that we can push to the GPU (usually anything that involves some form of multiplication, etc) we should. You’re spot on with that
Just to add what really helped me understand this was(from my understanding, please correct me otherwise):
if you want to process things on the GPU(batch_tfms) you need a batch, if you have a batch that means you need a tensor and if you have a tensor that means that all of the items in the batch have to have the same shape.
the things that you probably want to do on the cpu(item_tfms) are( at least for vision):
1)load the image in some way
2)make sure they are the same size(by resizing).
3)then convert them into a tensor
Now we can use the GPU to process things in batches which is going to be really fast
Explained perfectly! I think I’ll sum up what you three have said and add it into the lesson 1 notebook (and the slides) if that is alright @barnacl, @mgloria, and @s.s.o?
I’ve updated the notebooks, along with the slides. I also just added in another slide detailing GPU vs CPU transforms, and the PPT is also a PDF for easy viewing from your browser. Let me know if there are any issues
I am looking into image transforms as documented here. One of the coolest transforms is warping and, as an example, I wanted to try it out. It seems to me, there are two ways of using it, as a method and as a class (please correct me if I am wrong). I tried with success using it as a method but in order to customize (e.g. p or magnitude) it seems to me I need to use the class, again correct me.
Despite having set p = 1., it looks to me it is doing nothing… any insights?



 The fastai library is so good that I believe the hardest part is feeding one’s own data in.
The fastai library is so good that I believe the hardest part is feeding one’s own data in. and correct it if needed.
and correct it if needed.
