Because we don’t actually have that ability with the softmax layer, everything is 0-.99. Otherwise we certainly could if we just grabbed the raw outputs. Just this is a much faster way 
1 Like
Sorry, I’m confused. Doesn’t the multi label classifier determine whether or not an answer is confident via the softmax numbers aka the confidence in percent from 0. to .99? Why would I need the raw outputs? Also, can you add sparsifying/pruning models to the course? I think it’s important for people looking to speed up their predictions and save space when using models on restricting devices (raspberry pi for example)
1 Like
I’m saying from the non-multilabel (just using a regular single label classification). To answer the outputs question, when I go test the DataBlock I’ll go look at what the multi-label’s raw outputs are (as I don’t know!)
I don’t have experience here, so that’s a no there’s been a little discussion about pruning fastai models here on the forums that I know of. Let me try to find the link
Edit: found it @mschmit5 Quantisation and Pruning Research with Fast.ai
@mschmit5 Just to add to what Zachary said. we use different loss functions.
Cross entropy loss is used for the single label case. Softmax is the activation for the single label case. Softmax is great when you have exactly one (no more than one and definitely at least one) of the classes. Applying softmax here is just rescaling the raw output to 0-1 range. So you could in fact avoid softmax and make a prediction - ie the class of the highest raw output.
In the multilabel case the loss is binary cross entropy. You are checking for each class whether it is present or not based on a threshold. So i don’t think raw scores can be used here. You will need to convert it to the 0-1 range and then use the threshold.
2 Likes
Sure, will try.
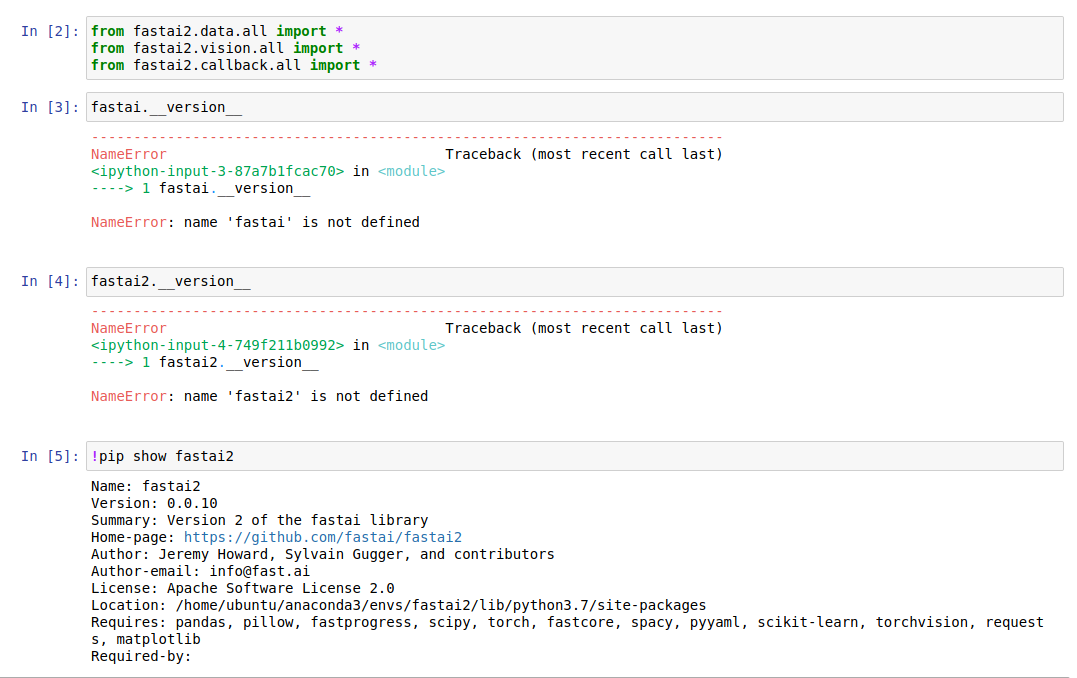
How do you check the fastai2 version? Trying fastai2.__version__ or fastai.__version__ gives me an error.
import fastai2
fastai2.__version__
Are you still getting the error?
I won’t be able to look at it for a few hours @akschougule but try running the examples for multi label here: https://github.com/fastai/fastai2/blob/master/nbs/50_datablock_examples.ipynb
1 Like
Well this works
import fastai2
fastai2.__version__
but I get the same error at dls = planet.dataloaders(df)
Code with reproduced error here
fyi
- I am creating a slink (ln -s) to fastai2 in my project dir.
- local machine Ubuntu 18.04
- upgraded to fastai2 yesterday evening
update: Now we know something new. Ran the datablock notebook and found CategoryBlock, ImageBlock(cls=PILMask), PointBlock works fine but MultiCategoryBlock breaks.
!pip show fastai2 works too. you can see the version below in the output cell. you are 0.0.10 too.
Very strange that it works for me.
Are you using collab? (i am on collab)
A very basic question on the style xfr nb.
What is/are vgg19.features - are they activations? (I assume but is that correct?).
Also typically for attributes/methods etc I can typically do vgg. and the nb provides options for completion.
In this case features does not come up - so what is features in a python sense - attribute of the model, method of it?
Do all models have .features or is this true only of vgg models?
i think those are the layer group names.
We usually have a feature extractor(the body) and a classifier(the head).
Here if you print vgg out you’ll see : feature, avgpool and classification.
I don’t think it is a python thing. i think they jsut named it like that.
vgg19.features - are the layers in the feature extractor, since we got a pretrained network it has the pretrained weights. Activations are the output ie when the input is multiplied with these pretrained weights.
All models don’t have them but we do something similar by indexing into it ie m[0]
We seem to be grabbing only specific ReLU layers from the Vgg16 and Vgg19 models. I have not yet read the relevant paper but is there a reason why these specific ReLU layers are being looked at. There are other ReLU layers in the model. If it is just go read the paper and u will understand that is fine too.
the video lecture will be a good starting point too.
style transfer (starts ~59:14)
not yet found out why the last numbers are there in the config ‘20’ and ‘22’ for vgg16 and vgg19 respectively.
def get_stl_fs(fs): return fs[:-1] seems to remove them. Let us know if you figure out why
Thanks. I think features is the name of the layer group and by doing vgg19(pretrained=True).features.cuda().eval() you transfer all the layers in the feature group on to cuda and eval() them. That is what makes sense to me. Yes, we can grab a particular layer by indexing into the model like m[0] but that is grabbing one layer - here we seem to grab all the layers in the layer group called features - So by grabbing layer group name it seems you can grab all the layers in the layer group…hmm…interesting.
i agree since it is the feature extractor part of the network.
.eval() is turning the model from default ‘train’ mode to eval mode. There is a good discussion above regarding this.
Depending how the structure is - m[0] is usually a layer group, m[0][0] - is a layer. This depends on how things are wrapped in a list.
Layer group is what i think it is called i could be wrong about that. Layer groups is what we use while we do discriminative lrs, how we split the model into three parts.
You could do :
vgg_=list(vgg.children())
vgg_[0][:5]