@all
(Preamble: There’s an issue with using the planet dataset that’s being discussed here. There’s also a way to side-step the exception-trace as long as you’re not producing the submission file!
https://github.com/fastai/fastai/issues/23#issuecomment-344795382)
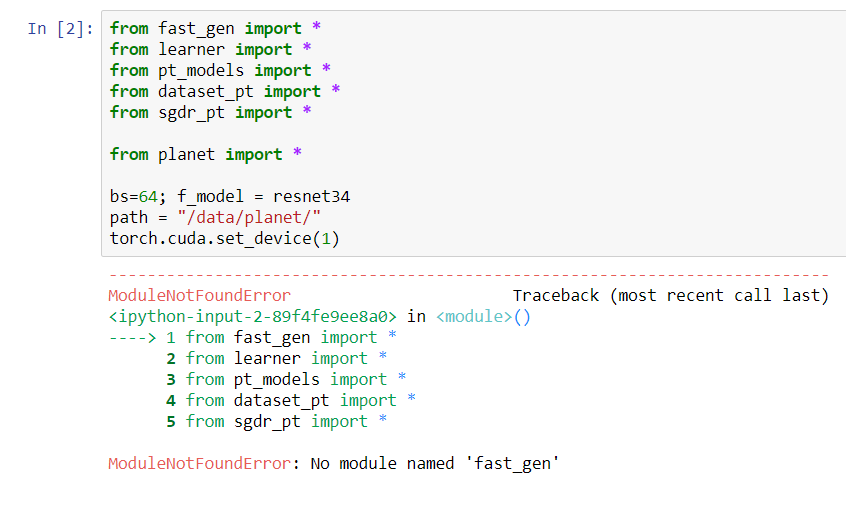
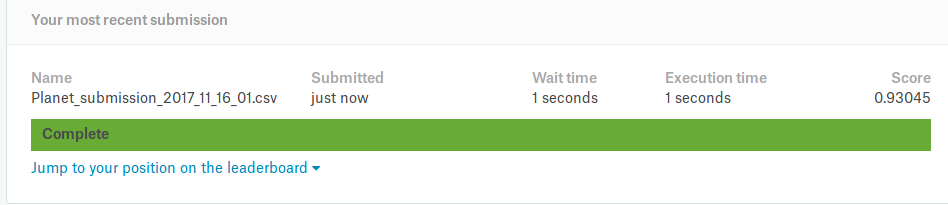
Got my first submission in. At 0.8898 on the leaderboard, think it’s fairly okay. I barely fit the model once, and focused more on getting the submission file done. Here’s my lousy script that produces the file. Nothing fancy, and very java-ish like. I couldn’t, for the sake of good life, get one of them fancy python generators working.
mapp={}
for i in range(17):
result = data.classes[i]
mapp[i] = result
so, that mapp is:
{0: 'agriculture',
1: 'artisinal_mine',
2: 'bare_ground',
3: 'blooming',
4: 'blow_down',
5: 'clear',
6: 'cloudy',
7: 'conventional_mine',
8: 'cultivation',
9: 'habitation',
10: 'haze',
11: 'partly_cloudy',
12: 'primary',
13: 'road',
14: 'selective_logging',
15: 'slash_burn',
16: 'water'}
The script for producing the test thus would be:
import re
tta_test = learn.TTA(is_test=True)
files = learn.data.test_ds.fnames
predictions = tta_test[0]
pattern = 'test-jpg\/(.*)\.jpg'
files = list(learn.data.test_ds.fnames)
with open("planet_submission.csv.apil","w") as f:
f.write('image_name,tags\n')
for i in tqdm(range(61191)):
# files[i] is of this form: test-jpg/test_xyze.jpg
# Only want to extract the 'text_xyze' part for the
# submission
pattern = re.search('test-jpg\/(.*)\.jpg',files[i])
predLine = pattern.group(1)+','
prediction = predictions[i]
for j in range(17):
# only use the prediction if
# score is greater than 0.2
if(prediction[j] > 0.2):
predLine +=mapp[j]+' '
f.write(predLine+"\n")
Now, all I need to do is figure out how to leverage the op_th function! Hmmm… Wife’s really mad I’m doing nothing but coding since I got home. Gotta go to bed !!