Hello everyone! My name is Thomas, I am an independent game developer, currently based in Berlin. I have previously built a game named Kingdom, and am now working on a few smaller projects including a public space (outdoor) game. For an impression of what that is like, this is a game I did previously.
Task
For games like the above, I am currently trying to train a network that would be able to detect hands in (close to) real time from a webcam feed. What I was hoping to do is train the output network to emit high values for regions that contain hands, I will post-process that with a non-maximum suppression / mode-finding to find the actual location.
Data
I have recorded and annotated some data of myself waving my hands around. This data is the source for generating training targets. I have currently opted for a simple blob around the hand center with a radius corresponding to the hand size. I recorded some data with me sitting in front of the webcam, and some data from further away. I am planning to record much more data, but before investing a lot of time in that, I want to have a better grasp of the requirements, so I started experimenting with a quick and dirty dataset first.
Fig 1: Examples of annotated data:

Fig 2: Example of target image with blobs where the hands are:

Approach
To start simple and naively, I took the first two Conv Blocks with weights from VGG16, and added another trainable Conv Block on top of that, finishing with a 1x1 Conv2D layer to collapse all the filter weights into a 2D output image.
== VGG WEIGHTS ==
conv2d_1 (Conv2D) (None, 64, 240, 426)
conv2d_2 (Conv2D) (None, 64, 240, 426)
max_pooling2d_1 (MaxPooling2 (None, 64, 120, 213)
conv2d_3 (Conv2D) (None, 128, 120, 213)
conv2d_4 (Conv2D) (None, 128, 120, 213)
max_pooling2d_2 (MaxPooling2 (None, 128, 60, 106)
== TRAINABLE ==
conv2d_18 (Conv2D) (None, 512, 60, 106)
conv2d_19 (Conv2D) (None, 512, 60, 106)
conv2d_20 (Conv2D) (None, 512, 60, 106)
max_pooling2d_8 (MaxPooling2 (None, 512, 30, 53)
conv2d_21 (Conv2D) (None, 1, 30, 53)
Fig 3: Using this method on the ‘nearby’ dataset, the results are actually decent:
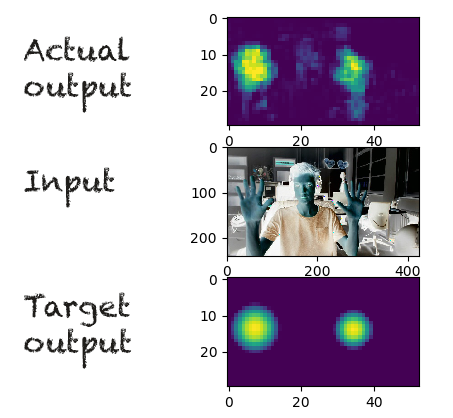
It looks like the network is really marking the hands, and the output would certainly be good enough to localise hands with a proper mode-finding method. I am also excited that this works with relatively few layers, increasing the possibility of running this in real-time.
Question: What is an appropriate loss function?
For the nearby dataset, a significant portion of the pixels in the image consists of hands, but for the ‘faraway’ data, the distribution is actually really skewed. See Fig 2, only a few pixels carry positive values.
What is an appropriate loss function for this skewed distribution of the target data as above? I.e. a black (zero) image with sparse white (positive) areas. Since only a few pixels have positive values, I feel like MSE will encourage the network to generalise and output low values everywhere.
The second part of the question is about “ambiguous” areas. In annotating the data, I have distinguished between “Open and Facing” hands, and “Other hands” (hands that are far away, fists, or other angles, see image below).
Fig 4: “Other Hands”

I do not necessarily need the network to recognise these, but I also do not want to ‘punish’ the network for highlighting them. I suspect that training the network will be easier if the network is allowed to also give (smaller) positive outputs for Other Hands, because they will carry some of the features that also characterise Open Hands (e.g. skin color). In the final network output, I am be satisfied if the Open Hands just light up more brightly. Since I have already distinguished the classes in my dataset, I figured I could somehow tell the optimiser that it doesn’t matter what it outputs for these “Other Hands”, as long as it gets the Open Hands right.

