Hi. There is a topic explaining how to do a single image classsification with the simple models from Part 1: How do we use our model against a specific image?
Could someone please explain how to do the same with the model created in this lesson?
Hi. There is a topic explaining how to do a single image classsification with the simple models from Part 1: How do we use our model against a specific image?
Could someone please explain how to do the same with the model created in this lesson?
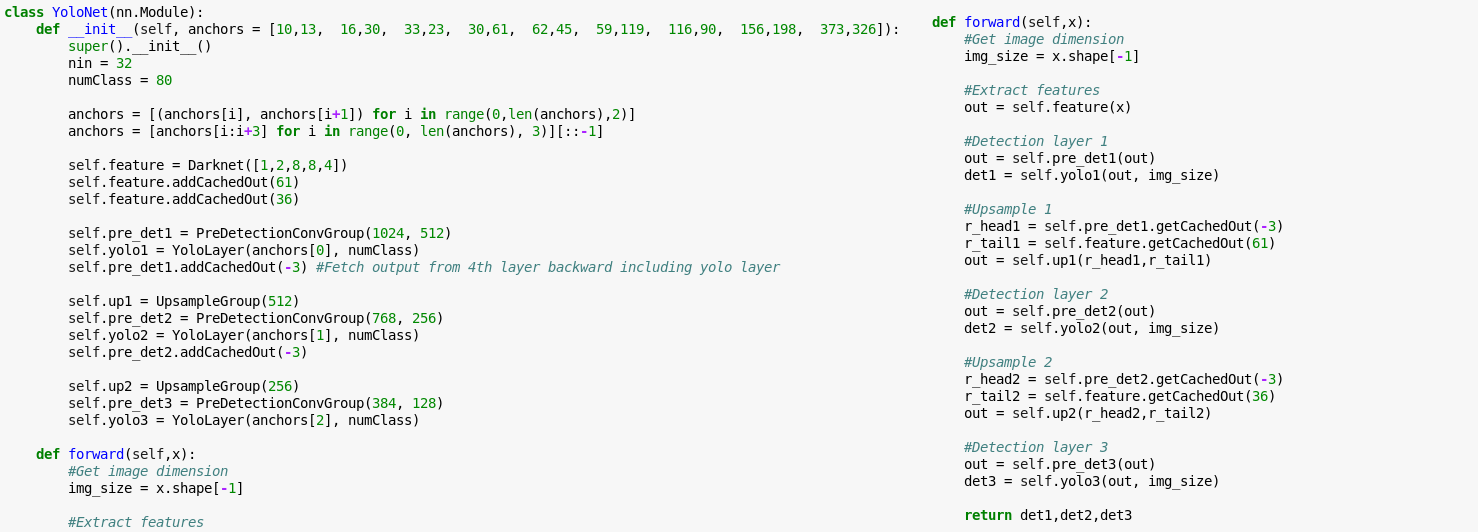
Finally put in the effort to chew through papers/blogs regarding Yolo. I implemented the YoloV3 detector forward pass in a single notebook from scratch.
Tried to be more “oop” after watching Lesson 12 darknet building tips.
But I still found the code ugly when I need to implement route layers that grab feature maps from earlier layers, because I would still need the config file from the original Yolo Repo to know where to connect it. I created a dirty function that maps the layers to the entries inside the config file, but I could feel there’s a better way to do it. Any tips on improving?
I’m still trying to figure out the loss function of YoloV3. Doesn’t seem to have a lot chatter about it on the internet. I guess the only way to proceed would be prying through the C source code from the original repo.
Check out the dynamic unet in fastai - that handles cross connections automatically.
Thanks. I haven’t got to the unet part of the fast.ai course. Took a quick look, it seems the main idea is to acknowledge where these cross connections happen when initializing the architecture, so I can create a list/dict of these cross connections and loop over them in the forward call.
My initial idea was leaving the possibility that I could connect these layer anywhere I want at any time, but in this case these connections only exists at the end of each stride (right before downsampling). Gonna read the code again this weekend. Thanks again.
Hi, I tried to implement YOLOv3 paper in clean pythonic way in PyTorch. If someone is struggling to understand object detection or YOLOv3 have a look at it https://github.com/mmalotin/pytorch-yolov3.
Let me answer my question. There is a rough but working way to reason on a single image:
def show_nmf_single(idx=0):
ima=md.val_ds.ds.denorm(x)[idx]
trn_tfms, val_tfrms = tfms_from_model(f_model, sz, aug_tfms=transforms_side_on, max_zoom=1.1)
im = val_tfrms(open_image(f’{PATH}/image.jpg’))
batch = md.val_dl.np_collate([im])
batch = T(batch, cuda=False).contiguous()
x = to_gpu(batch)
batch = learn.model(V(x))
b_clas,b_bb = batch
x = to_np(x)
show_nmf_single()
I tried the following after training the bboxes and it didn’t work:
trn_tfms, val_tfms = tfms
ds = FilesIndexArrayDataset(["000046.jpg"], np.array([0]), val_tfms, PATH)
dl = DataLoader(ds)
preds = learn2.predict_dl(dl)
TypeError: object of type ‘numpy.int64’ has no len()
But the following works:
trn_tfms, val_tfms = tfms
ds = FilesIndexArrayDataset(["000046.jpg"], np.array([0]), val_tfms, PATH)
dl = DataLoader(ds)
preds = learn2.predict_dl(dl)
print(preds)
Result:
array([[ 35.4234 , 97.52946, 64.6991 , 136.12167]], dtype=float32)
However, the rectangle it predicted is WAY off. I also tried training my model using tfms_from_model(arch, sz) instead of tfms = tfms_from_model(arch, sz, crop_type=CropType.NO, tfm_y=tfm_y, aug_tfms=augs) and the model doesn’t even fit the training set very well (the boxes are way off as well.)
