What is the default activation function for the fully connected layers in the ColumnarModelData.from_data_frame model?
The model summary output indicates these are just linear layers. Is this correct?
What is the default activation function for the fully connected layers in the ColumnarModelData.from_data_frame model?
The model summary output indicates these are just linear layers. Is this correct?
@ramesh
For now, I found a workaround by manually converting the .txt file into an ASCII encoded .txt file.
I wanted to check different configurations before submitting but as we say in French: “better is the enemy of good” 
In my setting, this works:
export PYTHONIOENCODING=UTF-8
apt-get -qq update && apt-get -qqy install locales
sed -i -e ‘s/# ru_RU.UTF-8 UTF-8/ru_RU.UTF-8 UTF-8/’ /etc/locale.gen &&
sed -i -e ‘s/# en_US.UTF-8 UTF-8/en_US.UTF-8 UTF-8/’ /etc/locale.gen &&
locale-gen &&
update-locale LANG=ru_RU.UTF-8 &&
echo “LANGUAGE=ru_RU.UTF-8” >> /etc/default/locale &&
echo “LC_ALL=ru_RU.UTF-8” >> /etc/default/locale
AttributeError Traceback (most recent call last)
in ()
----> 1 learner.fit(3e-3, 1, wds=1e-6, cycle_len=20, cycle_save_name=‘adam3_20’)
~/workspace/fastai/courses/dl1/fastai/learner.py in fit(self, lrs, n_cycle, wds, **kwargs)
190 self.sched = None
191 layer_opt = self.get_layer_opt(lrs, wds)
–> 192 self.fit_gen(self.model, self.data, layer_opt, n_cycle, **kwargs)
193
194 def lr_find(self, start_lr=1e-5, end_lr=10, wds=None):
~/workspace/fastai/courses/dl1/fastai/learner.py in fit_gen(self, model, data, layer_opt, n_cycle, cycle_len, cycle_mult, cycle_save_name, metrics, callbacks, use_wd_sched, **kwargs)
137 n_epoch = sum_geom(cycle_len if cycle_len else 1, cycle_mult, n_cycle)
138 fit(model, data, n_epoch, layer_opt.opt, self.crit,
–> 139 metrics=metrics, callbacks=callbacks, reg_fn=self.reg_fn, clip=self.clip, **kwargs)
140
141 def get_layer_groups(self): return self.models.get_layer_groups()
~/workspace/fastai/courses/dl1/fastai/model.py in fit(model, data, epochs, opt, crit, metrics, callbacks, **kwargs)
82 for (*x,y) in t:
83 batch_num += 1
—> 84 for cb in callbacks: cb.on_batch_begin()
85 loss = stepper.step(V(x),V(y))
86 avg_loss = avg_loss * avg_mom + loss * (1-avg_mom)
AttributeError: ‘CosAnneal’ object has no attribute ‘on_batch_begin’
That’s odd. Can you git pull, restart jupyter, and try again?
Since lecture 4 I’ve struggled with a never-ending training of IMDB notebook. Fortunately, I got some pre-trained weights (thanks to @Moody and @wgpubs) thus I thought of creating this post to allow fellow students to explore the notebook since many of us have skipped it because of training time.
You can access the post at: Running IMDB notebook under 10 minutes
@Elfayoumi on_batch_begin() is part of new code. You might have done a git pull while your notebook was still loaded in memory. The notebook is executing well at my end. As Jeremy mentioned, git pull and restart notebook.
I’ve updated the IMDB file.
Updated file has information about object types, model structure, calculation/logic (for those with less knowledge about Pytorch and/or numpy), split etc.
