Hi guys, do you face the following exception when running lesson1
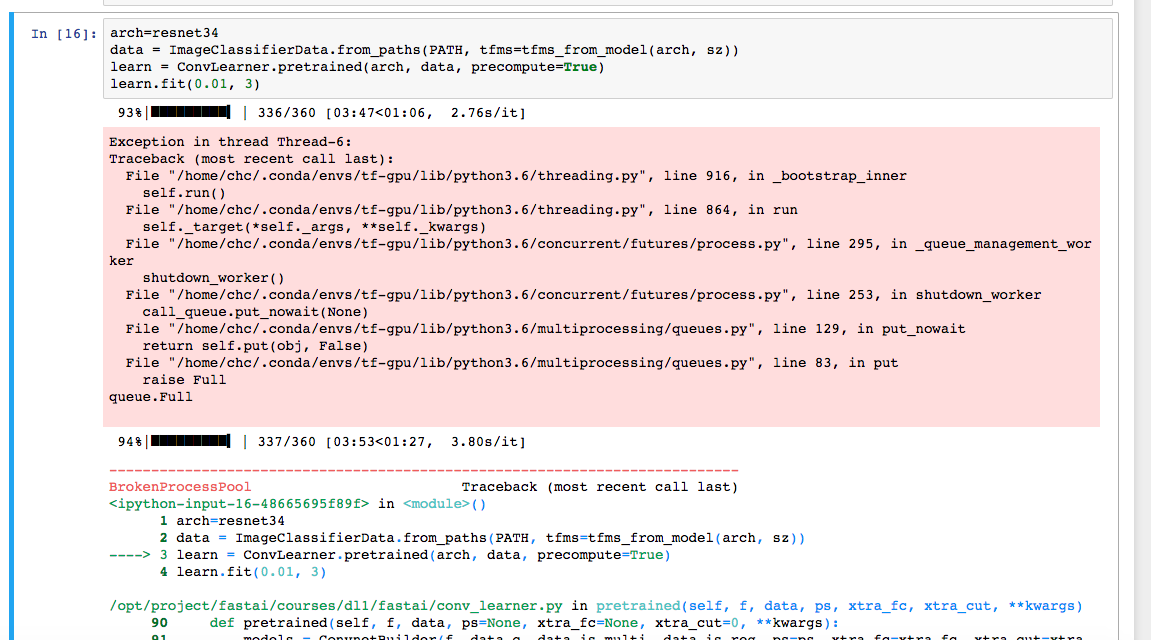
The code was fine earlier before I did a git pull. I even re-install the whole env using the environment.yml and disable the nbextension just to be sure.
Hi guys, do you face the following exception when running lesson1
The code was fine earlier before I did a git pull. I even re-install the whole env using the environment.yml and disable the nbextension just to be sure.
Hi, your image doesn’t include error type but almost sure I got a similar error yesterday while trying to run dogs vs. cats.
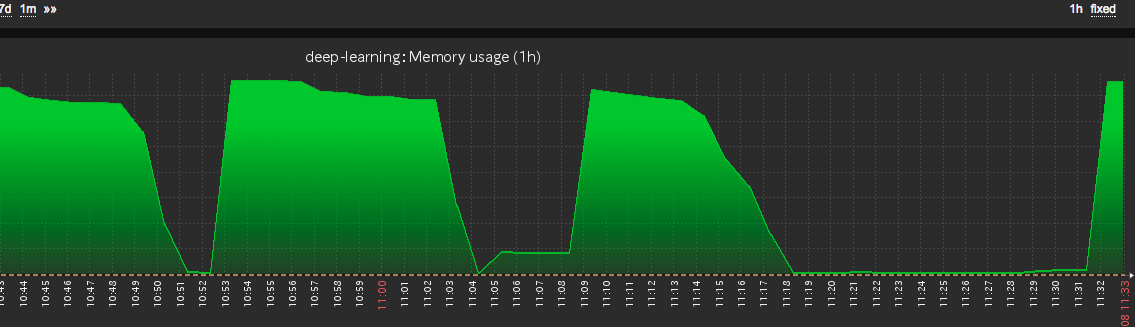
It is quite possible its a Memory error, to be sure you should monitor you GPU and see if exceedes available memory when crashing.
The solution, if that is the case: reduce the batch size.
You are right, adjusting sz (batch size) to lower does the trick. Thanks !
