Huge FastAi fan, first time poster.
Project goal: I’m using aerial imagery to identify every surface parking lot in US cities. I want to create a database of the locations and bounding boxes of each parking lot.
Data sources:
- Imagery source: ~1m resolution NAIP imagery over a handful of US cities
- Training data: OpenStreetMaps has an incomplete set of parking lot areas identified. In San Francisco, for example, they have ~4000 identified parking lots. I want to find the rest of them.
Question
I am considering two approaches and wanted to get people’s input:
Approach 1) Divide the imagery into tiles (e.g. 64x64 pixels). Use a CNN to identify which pixels in each tile are parking lot pixels based on the training data.
Approach 2) Segment the objects in the imagery (e.g. buildings, roads, parking lots) to create superpixel representations of the object. I’ve used a Felzenzwalb segmentation via SKImage. Use a random forest on features of the superpixels as my model.
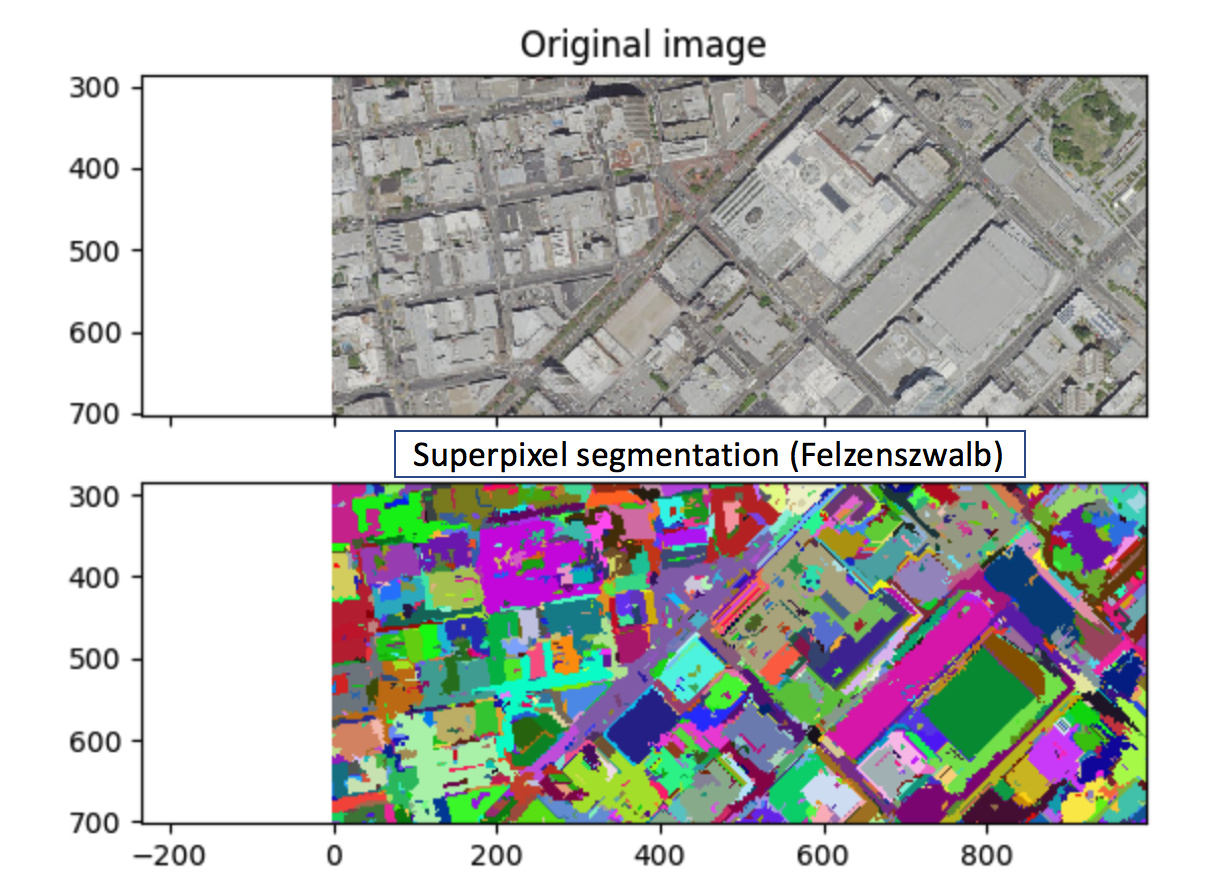
This approach is inspired by this excellent post: object based image analysis
The challenge
Approach 1 challenge: All CNN approaches I’m familiar with have a categorial output - e.g. dog or cat. The output I’d be looking for is a binary “is parking?” for each pixel in the 64x64 image. How can I have a CNN output a 64x64 output rather than a single category for the tile? Also, which model would be best for this application (e.g. VGG16)?
Approach 2 challenge: The superpixels are varying sizes and asymmetric. This means a CNN won’t work because it accepts rectangular images of the same size. I’m not sure what model or features to use to describe the superpixels. The post above suggests a Random Forest as the model but doesn’t give guidance on which features to use for the Random Forest.
Any guidance on how to approach this problem?