Any ideas?
Hi,I want to gain more intuition on actn_to_bb method,why did we use only these specific steps to alter our output activation?
As i understand actn_bbs comprises of 4 values (x,y co-ordinates for top-left and bottom-right corners of predicted bounding box) for each grid cell,and we are deriving new center,hight,width and then returning activation in “corner” format.
def actn_to_bb(actn, anchors):
actn_bbs = torch.tanh(actn)
actn_centers = (actn_bbs[:,:2]/2 * grid_sizes) + anchors[:,:2]
actn_hw = (actn_bbs[:,2:]/2+1) * anchors[:,2:]
return hw2corners(actn_centers, actn_hw)@jeremy get_y(bbox,clas) function defined in notebook of the lesson breaks down when there is no bounding box in the batch. In that case, all the elements of input bbox are zero and resultantly bb_keep variable gets assigned nothing.
It might be a frequent case in datasets where objects are sparse.
What can be done to fix this error ?
I also have similar questions to @guptapankaj1993.
My naive solution is set all bbox coordinators to be zero as below. Please comment if you have a more elegant solution.
fnames, bbox
cat1111.jpg, 0 0 0 0
My naive solution is to add zeros to the polygons until its length reaches the pre-defined maximum length Nmax. So that all training labels will have the same length of Nmax. Please comment if you have a more elegant solution.
Thank you in advance and your feedback is very much appreciated!
Hi,
I am confused by Jeremy’s explanation in the video of the reasoning behind using two Conv2d’s in the OutConv class (0:45:15) and hopefully someone can clarify.
These two Conv2d’s are described as being “nearly the same thing” as using a single Conv2d and that using two separate Conv2d layers “lets these layers specialize just a little bit” by “sharing every single layer except the last one”
However, surely the filters in a convolution layer are totally independent from each other? As these two Conv2d layers both have the exact same inputs and have the same strides and filter sizes there really is precisely no difference between a single Conv2d and two separate Conv2d layers in this case, and using a single Conv2d and slicing the required parts of the output volume to feed into the appropriate parts of the loss function would have exactly the same effect.
It is true that they share every layer except the last one (the one they are in) but that would be the case whether a single Conv2d or two Conv2d’s with the same number of filters was used.
So to my mind the ‘intuition’ that separating them will somehow improve the ability of the network to learn the necessary function is wrong and while I do not know how convolution layers are implemented in GPUs I would not be surprised if there was a performance benefit to using a single one with more filters as I could imagine that there could be opportunities for further parallelism/vectorization.
(Note: I have not been able to test if there is any performance difference as my Jupyter notebook is not running at present but I would love to hear if anyone tries it.)
Around 21:00, Jeremy shows the loss function for the object classification and bounding box regression. For the regression, he uses the sigmoid to force the bounding box coordinates inside the frame (to make it easier for the model to learn). In that function, why didn’t he use a softmax on the classification before getting the cross-entropy loss?
In the final model we have grid sizes of [4, 2, 1] and k=9 for a total of 189 anchor boxes. When we ask the model to predict on an image, we get a [189, 21] tensor of class predictions and a [189, 4] tensor of bounding box predictions.
As I understand it, we determine what predictions/boxes are meaningful/accurate by calculating the IOU for each prediction relative to a threshold.
How would we use this type of model for prediction without a known ground truth? How would we determine what bounding box predictions are meaningful? Would we do something like put the class predictions through a sigmoid and compare them to some cutoff value, or is there a better way?
I’m facing a problem here, I’m using a GPU.
When i use CPU for executing ssd_loss(batch,y,True) as given in notebook, i get this:
RuntimeError: Expected object of type Variable[torch.FloatTensor] but found type Variable[torch.cuda.FloatTensor] for argument #1 'other'
Although I made a minor tweak. After i get x,y and convert them to Variable, i had to do this differently:
batch = learn.model(x.cpu())
When i put everything on gpu, i get this when running ssd_loss(batch,y,true)
TypeError: Performing basic indexing on a tensor and encountered an error indexing dim 0 with an object of type torch.cuda.LongTensor. The only supported types are integers, slices, numpy scalars, or if indexing with a torch.LongTensor or torch.ByteTensor only a single Tensor may be passed.
How to deal with this problem ? If someone has a working nb, or solution, please share it
At 1:18:30, Jeremy draws a vector containing the ground truth’s bounding boxes. He also refers to it as the dependent variable. In what way is it a dependent variable? What’s the independent variable?
Hi everyone,
I am having difficulties with getting a test set to work for the bounding boxes.
I am getting an indexing error:
~/fastai/fastai/zeroshot/fastai/transforms.py in make_square(y, x)
195 y1 = np.zeros((r, c))
196 y = y.astype(np.int)
–> 197 y1[y[0]:y[2], y[1]:y[3]] = 1.
198 return y1
199
IndexError: index 2 is out of bounds for axis 0 with size 1
If you have gotten a test set to work with this notebook then please let me know, any help with this would be appreciated 
Hey guys, check out the my blog on Introduction to Object Detection. Hope you enjoy it and feel free to comment in case of any queries or suggestions.
i’m also stuck at this.
Have you tried removing the .cpu()?
So it looks like this; batch = learn.model(x)
Removing .cpu() if you are running on gpu worked for me 
I already tried with that, not working. Which Pytorch version are you using btw ?