Hi Everyone - I am trying to use the Tiramisu architecture for a project and the closer I look at the paper I realize I didn’t quite understand things the first time around.
This is a pretty detailed post but hopefully someone whose spent some time thinking about this architecture won’t mind digging in.
I have 2 questions, that are probably related.
Q1: Transition Up
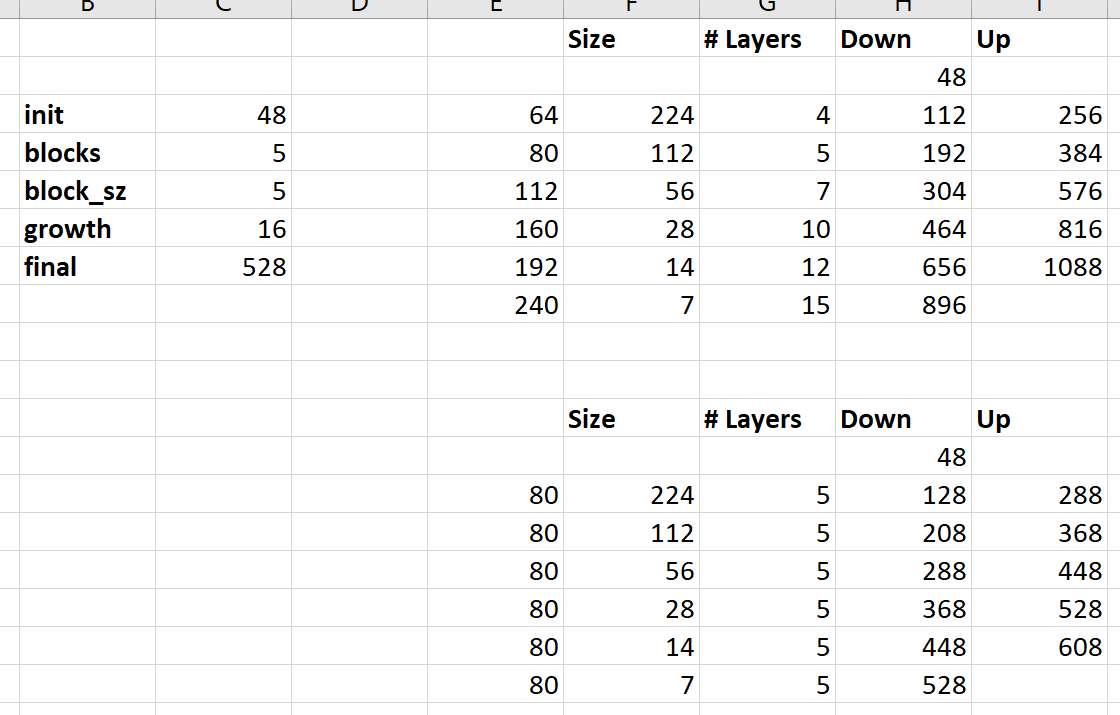
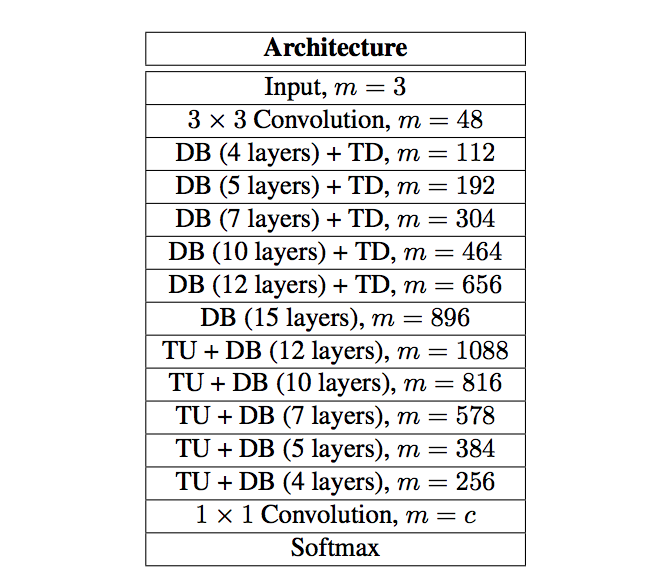
My main confusion lies in the transition-up feature maps. In Table 2 of the paper they explain the architecture layer-by-layer including the number of feature maps at the end of each block.
The down path, “DB+TD”, are easy to understand. If the input to the DB+TD has n features:
- The output of the DB has
growth_rate*(# of layers)features - The output is then concatenated with the input to the DB giving
(n+growth_rate*(# of layers)) - The TD-conv preserves the number of features.
These steps can easily be show to reproduce the DB+TD parts of this table.
However, moving on to the bottleneck. The output of a dense-block (as above) is simply growth_rate*(# of layers) in this case 16*15=240. Note the input to the bottleneck output, 656, plus the output of the dense-block does give 896, however there is not a concat after the bottleneck so it seems it should be 240.
“TU+DB” has the same problem. Since it ends in a DB the outputs should have growth_rate*(# of layers). Maybe they meant “previousDB+TU” or “previousDB+TU+(concat with skip connection)” which would allow us to pick the number of filters in the TU to give the m they list here but i feel like I am missing something.
Q2: Dense Block
I think I found a mistake in an old notebook of Jeremy’s but chances are its my mistake and is wrapped up in my confusion above - actually we both seem to be right depending on what part of the paper you read.
I stated above that the output of the DenseBlock has (k*l) feature-maps where k is the growth rate and l is # of layers. This is because the output of the dense-block is the concatenation of the l layers and each layer contains a conv with “k” filters. The output of the dense-block is then concatenated with the input to the dense-block giving “m + k*l” features. This is clearly illustrated in Figure 2, and described in the caption of Figure 2 (see Fig 1 for the concat).
However in the old version keras-based fastai course Jeremy didn’t concatenate the layers to get the output of the dense-block but rather concatenated the output of the last layer with the input of the last layer. See input 47 of this notebook.
This seems to clearly contradict Figure 2. However the last paragraph of section 3.1 seems to describe what Jeremy has reproduced in his notebook.
Thanks for making it this far!