The version I did ignored caps that started a sentence. I don’t think they should be marked, since they’re syntactic, not semantic (mainly).
2 Likes
I have gone through the Lesson 10 in detail and understand conceptually and from code as to what is happening. My Language model though is still learning. Have tried three times in AWS and all three times there has been a broken connection beyond 1 hour of the model being fit. It is taking really too long. This brings me to the question - Has anybody been able to do the VNC tip that Jeremy explained in the last class for Mac. If so can you explain / help on the same?
1 Like
Also one other query. In the note book the code for trn_lm is
trn_lm = np.array([ [stoi[0] for 0 in p] for p in tok_trn ])
why are we doing this as the tokenizer is on the word and not on the individual alphabet. But having said that the effect of this code is the same. it still gets the integers of the words only and not the alphabets.
Oh sweet! Let me clean up some of the extra stuff I put in there and submit a PR.
@jeremy:
could you also please point me to the LeCun paper which influenced our standardized label-first CSV file format?
Aha…I can see why it’s confusing for you. Each item of tok_trn is a full movie review. We only do words, not characters.
See my updated notebook which contains notes and comments to help you understand better:
3 Likes
Tomas Mikolov meant to use a linear model for creating the word2vec embeddings, mainly to demonstrate the vector arithmetic you see in the popular media (king - man + woman = queen). You can listen to his interview here.
Now, the idea of creating embeddings is widely popular and useful. Even in our IMDB LM, we are keen on getting our embedding layer trained well, so that the pooling linear classifier layer(in IMDB classifier model) in the decoder can very well benefit from it. The key difference as you rightly mentioned is the size and the quality of the model itself that is used to generate the embeddings.
Now FitLam is a breakthrough because of not just the core LM backbone idea but all the additional pieces Jeremy invented, that help you fine-tune efficiently…such as discriminative learning rates, use of AWD lstm, usage of layer groups…etc. all these things contribute to the quality of the final classifier.
If you see the Salesforce COVE paper Jeremy showed in class, they also used a pre-trained LM backbone, but they didn’t unfreeze() fully and train end to end to get that last big boost.
There’s a Cambrian explosion going on in NLP and hope FitLam becomes the alexnet equivalent for the area!
Having said that, we need to ask ourselves, does a strong LM that can spit out new words after seeing _bptt_grams (lol I made that up), really learn English? Like, I mean, is English solved?? Maybe we learnt to write nice long Wikipedia articles and IMDb movie reviews with super low perplexity…but can it tweet like the commander in chief?
So, it behooves us, as the fastai community, to ask the hard questions and experiment with the LMs and truly determine how much of English are we actually learning. Are we able to improve the sota on semantic similarity tasks? Are we able to generalize to widely varying sequence lengths? What can another strong model(such as vaswani transformer in the case of Tensorflow universal encoder) learn that our LM backbone can’t and vice versa, what’s the relationship between corpus size and perplexity? Etc…
I hope to start another experiment thread where we can work on such experiments…love to hear your thoughts and prayers (ideas…darn RNN autocorrect)!
4 Likes
Ah, that’s what was happening there. I couldn’t figure out what you were doing, but that makes sense. I will finish training things how I have it now, and then maybe I’ll go back through a second time and take out the sentence starting Caps.
1 Like
Minor correction: they used a translation model as their base. One big problem with that is you can’t fine-tune the language model on your target corpus, unless you have translations for it!
2 Likes
We’ve answered that to some extent, showing good performance from TREC-6 (tiny!) to IMDB (fairly big). I haven’t tried really big docs however.
2 Likes
I’m not certain I understand the functionality of SortishSampler. I thought the idea was to approximately sort by a key, and I expected the output would be roughly linear along the key dimension, but that doesn’t seem to be the case.
Here’s the output I’m getting from a sortish of a random array of 1000 integers from 0-100
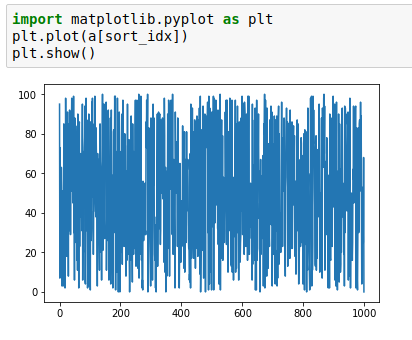
At this point I’m not sure the function is working properly. I’ll take a look at coming up with something closer to what I think was intended but in the meantime I’d be curious if anyone else has explored/validated it.
I’d like to put together a PR that reverses the list, providing max values first to help with memory issues, but after running through a toy example I’m not convinced it’s providing min values.
Hi…are you also turning those into sequences and paddingthem?
Or you just want to display sorted-ish numbers?
Oh yes! Makes sense!
Has anybody been able to do the VNC tip that Jeremy explained in the last class for Mac.
I assume you mean from a mac to aws?
SSH to the remote box and setup port forwarding:
local:$ ssh -L 5913:localhost:5913 user@remote.host
remote:$ sudo apt-get install xorg lxde-core tightvncserver firefox lxterminal xfonts-100dpi
# ...
remote:$ mkdir ~/.vnc
remote:$ vim ~/.vnc/xstartup
# edit to contain:
# lxterminal &
# /usr/bin/lxsession -s LXDE &
remote:$ chmod +x ~/.vnc/xstartup
remote:$ tightvncserver :13 -geometry 1200x900
After you do that, open the Mac app called “Screen sharing” and connect to localhost:5913.
8 Likes
Just trying to validate the functionality of sortish.
@narvind2003, @blakewest had suggested freezing only the last layer instead of un-freezing during the final training (fine-tuning) step. One thing is for sure, unfreezing all the layers requires a heck of a lot more processing. But is there any benefit to unfreezing the whole model to backprop the training weights? Is this what @jeremy intended?
It’s not clear what you mean by a lot more processing…the weights have to back propagate all the way back regardless of whether the layers are set to be trainable or frozen. It’s just the model will calculate gradients but won’t update the parameters in the frozen layers. Theoretically that’s the case…but I need to check the internals to see if that’s how pytorch handles it.
I am slightly confused about something. In imdb.py, we first convert our texts to integer codenumbers (with itos()). Later, we convert the IMDB codenumbers to wikitext103 codenumbers (with itos2()). Any IMDB codenumber which was not in the wikitext103 codenumber gets a -1.
Is there a reason why we don’t just use the wikitext103 code numbers from the start?
I thought maybe it was because you didn’t want to lose t_up, but t_up is actually in itos2().
Also, <bos> and <eos> and <unk> are NOT in itos2(), so is there any point in defining them? Seems like they just get erased when making LM.
The reason we start with the IMDB text is so that we can pick the most frequent words as our tokens.
There are some words in imdb movie reviews which are not to be found anywhere on Wikipedia (wikitext103)…those words(tokens) have to be caught and given a default weight…we catch via stoi, where the defaultdict trick can flag them with -1.
Then we give mean weights to all -1 tokens…
Hope this is clear.
3 Likes
Also what I suggested was - first unfreeze the last layer and train hard…then unfreeze fully and train some more gently(lower rates)