To help refresh my Python and Jupyter skills in preparation to tackle the remainder of the “Practical Deep Learning for Coder” course work, I coded along with Mr. Howard’s presentation in my own Notebook. Practical Deep Learning for Coders: Lesson 1
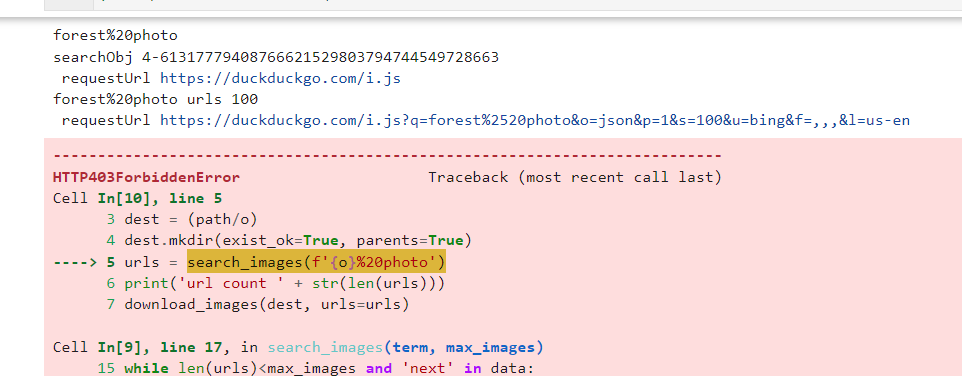
I encounter the error shown in the following screen capture. I see that quite a few people have reported this error but I did not see this direct solution posted elsewhere.
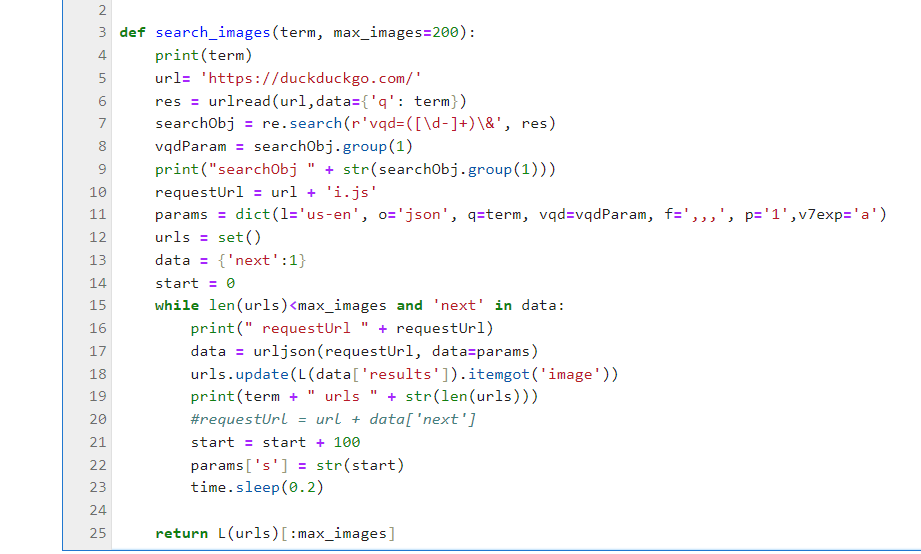
After some print statement debugging in Jupyter Lab, I found that the HTTP request fails in the second loop. And that the problem is an incompatibility between the Request parameters sent as POST data on Line 17 (second screen capture) and the URL parameters appended on line 20 (now commented out). I assume the urljson function cannot handle both or the URL params override the POST data params.
The purpose of line 20 seems to be to increment the “s” or “start” parameter so that each subsequent request starts at higher position to grab the next “page” of results. So, the first loop pulls down results 0-99 and the second 100-199. That way we don’t get duplicate URLs on every loop.
Since the params dictionary defined on line 11 contains the required vqd parameter and the data[‘next’] parameter string does not, it is necessary to keep line 17. Therefore it is necessary to increment the start parameter by 100 on a separate line and update the “s” member of the params dictionary (lines 14, 21, and 22)
After making these changes, the function performed as expected and 200 unique bird and 200 unique forest images were downloaded.
Thanks you for resolving this. I’ve started the course today and the code was giving this error.
As a last note, for your code to work we must import the time library, otherwise it will give us an error because it does not recognize ‘time’ when we call the time.sleep(0.2) function.