Interesting seem like I am running out of RAM instead of GPU one… might need to tune the linux kernel a bit…
We’ve had 2 other people with memory problems - do a forum search to find the threads. We’re trying to debug it, but because I can’t replicate it myself I haven’t been able to do much. The issue is the Dataloader class we recently added. If you use the Dataloader class from pytorch it’ll fix the problem - but unfortunately some people found that led to random freezes!
The other 2 people with this problem were also using their own Linux boxes - neither Crestle nor AWS nor Paperspace seems to have this issue.
Thanks for the reply @jeremy ! Used to have this problem on Java enterprise stack on AWS … I need to turn off OOM in linux in order for the process not to be kill by the kernel but is not a good long term solution. Will report back if I could find some solution as it seem like the default ubuntu install won’t create a big swap memory and I am trying to see by using a bigger swap will help ! Will create a separate post on my finding later whether having a big swap will be good enough.
Well the thing is - fastai shouldn’t need much memory. So the fact it’s using so much is a bug, and I’d like to fix it…
@jeremy Totally agree ! Anyway now I have a bigger swap, it still run out of memory, trying to turn off OOM to see whether it will crash my system LOL
@jeremy not sure whether this will help, this is the full stack trace in my system
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
in ()
/opt/project/fastai/courses/dl1/fastai/conv_learner.py in pretrained(self, f, data, ps, xtra_fc, xtra_cut, **kwargs)
90 def pretrained(self, f, data, ps=None, xtra_fc=None, xtra_cut=0, **kwargs):
91 models = ConvnetBuilder(f, data.c, data.is_multi, data.is_reg, ps=ps, xtra_fc=xtra_fc, xtra_cut=xtra_cut)
---> 92 return self(data, models, **kwargs)
93
94 @property
/opt/project/fastai/courses/dl1/fastai/conv_learner.py in __init__(self, data, models, precompute, **kwargs)
83 elif self.metrics is None:
84 self.metrics = [accuracy_multi] if self.data.is_multi else [accuracy]
---> 85 if precompute: self.save_fc1()
86 self.freeze()
87 self.precompute = precompute
/opt/project/fastai/courses/dl1/fastai/conv_learner.py in save_fc1(self)
124 if len(self.activations[0])==0:
125 m=self.models.top_model
--> 126 predict_to_bcolz(m, self.data.fix_dl, act)
127 predict_to_bcolz(m, self.data.val_dl, val_act)
128 if self.data.test_dl: predict_to_bcolz(m, self.data.test_dl, test_act)
/opt/project/fastai/courses/dl1/fastai/model.py in predict_to_bcolz(m, gen, arr, workers)
11 lock=threading.Lock()
12 m.eval()
---> 13 for x,*_ in tqdm(gen):
14 y = to_np(m(VV(x)).data)
15 with lock:
~/.conda/envs/tf-gpu/lib/python3.6/site-packages/tqdm/_tqdm.py in __iter__(self)
870 """, fp_write=getattr(self.fp, 'write', sys.stderr.write))
871
--> 872 for obj in iterable:
873 yield obj
874 # Update and print the progressbar.
/opt/project/fastai/courses/dl1/fastai/dataset.py in __next__(self)
226 if self.i>=len(self.dl): raise StopIteration
227 self.i+=1
--> 228 return next(self.it)
229
230 @property
/opt/project/fastai/courses/dl1/fastai/dataloader.py in __iter__(self)
75 def __iter__(self):
76 with ProcessPoolExecutor(max_workers=self.num_workers) as e:
---> 77 for batch in e.map(self.get_batch, iter(self.batch_sampler)):
78 yield get_tensor(batch, self.pin_memory)
79
~/.conda/envs/tf-gpu/lib/python3.6/concurrent/futures/process.py in map(self, fn, timeout, chunksize, *iterables)
482 results = super().map(partial(_process_chunk, fn),
483 _get_chunks(*iterables, chunksize=chunksize),
--> 484 timeout=timeout)
485 return itertools.chain.from_iterable(results)
486
~/.conda/envs/tf-gpu/lib/python3.6/concurrent/futures/_base.py in map(self, fn, timeout, chunksize, *iterables)
546 end_time = timeout + time.time()
547
--> 548 fs = [self.submit(fn, *args) for args in zip(*iterables)]
549
550 # Yield must be hidden in closure so that the futures are submitted
~/.conda/envs/tf-gpu/lib/python3.6/concurrent/futures/_base.py in <listcomp>(.0)
546 end_time = timeout + time.time()
547
--> 548 fs = [self.submit(fn, *args) for args in zip(*iterables)]
549
550 # Yield must be hidden in closure so that the futures are submitted
~/.conda/envs/tf-gpu/lib/python3.6/concurrent/futures/process.py in submit(self, fn, *args, **kwargs)
452 self._result_queue.put(None)
453
--> 454 self._start_queue_management_thread()
455 return f
456 submit.__doc__ = _base.Executor.submit.__doc__
~/.conda/envs/tf-gpu/lib/python3.6/concurrent/futures/process.py in _start_queue_management_thread(self)
413 if self._queue_management_thread is None:
414 # Start the processes so that their sentinels are known.
