@rsrivastava We could use some form of word embeddings and then cluster them into two groups of positive and negative using some form of distance vector based on the embeddings or Wordnet. Gensim does this pretty easily.
Still a long way to go in unsupervised learning though.
CUDA Memory Issues with Classifier
@Even, @jeremy, The LM ran just fine with a BS of 48. I tried @Even’s PR, but it still ran out of memory on my 8GB GTX-1080 for the classification task with a BS of 32.
RuntimeError: cuda runtime error (2) : out of memory at /opt/conda/conda-bld/pytorch_1512387374934/work/torch/lib/THC/generic/THCStorage.cu:58
For the Classification task, run with a BS of 16. here are the results:
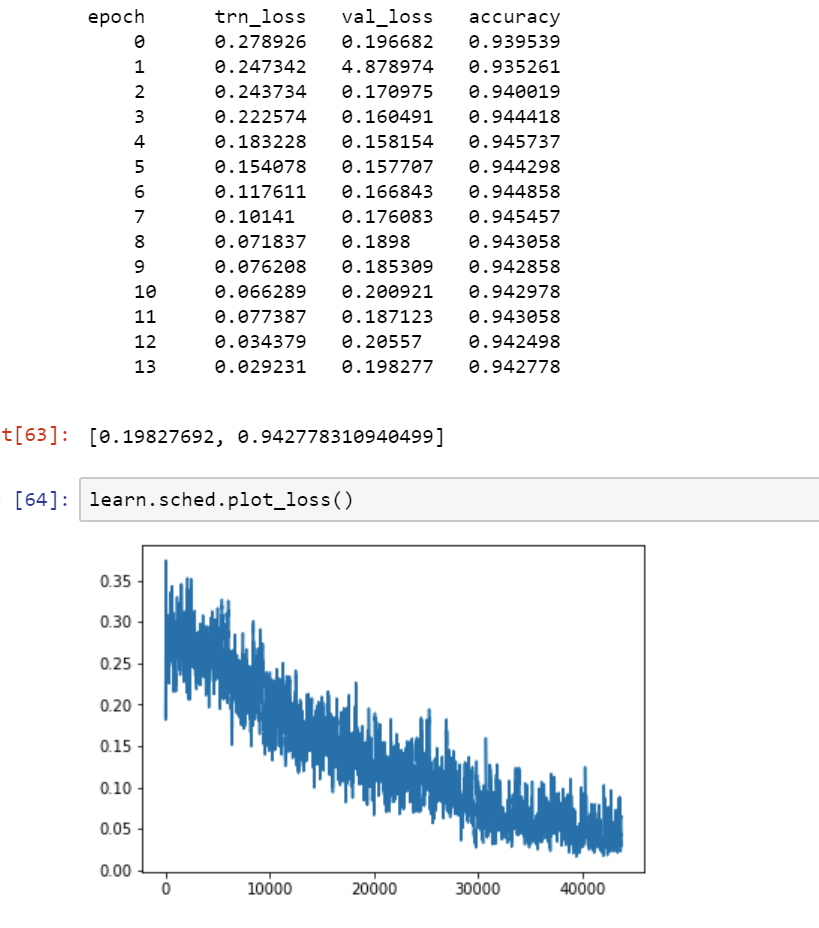
Here is a link to my edited notebook, I’ve tried to document it like @timlee, but not trying to get his job.
https://drive.google.com/file/d/1KQeuyoxh_w2VqQMt7wVjI6jISIQ1N9DZ/view?usp=sharing
1 Like
My PR fixed the language model, but not the classification. I’ll try to get one for that today.
Before what would happen is that memory would go through jumps early on, so you’d see a model allocated and when the batches start loading it would go from 4 Meg to 8 to 10 to 12 very quickly and then run out of memory. After adjusting the batch size (and embedding size because I was working on this back in lesson 4) I worked it down to a size that fit my gpu, but what I noticed was that the model that I was able to fit on my GPU without out of memory errors (1080-ti) would settle down to about 4 gigs after a few minutes.
I started researching the issue on the pytorch forums and ran across a thread where Adam Paszke posted about how memory was allocated on the device and figured that if I pre-allocated that would probably fix the issue. Lo and behold when I ran it after the fix using the same parameters the gpu memory usage stayed constant at 4 gigs.
Here’s the important part of the article:
The memory is ready to be reused as soon as the tensor goes out of scope in Python (unless you have reference cycles in your objects). The GPU memory is only growing because we’re caching CUDA allocations. cudaMalloc and cudaFree are slow and synchronize CPU with the device, so it’s unacceptable to call them all the time. Our CUDA allocator will keep all the allocated blocks around, because it’ll assume that you’re going to use them at the next iteration too. However, if you’re going to operate on inputs of different lengths, you might want to do a warm up pass with the largest length you’re going to use throught the training. This will ensure that the allocated buffers will be able to contain any of the sequences. Otherwise the allocator has to do some compacting and allocate larger blocks once you use a sequence that doesn’t fit into the blocks you have allocated.
It’s a pretty interesting and obscure issue, but an important one if you’re feeding data of different sizes into the device, which is a common enough thing to do.
BTW this also affects the classification, which is currently sorting in ascending order. I need to dig into SortishSampler a bit to make sure that adding reverse=True args is all that’s necessary to fix this there, but feel free to update it yourself as you know the function better having written it. I’ll try to get to it later tonight after work and my son’s in bed if possible.
