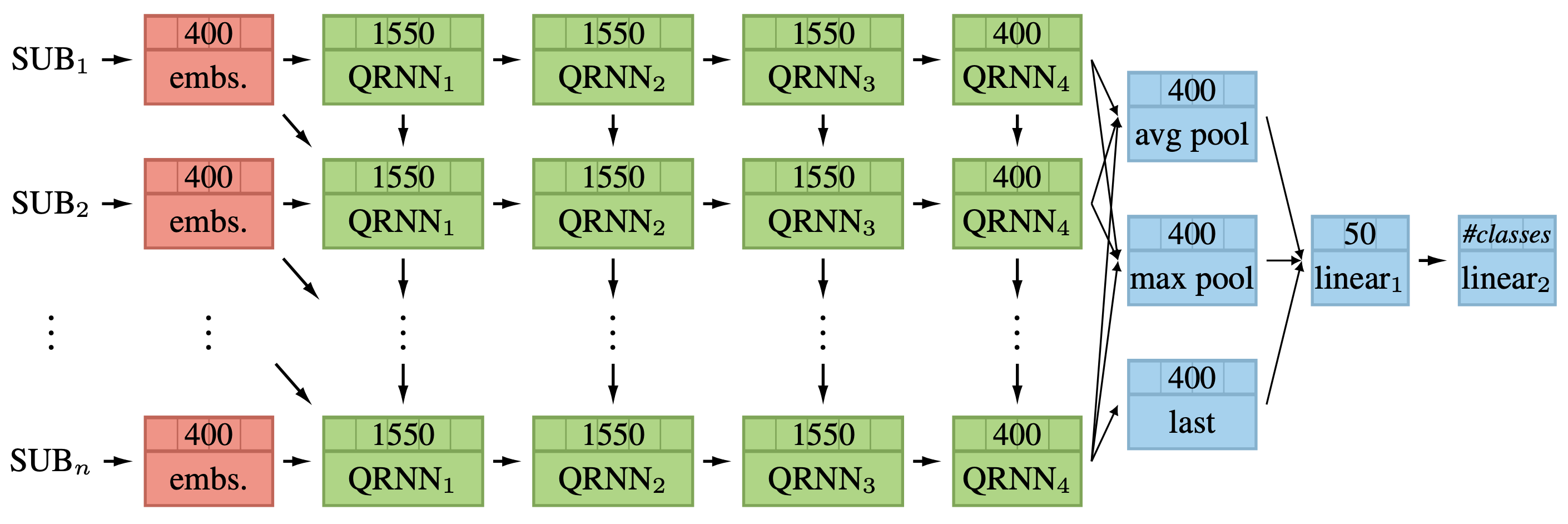
In my understanding, the get_rnn_classifier function in the lm_rnn file:
def get_rnn_classifier(bptt, max_seq, n_class, n_tok, emb_sz, n_hid, n_layers, pad_token, layers, drops, bidir=False,
dropouth=0.3, dropouti=0.5, dropoute=0.1, wdrop=0.5, qrnn=False):
rnn_enc = MultiBatchRNN(bptt, max_seq, n_tok, emb_sz, n_hid, n_layers, pad_token=pad_token, bidir=bidir,
dropouth=dropouth, dropouti=dropouti, dropoute=dropoute, wdrop=wdrop, qrnn=qrnn)
return SequentialRNN(rnn_enc, PoolingLinearClassifier(layers, drops))
returns the SequentialRNN wrapper containing the rnn_enc backbone and the classifier layer.
Similarly, the language model function:
def get_language_model(n_tok, emb_sz, n_hid, n_layers, pad_token,
dropout=0.4, dropouth=0.3, dropouti=0.5, dropoute=0.1, wdrop=0.5, tie_weights=True, qrnn=False, bias=False):
rnn_enc = RNN_Encoder(n_tok, emb_sz, n_hid=n_hid, n_layers=n_layers, pad_token=pad_token,
dropouth=dropouth, dropouti=dropouti, dropoute=dropoute, wdrop=wdrop, qrnn=qrnn)
enc = rnn_enc.encoder if tie_weights else None
return SequentialRNN(rnn_enc, LinearDecoder(n_tok, emb_sz, dropout, tie_encoder=enc, bias=bias))
returns a SequentialRNN wrapper with the rnn_enc and the linear decoder.
Here the linear decoder outputs the probabilities for the next word:
class LinearDecoder(nn.Module):
initrange=0.1
def __init__(self, n_out, n_hid, dropout, tie_encoder=None, bias=False):
super().__init__()
self.decoder = nn.Linear(n_hid, n_out, bias=bias)
self.decoder.weight.data.uniform_(-self.initrange, self.initrange)
self.dropout = LockedDropout(dropout)
if bias: self.decoder.bias.data.zero_()
if tie_encoder: self.decoder.weight = tie_encoder.weight
def forward(self, input):
raw_outputs, outputs = input
output = self.dropout(outputs[-1])
decoded = self.decoder(output.view(output.size(0)*output.size(1), output.size(2)))
result = decoded.view(-1, decoded.size(1))
return result, raw_outputs, outputs
Hence, I guess that if we want to output custom probabilities at each word step, that’s the class to adapt.
Any thougts about this?
 Some code possibly
Some code possibly