@jeremy/all,
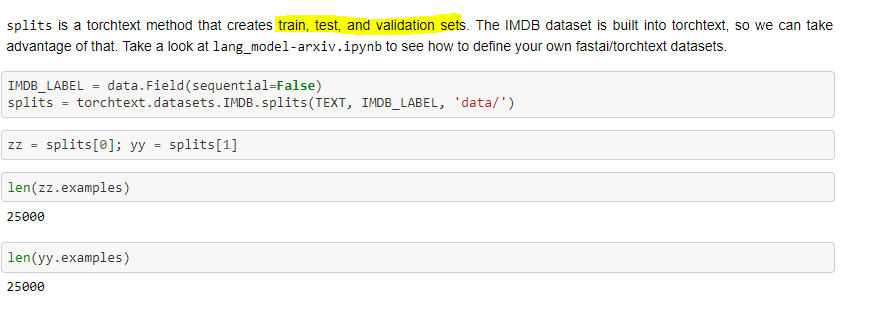
torch by default gives 2 splits (of 25k items each) for IMDB dataset. My assumption is that one is train and other is test set? If so, can I say validation set is part of the train itself? If so, what’s the ratio?
Test set - 25k used here?
![]()
We aren’t explicitely specifying validation items anywhere.

Looks like there is no validation in this split:
@yinterian - Would you be able to share insight on why Pytorch doesn’t include content for validation?
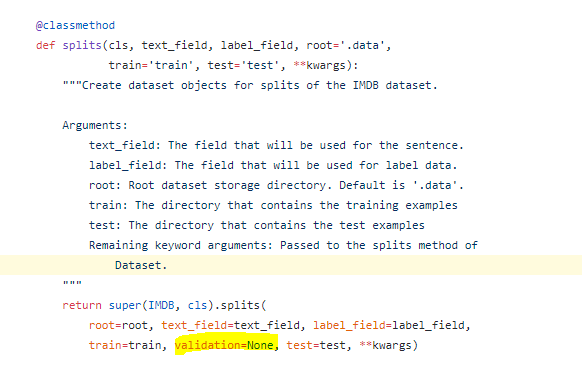
Source - https://github.com/pytorch/text/blob/master/torchtext/datasets/imdb.py
You can use part of your training for validation or use cross-validation.
Without validation, our model gave results better than state of the art per lecture 4. It’ll be interesting to try and see if validation improves the performance.
The way you would do this is by using part of the train set as validation. You can potentially at the end join train and validation for your final model. Validation sets are used to find the best hyper-parameters without looking at test score. In this case we are using the test set as a validation set.
Wouldn’t that imply our model has already seen the test records? If so, our predictions on same test data may not represent (accuracy/score/etc.) what we’ll get if we test on unseen data?
Edit:
I may be inferring wrong code but below split says there is no validation.

We can pass in the Validation as a parameter?
Yup! @ecdrid, how do you infer Yinterian’s last reply on this thread? Also, the default splits seem not be using validation at all.
I guess the question has evolved from ‘how to add’ to ‘why not’?
@vikbehal
I might not be correct with this one,but giving it a shot…(I cannot try because having endsems ending on next week)
What we can do is get some random rows from the dataset, create a new data frame and thus a new CSV file from the training set…
Or,
Passing the test set itself as the validation one…
validation=test
And after that for the final round,
Just train your whole model on the training one plus the test set for the last tweak to hyperparameters by joining them/concating…
It’s like when Jeremy said that before submitting, he trained the whole model on all the data that’s available…
Can someone confirm?
Many academic datasets only contain a train and a test, no separate validation. In these cases, researchers often treat the test set as if it were a validation set - although obviously that’s far from ideal!
Thank you for clarifying. I was creating a split for one of the ongoing problem. For this I was referring to:
After exploration, it seems both files use labelled data even for the test set. Is my understanding correct?
Yes exactly. Kaggle comps are a bit unusual - in practice you’ll always have labels for your test set, you should just avoid using them, until right at the end of your project!
So, I was using similar approach to IMDb or arxiv to create splits. The constructor is gonna label items in test folder as well - due to the loop which goes through labels and add label and text to property to all of the examples.
What I’ve tried so far is putting all items from test in a folder say ‘all’, doing so will assign a dummy label to test data. So my split will get items but for some reason I get 4 probabilities instead of 3 in the predict. Such probabilities doesn’t add to 1.
To keep test examples without label, Should I be extending constructor to check if it’s test folder, if so, just add text and not label property?
@jeremy, could you please advise?