If I try to map the math formula to the code the ∩ sign is actually a multiplication and |X| is actually taking the sum of the matrice right?
One last question: The author used a “smooth” factor. Why do we want to do that?
Thank you.
The ∩ sign stands for set intersection, and |X| stands for the cardinality of the set X – basically the number of elements in the set.
This coefficient measures the similarity between sets X and Y. If the two sets are identical (i.e. they contain the same elements), the coefficient is equal to 1.0, while if X and Y have no elements in common, it is equal to 0.0. Otherwise it is somewhere in between.
The reason intersection is implemented as a multiplication and the cardinality as sum() is because pred and target are one-hot encoded vectors, i.e. vectors consisting of zeros or ones.
To be fair, since pred is computed using the logistic sigmoid, it could contain values between 0 and 1, although as the model becomes more certain of its predictions those “in between” values should disappear and go towards 0 or 1.
Thanks a lot for this guys! It really helps. I really wonder how I could have known that by myself . Btw any idea about the smooth factor? Why would we want to add it? What is its purpose?
Thanks.
It seems to me that most of the time when we add a term to avoid dividing by zero we choose a small value such as 1e-8 (in order not to modify the original expression too much). Why is smooth equal to 1 and not to a smaller value such as 1e-8?
Thanks.
I think the smooth factor does more than just protect against division by zero (in which case it’s more generally called “epsilon” and only appears in the denominator). I’m no expert on the DICE coefficient but the smooth factor may be used here to literally make the function (or its derivative) more smooth.
Thank you for your reply. It’s not the first time that I hear this put I don’t see how adding +1 in both numerator and denominator makes the function (or its derivative) more smooth. Can someone explain this to me?
@pietz@Ekami
I still don’t understand the smoothing part. How on earth will our denominator ever be zero? Summing our ground truth labels will always be greater than zero. That’s because we have a min of two classes labelled as 1 and 0.
The other possibility is that our numerator becomes zero, which I don’t see as any problem as we are trying to improve it to 1. I hope there is a better explanation to this.
Suppose our arrays contain only 0s and 1s. When we take element-by-element product and then sum we’ll count only intersection of 1s (not 0s). It’s not an intersection of 2 arrays. We also compute cardinality as sum of 1s (not 0s again). Is it what we want?
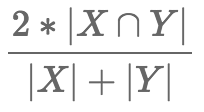
 . Btw any idea about the smooth factor? Why would we want to add it? What is its purpose?
. Btw any idea about the smooth factor? Why would we want to add it? What is its purpose?