 Though I still like the idea of combining “what” and “where”, by letting VGG immediately output an “objectness” for each pixel (like in this paper:
Though I still like the idea of combining “what” and “where”, by letting VGG immediately output an “objectness” for each pixel (like in this paper: 
 ) Those “Part Affinity Fields” are really smart. Though it might be overkill for my envisioned task, it is probably also a lot more robust. I will think about being pragmatic and employ their solution
) Those “Part Affinity Fields” are really smart. Though it might be overkill for my envisioned task, it is probably also a lot more robust. I will think about being pragmatic and employ their solution  .
. Thanks for your hint regarding a Masked Loss Function. That is exactly the thing I was looking for.
Thanks for your hint regarding a Masked Loss Function. That is exactly the thing I was looking for.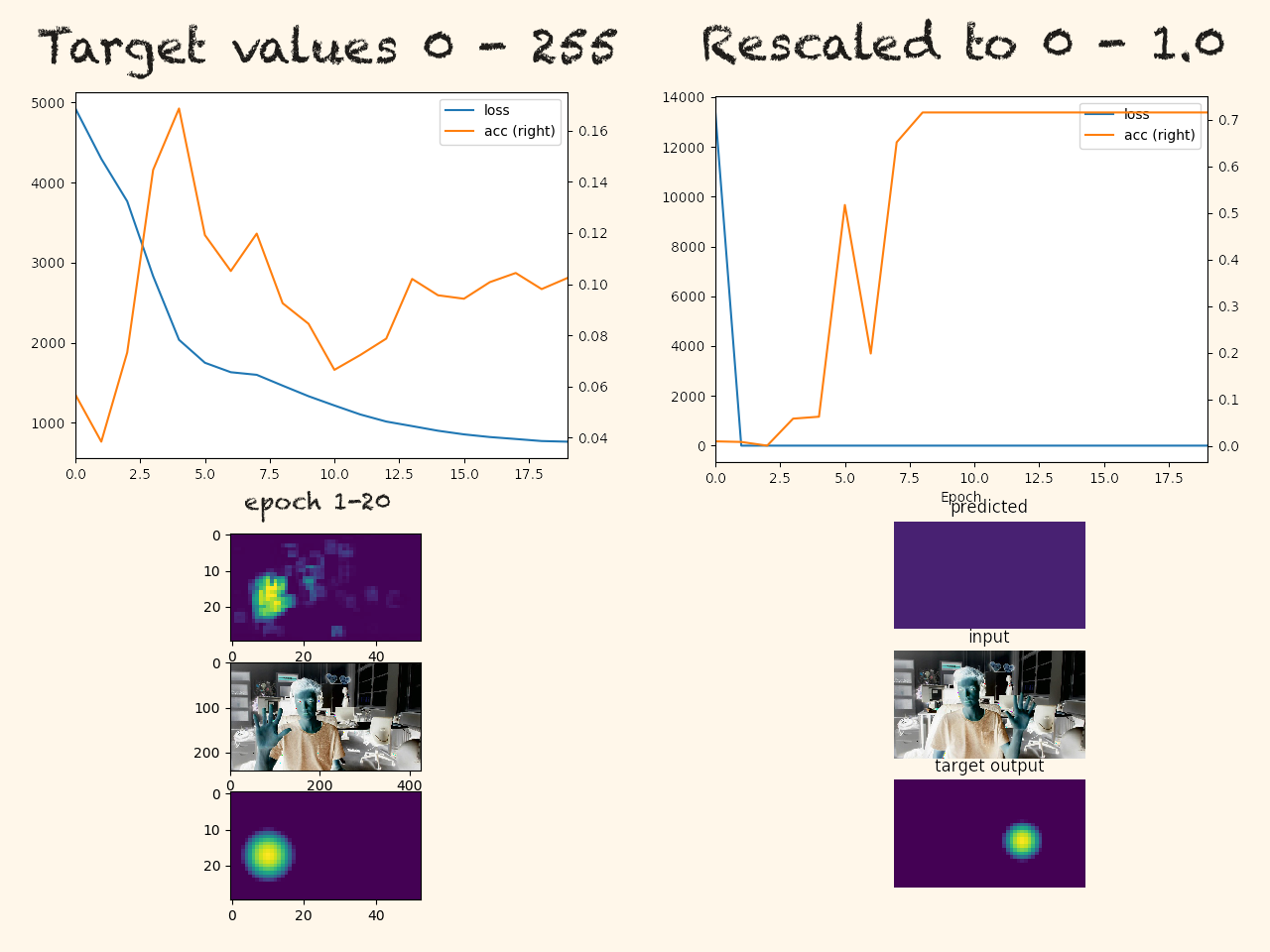




 , so advice very welcome!
, so advice very welcome! 