I guess my point is that I don’t understand how you would train the embedding value. They start off being initialised with some arbitrary value (random or otherwise) and then I would expect SGD to correct the errors, but I believe that potentially a lot of the training adjustments will go into the weights of your dense layer which won’t help you when you’re using the values later.
All this being said, if you find something useful then I’ll be very interested to hear about it
This sounds really interesting. Looking forward to seeing what you find.
Interestingly, somethings having embeddings that are larger than the cardinality of the original variable actually help predictions. So perhaps binary embeddings could be useful there too…
Is the maximum cardinality of the embedding matrix a learnable concept? The heuristic of max(card//2, 50) was reached due to some research and whether the cardinality of the categorical variable is low enough, but is there another way to decide on the maximum that also takes into account the diminishing usefulness of very large cardinalities? [Edited to add more detail to the question]
Just to clarify: I think you mean “largest embedding size”, not “maximum cardinality of the embedding matrix”. A categorical variable has a cardinality, an embedding matrix doesn’t - although the number of rows in the embedding matrix is equal to the cardinality of the categorical variable it is used with, I think above you’re referring to the number of columns in the embedding matrix.
Assuming I’ve understood correctly, then yes, it’s certainly worth trying larger embeddings. For words, for instance, researchers have found up to 600 dimensional embeddings to be useful. It depends on how complex the underlying concept is, which you can’t know (AFAIK) without trying different embedding sizes.
The max of 50 is just a rule of thumb that’s worked for me so far.
Ok thanks for your answer @anurag , that’s good news (unless it is location related) ,
I will do some more tries next days and if issue continues I will give you more details.
I hope I will be able to make it work cause Crestle seems to me a very well conceived tool, amazing local-setup independent portability and such a clear interface…!
Eventually, through embedding, we are creating bunch of numbers which represent categorical variables. Dropout happen during embedding creation which isn’t required for continuous variables.
Next, once we’ve all of these numbers which fed into neural network, the dropout can be applied at each such layer (to avoid overfitting).
(sorry for the delay, things got a bit hectic around here)
Video timelines for Lesson 4
00:00:04 More cool guides & posts made by Fast.ai classmates
"Improving the way we work with learning rate", “Cyclical Learning Rate technique”,
“Exploring Stochastic Gradient Descent with Restarts (SGDR)”, “Transfer Learning using differential learning rates”, “Getting Computers to see better than Humans”
00:03:04 Where we go from here: Lesson 3 -> 4 -> 5
Structured Data Deep Learning, Natural Language Processing (NLP), Recommendation Systems
00:05:04 Dropout discussion with “Dog_Breeds”,
looking at a sequential model’s layers with ‘learn’, Linear activation, ReLu, LogSoftmax
00:18:04 Question: “What kind of ‘p’ to use for Dropout as default”, overfitting, underfitting, ‘xtra_fc=’
00:23:45 Question: “Why monitor the Loss / LogLoss vs Accuracy”
00:25:04 Looking at Structured and Time Series data with Rossmann Kaggle competition, categorical & continuous variables, ‘.astype(‘category’)’
00:35:50 fastai library ‘proc_df()’, ‘yl = np.log(y)’, missing values, ‘train_ratio’, ‘val_idx’. “How (and why) to create a good validation set” post by Rachel
00:50:40 Dealing with categorical variables
like ‘day-of-week’ (Rossmann cont.), embedding matrices, ‘cat_sz’, ‘emb_szs’, Pinterest, Instacart
01:07:10 Improving Date fields with ‘add_datepart’, and final results & questions on Rossmann, step-by-step summary of Jeremy’s approach
Pause
01:20:10 More discussion on using Fast.ai library for Structured Data.
01:23:30 Intro to Natural Language Processing (NLP)
notebook ‘lang_model-arxiv.ipynb’
01:31:15 Creating a Language Model with IMDB dataset
notebook ‘lesson4-imdb.ipynb’
01:39:30 Tokenize: splitting a sentence into an array of tokens
01:43:45 Build a vocabulary ‘TEXT.vocab’ with ‘dill/pickle’; ‘next(iter(md.trn_dl))’
The rest of the video covers the ins and outs of the notebook ‘lesson4-imdb’, don’t forget to use 'J’
and ‘L’ for 10 sec backward/forward on YouTube videos.