8 Likes
I think I have an intuitive understanding of why FitLaM works. I’m sharing it here for feedback.
@jeremy
Word2Vec defines a fixed context or window for a given word and updates the embedding to best predict this context. Each word in the window is given an equal weight but because some contextual words occur more frequently than others, the resultant word embedding ends up representing the average majority context. This has a drawback as no transitional information between the words themselves is captured. For eg, consider the use of cricket in the following sentences:
- I need a bat to play cricket.
- In my garden, there’s a cricket.
Word2vec automatically downsamples words based on frequency, so stopwords have little effect on embedding for cricket. Possibly, the discriminating words end up being ‘bat’ and ‘play’ for sentence 1 and ‘garden’ for sentence 2. If sentences of type 1 occur more in the corpus then the embedding for cricket will end up representing the ‘sport’ cricket whereas if type 2 occurs more, then it will end up representing the ‘insect’ cricket.
Now consider a sophisticated language model which takes into account the transitional probabilities in addition to the context. It will know that if we have the word ‘play’ in the context, then the next word will probably be a sport whereas if there’s the phrase ‘In my garden’, then the next words might contain an entity typically found in people’s gardens. Thus it will take into account the different transitions a word can have thus capturing diverse contexts. By pretraining on a large text corpus, the embeddings are able to capture all the possible contextual cues and finetuning allows us to filter to the context relevant to the target task. I feel this training objective of capturing diverse transitions is similar to multi-task learning and as suggested in the FitLaM paper, probably the performance can be improved even further by incorporating different NLP tasks as part of the training objective.
tl;dr FitLaM captures different transitions of a word whereas Word2vec captures the average majority context.
4 Likes
The technical term for what you are talking about – two words with the same spelling (and even sound) which have different meanings – is called polysemy for the noun, polysemantic for the adjective.
There is an article which IMHO is very interesting on how to make polysemantic word embeddings, and I don’t know why it hasn’t gotten more attention. (But I’m not one of the cool kids, so don’t know why they do or don’t pay attention to articles.)
https://arxiv.org/abs/1511.06246
@rudraksh, your explanation for why a language model works better than an embedding alone makes sense. (Note that FitLaM is not the first language model, it just does a good job modelling the language.)
3 Likes
For the target task LM finetuning, is it fair to use all the training and test data of a classification dataset(if it is a small dataset, and you do not have enough separate data for unsupervised training purpose)? As we are using the dataset for Language modeling, I am not sure if the final classification performance will be from overfitting?
@jeremy Regarding the ULMFiT paper, you showed a graph of performance of 3 models on different amounts of training data. There were 3 models: “from scratch”, “UMLFiT, supervised” and “ULMFiT, semi-supervised”. What is the difference between “semi-supervised” and “supervised” here? Is “from scratch” using the same neural network architecture but trains from scratch on a small subset of labeled data?
I found that the official lesson 10 imdb notebook does not have any comments or markdown explanations.
So, I started adding the comments and explanations as I was doing the experiments.
Please find my version of the imdb lesson10 notebook here: LINK.
Hope it helps clarify some of your questions. Please let me know if I can add/edit something. Thanks!
9 Likes
Thanks! BTW PRs with notes for notebooks are most welcome.
3 Likes
It’s fair for the LM training (since you’re not using the labels) but not for the classifier training.
1 Like
Semi-supervised means we used the ‘unsup’ folder for the LM.
IIRC it means we didn’t train an LM.
Language model takes hours to run?
This is the 1st epoch in week 10 nb! Am I missing something or it’s supposed to take hours?

Quick question - how to check if my language object is on GPU?
try this within your notebook:
import torch
import sys
print(’__Python VERSION:’, sys.version)
print(’__pyTorch VERSION:’, torch.version)
print(’__CUDA VERSION’)
from subprocess import call
! nvcc --version
print(’__CUDNN VERSION:’, torch.backends.cudnn.version())
print(’__Number CUDA Devices:’, torch.cuda.device_count())
print(’__Devices’)
call([“nvidia-smi”, “–format=csv”, “–query-gpu=index,name,driver_version,memory.total,memory.used,memory.free”])
print(‘Active CUDA Device: GPU’, torch.cuda.current_device())
print ('Available devices ', torch.cuda.device_count())
print ('Current cuda device ', torch.cuda.current_device())
A CPU run should be slower than 1.5 hour per epoch.
It takes about 30-35 minutes on an nvidia 1070 with the default batch size and bptt.
Did you change the batch size or bptt? nvidia-smi would also show a very high GPU utilization while training as well as the PID of the running python process that would consume almost all the memory of the GPU
To check whether the language model is on the GPU, you can also pull out the model and check if it is on GPU or the CPU. I can’t remember the function off the top of my head. Was it md.get_learner() ?
1 Like
Guess, it’s those 90k rows for the model. I just tried with 100 rows and could classify with 92% accuracy. This gives me time to explore the nb! Thanks to @narvind2003 for the suggestion!
1 Like
You’d do .cuda() but fastai introduces a nice wrapper called to_gpu()
Initially the t_caps are looking good, but It’s still a long ways from done. There are a lot more Caps than I would have guessed. It is the highest frequency which needs to be explored and verified, but the reason it could make sense is because any word can be capitalized. You know you at least have one capital letter in every sentence, but not necessarily the same for any word. I will have a better idea how things are going once the language model finishes training.
This is interesting. I’ll check out the linked paper, thanks! Do you think there’s more to LM embeddings than just polysemantic knowledge?