If you use the raw weights and setup the model the exact same way yes, but most of the time learn.save() keeps the optimizer state to in which case the answer would be no.
@muellerzr kindly help me out when you are free.
Thanks
Just so everyone knows it’s a thing here’s the link to part 3, Text which will begin tonight:
1 Like
Anyone know if you’re able to get the index values of a TabularPandas object? Doesn’t seem like you can do the usual .index like you would on a DataFrame.
Edit: And I think I just answered my own question. Doing .items give you a Pandas DataFrame version of our TabularPandas object, which you can then call .index. There probably should be an index attribute attached by default so you don’t have to do this.
1 Like
Is there a general rule of thumb when choosing how many unique categorical values you should have per column? I have a dataset with many categorical features that each range from having 10 to several hundred unique values and I’m obviously trying to cut down on the latter size. I have around 19k rows in this dataset.
Some approaches I’m taking for “cutting down” the amount of unique values per column is:
- Creating new labels that group others together
- Re-labeling examples that don’t occur very often simply as “other”
- Dropping rows completely if they have multiple “rare” values for several columns
I’m not sure which/if any of these methods are useful, though I have a feeling that having a couple hundred unique values per column certainly isn’t helping my model accuracy…
Hello everyone, I’ve just gotten started watching the lectures. I’m trying to run the 02_Regression_and_Permutation_Importance notebook in Google Colab. I kept everything as is. However, I get the following error. Anyone know what is going on?
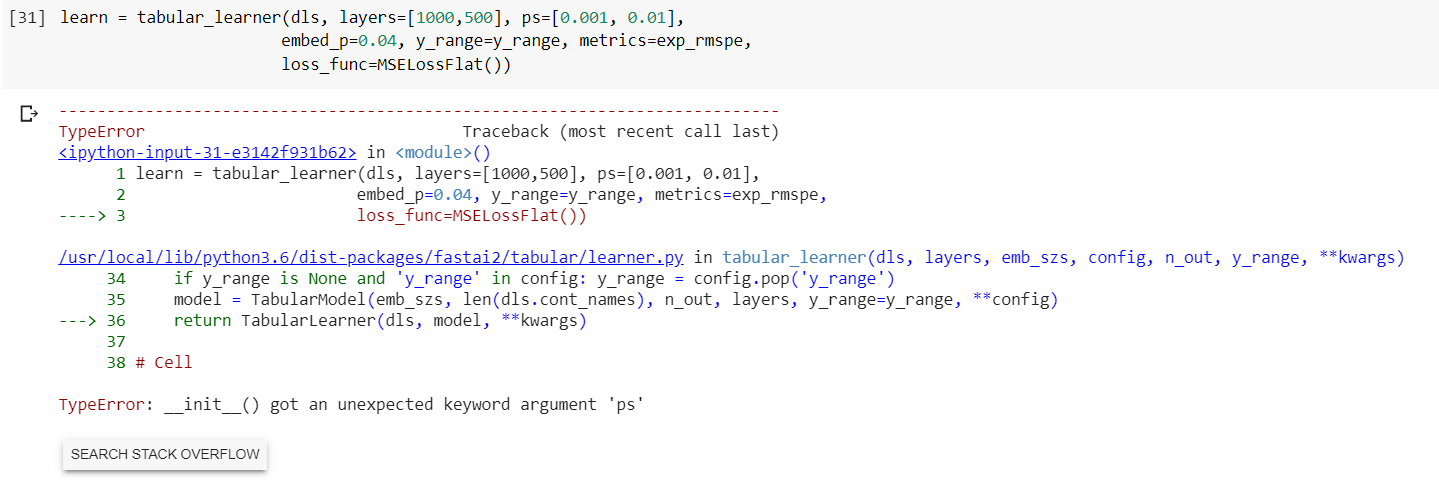
1 Like
Yes I need to update that notebook as those should go into a tabular_config 
You can do it like that :
config=tabular_config(ps=[0.001,0.01], embed_p=0.04)
learn = tabular_learner(dls, layers=[1000,500], config=config, y_range=y_range, metrics=rmse, loss_func=MSELossFlat())
Hi! Thank you for this amazing study group!
Does anybody know how to define which is the positive class in a CategoryBlock? I am getting an encoding where 0 is the positive class, which is a bit against of the standard of binary classification.
Thanks!
Thanks Mueller for the amazing videos. Can someone post their work on tabular datasets. We can get more examples and more datasets. Please share your work on tabular datasets
Is it possible to get the encoded data from a dls.test_dl? I’m trying to load and process a test dataset and then get the encoded values for all the columns so I can use that data in non-fastai models (XGBoost, RF, etc.).
When I originally create my DataLoader for training, I can call to.train.xs since I used TabularPandas to feed in my original training set into my DataLoader. Is there a way I can access the transforms, apply them, and view the applied results from a dls.test_dl?
Just call dl.xs I believe (since it shouldn’t have a train or valid separation)
dl.xs just shows the non-encoded, original values. On an unrelated note, only per index and not the entire dataset.
After making the dl call dl.process(). That should encode them all
(Also dl.dataset for the dataset)
There is no .process() for a DataLoader generated from your ‘original’ dl used in training (as in a dl created from calling dls.test_dl). You can do that for your training dl though. Even after calling .process() and then creating a new .test_dl using my test data, the dataset is still unencoded (which makes sense, but I just wanted to mention that).
fastai2 version: 0.0.17
fastcore version: 0.1.17
Hi!
Do any of these notebooks contain an example of regression with multiple dependent variables? I am not sure exactly how to proceed.
Thanks!
No, I’m afraid they don’t out of the box. TabularPandas doesn’t like that very much. My best recommendation would be using a NumPy DataLoader for tabular instead and working with it. See my article here @vrodriguezf https://muellerzr.github.io/fastblog/2020/04/22/TabularNumpy.html
Thank you, I’ll have a look! However, I am a bit confused. I just created a TabularDataLoaders with a list of two variables as y_names, and y_block=RegressionBlock(), and things seem to be working with MSE as loss function.
I did not even need to adjuts the n_out argument of RegressionBlock, which I was thinking at the beginning that could be used to define the number of output activations that you wanted in the regression.
You found the one exception ![]() if it’s two regressions it will work. However classification with regression or two classifications it will not
if it’s two regressions it will work. However classification with regression or two classifications it will not
1 Like
Oh, I understand! how lucky I am
One extra question: I am not sure if I remember correctly, but: did fastai1 provide a way to automatically log transform the dependent variables? Is that provided as a ready-to-use Procs in fastai2?
EDIT: Sorry I just saw that Jeremy does it manually in one of the fastai2 lessons