02:11:30 Intro to Lesson 5: Collaborative Filtering with Movielens
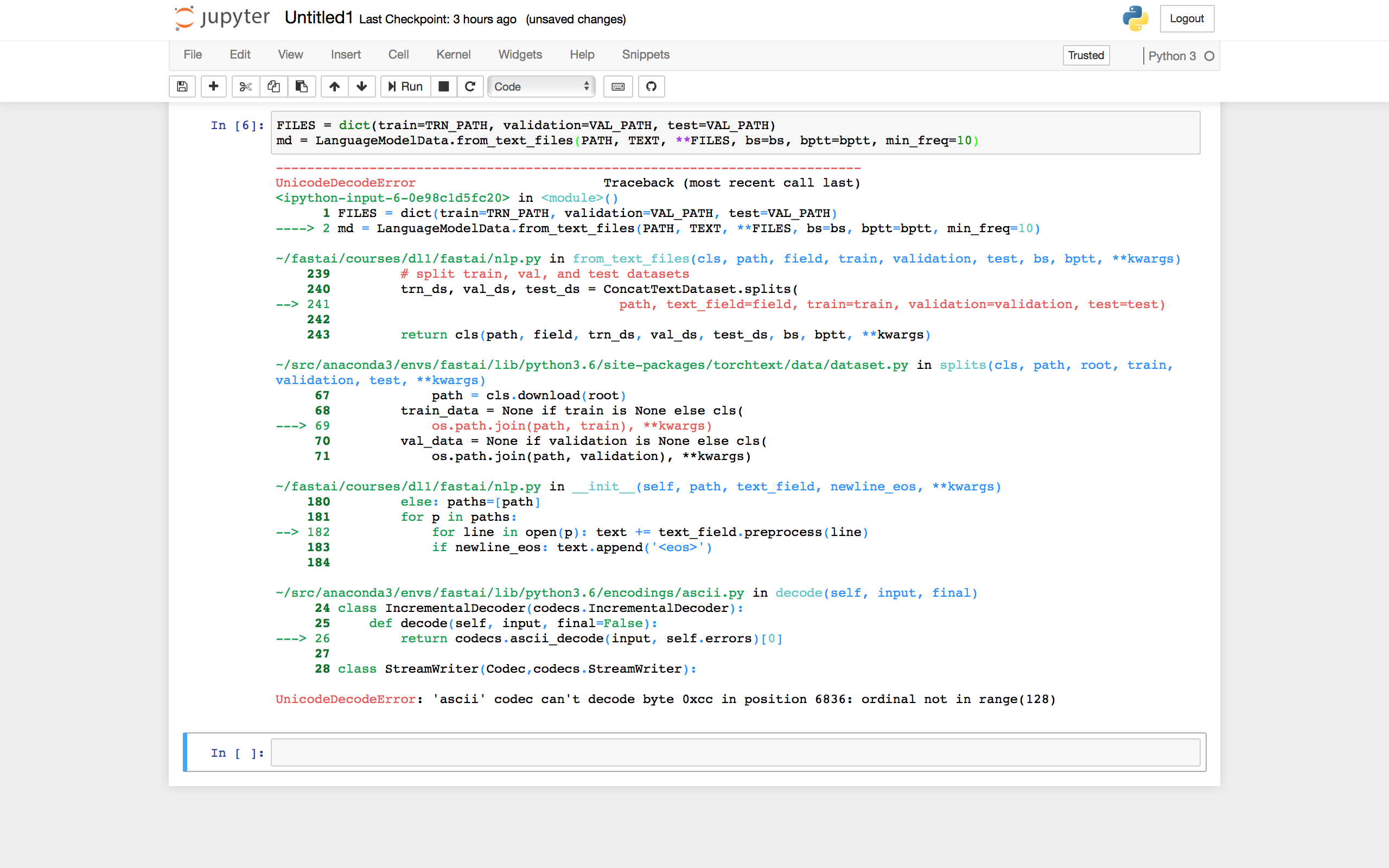
I’m trying to use the create a language model with a custom dataset.
I’ve loaded a .csv dataset in and saved it to a .txt file after performing operations on it as a pandas data frame.
Now the LanguageModelData.from_text_files gives the error. ascii' codec can't decode byte 0xcc in position 6836: ordinal not in range(128)
The .txt file displays its encoding as utf-8 according to sublime text.
Also, I’m saving the dataset to a single concatenated .txt file rather than a number of them, since I’m reading from a csv. Will this work or do I have to do something differently?

 )
)