--> 415 self._adjust_process_count()
416 self._queue_management_thread = threading.Thread(
417 target=_queue_management_worker,
~/.conda/envs/tf-gpu/lib/python3.6/concurrent/futures/process.py in _adjust_process_count(self)
432 args=(self._call_queue,
433 self._result_queue))
--> 434 p.start()
435 self._processes[p.pid] = p
436
~/.conda/envs/tf-gpu/lib/python3.6/multiprocessing/process.py in start(self)
103 'daemonic processes are not allowed to have children'
104 _cleanup()
--> 105 self._popen = self._Popen(self)
106 self._sentinel = self._popen.sentinel
107 _children.add(self)
~/.conda/envs/tf-gpu/lib/python3.6/multiprocessing/context.py in _Popen(process_obj)
221 @staticmethod
222 def _Popen(process_obj):
--> 223 return _default_context.get_context().Process._Popen(process_obj)
224
225 class DefaultContext(BaseContext):
~/.conda/envs/tf-gpu/lib/python3.6/multiprocessing/context.py in _Popen(process_obj)
275 def _Popen(process_obj):
276 from .popen_fork import Popen
--> 277 return Popen(process_obj)
278
279 class SpawnProcess(process.BaseProcess):
~/.conda/envs/tf-gpu/lib/python3.6/multiprocessing/popen_fork.py in __init__(self, process_obj)
18 sys.stderr.flush()
19 self.returncode = None
---> 20 self._launch(process_obj)
21
22 def duplicate_for_child(self, fd):
~/.conda/envs/tf-gpu/lib/python3.6/multiprocessing/popen_fork.py in _launch(self, process_obj)
65 code = 1
66 parent_r, child_w = os.pipe()
---> 67 self.pid = os.fork()
68 if self.pid == 0:
69 try:
OSError: [Errno 12] Cannot allocate memoryCould you try updating to the latest anaconda and also updating all your libs, and see if that fixes the problem?
Also, try setting num_workers to 4, and see if that helps.
@jeremy assume the num_workers is sz variable in the code ? seem like if I change from 224 to 64, I didn’t hit this problem. Will also do an update later. Thanks.
@jeremy just did package update for both conda and pip, seem doesn’t help much but adjusting the sz to a lower value help in my case. Seem like package update bump up the speed !
its not a batch size - thats an image size. batch size is bs passed to ImageClassifierData.
Reducing image size will do the trick as well but probably not in a way you want it to.
Ah got it, I need to pass in num_workers to
ImageClassifierData.from_paths(PATH, tfms=tfms_from_model(arch, sz), bs=bs, num_workers=num_workers)
Thanks !
@jeremy seem like I need to use num_workers=2, maybe my CPU is the lower range type I guess which is a core i3, just curious what does num_workers do ?
It would be helpful if you can show all your hyper parameters: sz, bs, etc.
Also check this post by @abdulhannanali - this way you can hide long error messages.
My current hyper parameters used :-
sz=224
bs=128
num_workers=2
Thanks @sermakarevich for the details, will do that next time.
