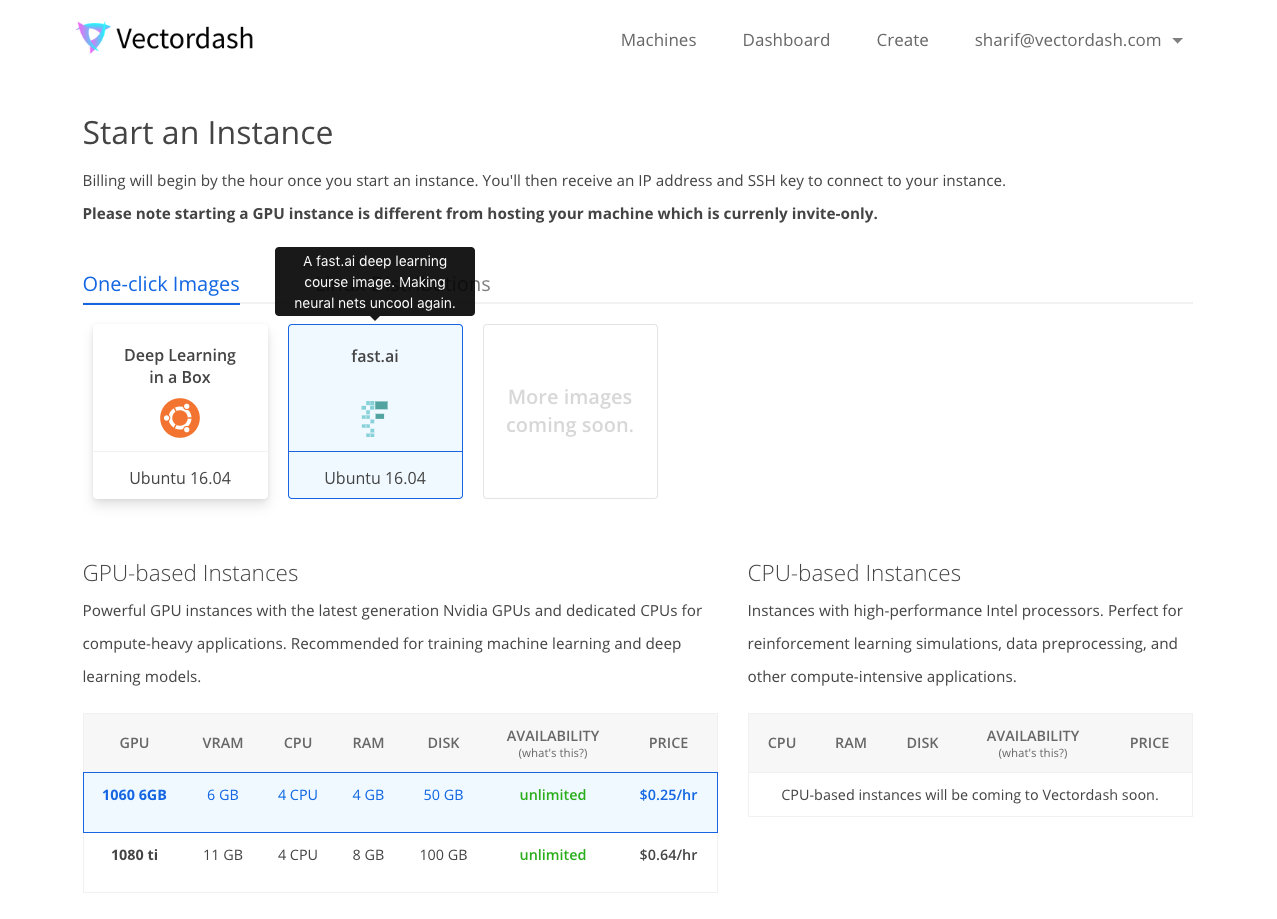
Vectordash now has GPU instances starting at just $0.25/hr and a pre-built fast.ai image. With the vectordash jupyter command, you can start a remote Jupyter server on your instance in just seconds!
If you’re working with larger models, we just added support for multi-GPU instances as well.
Let me know if you guys have any suggestions for Vectordash, I’m all ears!
Can you please share how you implemented this? It would be great if open source so we could also build one for ourselves with our regional/local communities. 0.25$/hour may be cheap in US, but still costly for, say India. Thanks for the great work you have done and doing.
I also have a doubt on the economics part. This is definitely not to discourage anyway, but only to understand to see if its viable to start something like this in our home land as I said, 0.25$/hour seems costly.
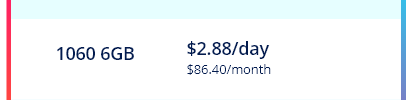
you have mentioned that hosters can earn about 2.88$/day for a 1060 6 GB instance.
This is about twice that hosters earn \frac{6}{2.88} \approx 2. So is it about 50% commission? Is there any reason for it?
W.r.t ROI, different regions of world has widely ranging prices for same hardware. So in USA, 1060 costs about $250 but in India, it costs $375., so a US guy can expect ROI in \frac{250}{(30)(2.88)}\approx 3 months assuming full usage, while an Indian needs \frac{250}{(30)(2.88)}\approx 4 months. I am not sure if this is exaggerated as we go up in GPU complexity. Also this is only considering cost of GPU. If electricity is considered, this might stretch to another month or two. So currently this does not sound very lucrative for hosters. Any insights on this?
I believe that is about the problem on Bitcoin right now and to save the investment on the hardware they needed to adapt it’s company to another public. It’s just a theory but if that so we will see a competitive marketing from now one.
Also if that is true these providers will have lower performance too. The majority of mining rigs if not all need to use PCI-Ex 1x, that is different from a real cloud provider (that uses 8, 10, 12 PCI-Ex 16x) with real server-boards or Nvidia architecture (NVSwitch - 5x more badwidth than PCI Ex 16x).
Some Block Chain / Crypto currencies boards:
Asus B250 Mining Expert (19 GPUs)
ASRock H110 Pro BTC+ (13 GPUs)
Gigabyte GA-H110-D3A (6 GPUs)
Biostar TB250-BTC Pro (12 GPUs)
Also remember that DataCenters aren’t allowed to use GeForce GPUs (Game Boards) to serve IaaS (infrastructure as a service)
The seepd depends on many variables, clearly K80 is faster than GT1060 because has almos 5k cores cuda while GTX 1060 has only 1260 cores cuda.
The RAM memory capacity is a factor that can accelerate the learning process, because how much memory you have more bigger is the batch size you can send to the GPU (K80 has 12Gb RAM, while GTX 1060 has only 6Gb RAM).
(…) Are you saying K80 will not work with pyTorch1.0?
Note : Cuda Capability v3.0 already is depricated and PyTorch and TensorFlow does not support it anymore, unless you built those libraries yourself.
As I mentioned before K80 has API v3.5 still works in TensorFlow and PyTorch 1.0 but is close to deprecation.