On a dog and cat example the output is very easy, if it’s closer to 0 it predicts a cat and if it’s closer to 1, a dog.
If it’s closer to 0.5 it means that the model is confused and has no idea what to predict.
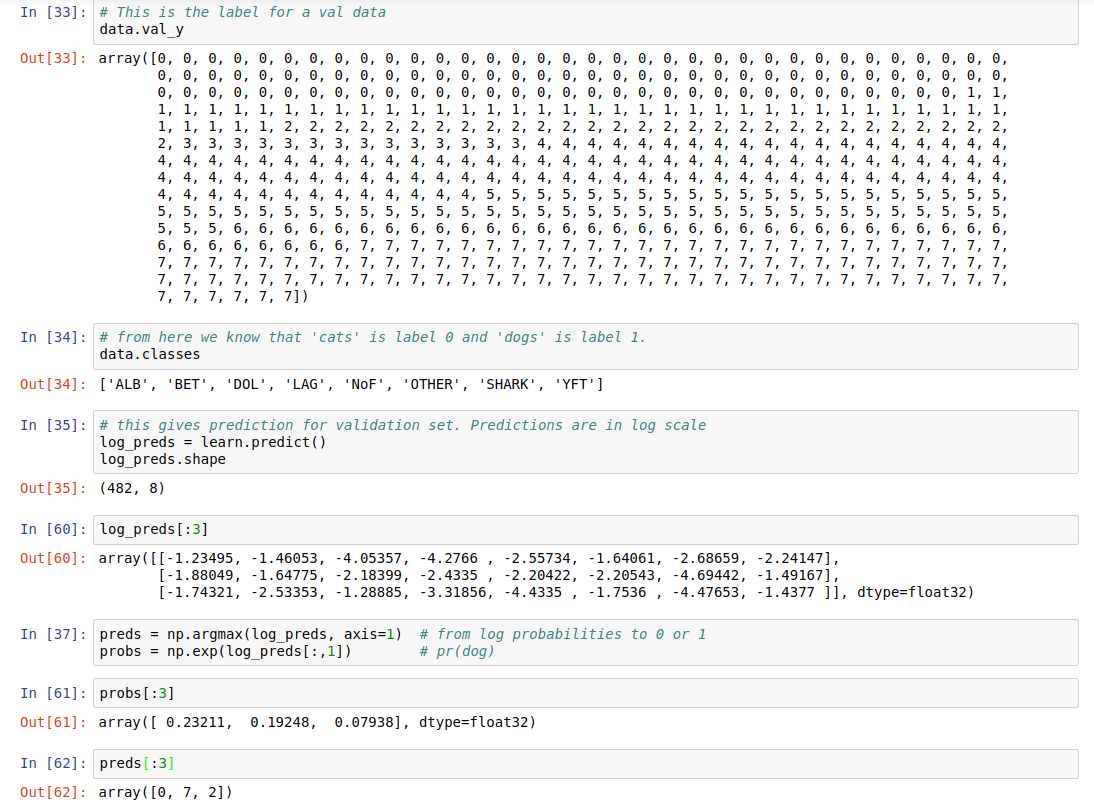
I try to apply the same steps for the fisheries competition (the-nature-conservancy-fisheries-monitoring) where you have 8 classes.
So what I have so far is the following: a log_preds variable (shape: (482, 8)), where each line corresponds to the tested image, and each column corresponds to a score for a certain class.
So for example, line 3 (image 3) has 8 scores - where the maximum value is on column 3 which corresponds to class 2 (because classes are from 0 to 7).
log_preds[:,3]
array([[-1.23495, -1.46053, -4.05357, -4.2766 , -2.55734, -1.64061, -2.68659, -2.24147],
[-1.88049, -1.64775, -2.18399, -2.4335 , -2.20422, -2.20543, -4.69442, -1.49167],
[-1.74321, -2.53353, -1.28885, -3.31856, -4.4335 , -1.7536 , -4.47653, -1.4377 ]], dtype=float32)
Everything is clear until now.
How to interpret the following?
probs = np.exp(log_preds[:,1])
probs[:3]
array([ 0.23211, 0.19248, 0.07938], dtype=float32)
Where probs is a variable which has only one value for each image (instead of 8). The value is between 0 and 1, because it represents a probability.
How do we interpret probs[j] = 0.07 as a probability value which predicts that image j belongs to class j