/opt/project/fastai/courses/dl1/fastai/learner.py in (.0)
111 preds1,targs = predict_with_targs(self.model, dl1)
112 preds1 = [preds1]*math.ceil(n_aug/4)
–> 113 preds2 = [predict_with_targs(self.model, dl2)[0] for i in range(n_aug)]
114 return np.stack(preds1+preds2).mean(0), targs
115
/opt/project/fastai/courses/dl1/fastai/model.py in predict_with_targs(m, dl)
121 if hasattr(m, ‘reset’): m.reset()
122 preda,targa = zip(*[(get_prediction(m(*VV(x))),y)
–> 123 for *x,y in iter(dl)])
124 return to_np(torch.cat(preda)), to_np(torch.cat(targa))
125
/opt/project/fastai/courses/dl1/fastai/model.py in (.0)
120 m.eval()
121 if hasattr(m, ‘reset’): m.reset()
–> 122 preda,targa = zip(*[(get_prediction(m(*VV(x))),y)
123 for *x,y in iter(dl)])
124 return to_np(torch.cat(preda)), to_np(torch.cat(targa))
/opt/project/fastai/courses/dl1/fastai/dataset.py in next(self)
226 if self.i>=len(self.dl): raise StopIteration
227 self.i+=1
–> 228 return next(self.it)
229
230 @property
/opt/project/fastai/courses/dl1/fastai/dataloader.py in iter(self)
75 def iter(self):
76 with ProcessPoolExecutor(max_workers=self.num_workers) as e:
—> 77 for batch in e.map(self.get_batch, iter(self.batch_sampler)):
78 yield get_tensor(batch, self.pin_memory)
79
~/.conda/envs/tf-gpu/lib/python3.6/concurrent/futures/process.py in map(self, fn, timeout, chunksize, *iterables)
482 results = super().map(partial(_process_chunk, fn),
483 _get_chunks(*iterables, chunksize=chunksize),
–> 484 timeout=timeout)
485 return itertools.chain.from_iterable(results)
486
~/.conda/envs/tf-gpu/lib/python3.6/concurrent/futures/_base.py in map(self, fn, timeout, chunksize, *iterables)
546 end_time = timeout + time.time()
547
–> 548 fs = [self.submit(fn, *args) for args in zip(*iterables)]
549
550 # Yield must be hidden in closure so that the futures are submitted
~/.conda/envs/tf-gpu/lib/python3.6/concurrent/futures/_base.py in (.0)
546 end_time = timeout + time.time()
547
–> 548 fs = [self.submit(fn, *args) for args in zip(*iterables)]
549
550 # Yield must be hidden in closure so that the futures are submitted
~/.conda/envs/tf-gpu/lib/python3.6/concurrent/futures/process.py in submit(self, fn, *args, **kwargs)
452 self._result_queue.put(None)
453
–> 454 self._start_queue_management_thread()
455 return f
456 submit.doc = _base.Executor.submit.doc
~/.conda/envs/tf-gpu/lib/python3.6/concurrent/futures/process.py in _start_queue_management_thread(self)
413 if self._queue_management_thread is None:
414 # Start the processes so that their sentinels are known.
–> 415 self._adjust_process_count()
416 self._queue_management_thread = threading.Thread(
417 target=_queue_management_worker,
~/.conda/envs/tf-gpu/lib/python3.6/concurrent/futures/process.py in _adjust_process_count(self)
432 args=(self._call_queue,
433 self._result_queue))
–> 434 p.start()
435 self._processes[p.pid] = p
436
~/.conda/envs/tf-gpu/lib/python3.6/multiprocessing/process.py in start(self)
103 'daemonic processes are not allowed to have children’
104 _cleanup()
–> 105 self._popen = self._Popen(self)
106 self._sentinel = self._popen.sentinel
107 _children.add(self)
~/.conda/envs/tf-gpu/lib/python3.6/multiprocessing/context.py in _Popen(process_obj)
221 @staticmethod
222 def _Popen(process_obj):
–> 223 return _default_context.get_context().Process._Popen(process_obj)
224
225 class DefaultContext(BaseContext):
~/.conda/envs/tf-gpu/lib/python3.6/multiprocessing/context.py in _Popen(process_obj)
275 def _Popen(process_obj):
276 from .popen_fork import Popen
–> 277 return Popen(process_obj)
278
279 class SpawnProcess(process.BaseProcess):
~/.conda/envs/tf-gpu/lib/python3.6/multiprocessing/popen_fork.py in init(self, process_obj)
18 sys.stderr.flush()
19 self.returncode = None
—> 20 self._launch(process_obj)
21
22 def duplicate_for_child(self, fd):
~/.conda/envs/tf-gpu/lib/python3.6/multiprocessing/popen_fork.py in _launch(self, process_obj)
65 code = 1
66 parent_r, child_w = os.pipe()
—> 67 self.pid = os.fork()
68 if self.pid == 0:
69 try:
OSError: [Errno 12] Cannot allocate memory
bs might be too big depending on your model config (if you use precompute or not). Can you try 16?
@jeremy @sermakarevich
Some update on my local environment, using the following hyper params
sz=224
bs=16
num_workers=4
I manage to run lesson1 but I need to increase my swap memory to 64GB with physical RAM 16GB, finally total 80GB RAM to run this. Will be experimenting by slowly increasing bs and see whether I have same issue later. Thanks again guys !