The sklearn API mentions that the data input format to PCA is (n_samples, n_features). My understanding is we have 2000 samples (number of movies) and 50 features (embedding length). The goal here is to reduce the 50 dimension to 3 dimension. Thus we should use the data as is without Transposing.
Am I missing something in terms of definition of feature vs sample here? @jeremy
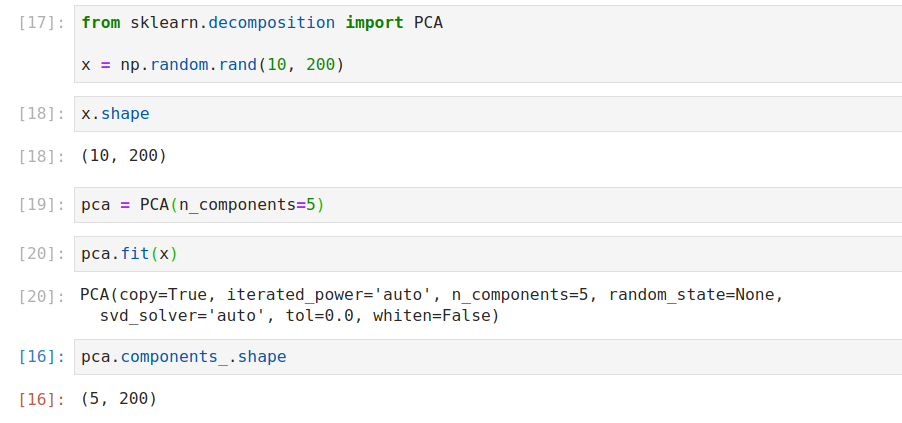
In short answer, the pca.components_ is transposed, thus you need to transpose again to get the correct dimension, it can be verified easily with a simple example. I am not 100 % sure about why the dimension is (m*n), but my guess is this is closely related to the definition of the transformation which you should use the transpose of the component instead of the components_
**components_** : array, shape (n_components, n_features)
Principal axes in feature space, representing the directions of maximum variance in the data. The components are sorted by `explained_variance_` .