fast.ai Course Forums
Planet Classification Challenge
Part 1 (2018)
Moody
(Sarada Lee)
November 16, 2017, 5:23am
11
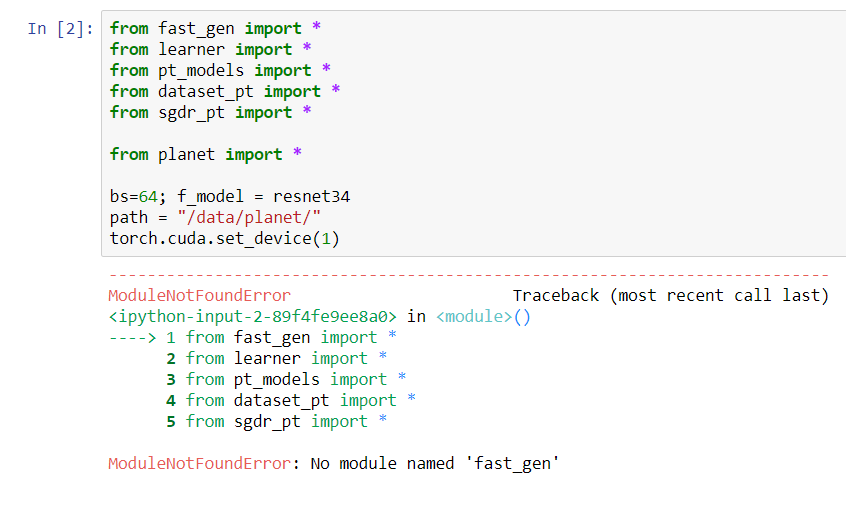
I did “git pull” and “conda update --all”. But, no module named 'fast_gen" in planet_cv.ipynb
image.png
846×506 23.1 KB
show post in topic