@Dee Hi I see your using a python2 env within a anaconda3 install that’s confusing me. I realise they might not be what I think they are referring to. Regards
Yep it running python2.7 in a conda environment from a base anaconda 3.5 install, So everything is installed in the python2 sub environment, Its just another type of virtual env and allows you to seperate out all your python dependencies.
If you are using anaconda I would recommed you use a conda env for your work. If you are not using anaconda then use virtual env. It just good practice for python to keep it seperate.
Yes, but much slower. We cover this issue quite a few times in the lessons so keep watching and you’ll get the idea! Basically, you want to precompute the convolutional layers, since they’re slow. Setting to non-trainable still requires them to be computed for every epoch!
In the video at the 1:32:35 mark,Jeremy mentioned that augmentation should not be applied on the validation set. However at 1:54:50, the augmentation is also applied on the validation set. Am I missing something here?
Another question:
Here is a snippet of the Data Augmentation section of mnist.ipynb
In my opinion, with the augmentation we have access to pretty much infinite number of different images.
Would that mean that the choice of batches.N as number of batches per epoch to be actually quite meaningless, and the same goes to the choice of test_batches.N?
In the absence of augmentations, I’m thinking batches.N/batch_size might be more appropriate, it feels like more like an epoch, except some images get sampled more than once and some don’t get sampled at all.
I use Python 3 and Keras 2.0.2, and batches.n returns 60000 for me, and I assume batches.N is the same.
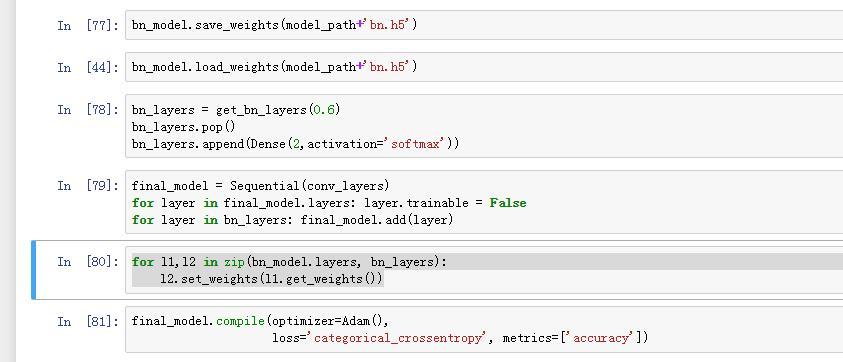
Why we need to set the bn_model’s weigths to bn_layers? In [79], we already added the bn_layers to the final model, but in[80], we set the bn_model’s weigths to bn_layers, I think it can do nothing to the final model right? So why would we do that?
Question translation to English:
Hi guys,
I’ve fininsh training the vgg model for cats_dogs_redux_competition, and I save the weights and model, but I don’t know how to predict the test image, what should I do? Thanks.
@justinho, If you see in cell 78, bn_layers are created new. It doesn’t have any weights of trained bn_model before. I am not sure why he did this, but since it doesn’t have any weights he set the bn_model weights in cell 80.
@justinho Since you trained the bn_model before, by setting the weights of bn_model to the new model, you are effectively creating the same model here. So final_model gives same outputs as bn_model, except we also added conv layers and built the full model .
After the step 4 is completed, we added the bn_layers but they don’t have initial weights, since we created them new. We can again train the full model to get the proper weights, but since we already trained a bn_model before, we are just setting those weights to bn_layer.
After this, we can train the model again. But since we already set the weights of bn_model, we can converge much faster to optimal weights.
Got it, after set the weights to bn_layers, we can add it to the final model again, and it will converge much faster than that have no weights in bn_layers.Thanks @Manoj
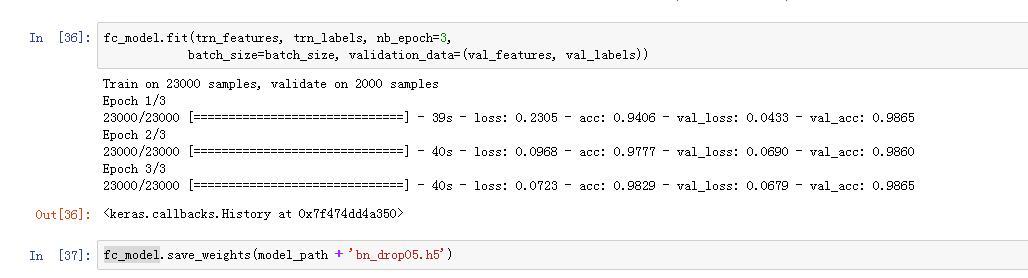
According to the notes Batchnorm can give a 10 * speed improvement. Therefore I was disappointed to see my 11 minute epoch did not fall to 1 minute when I added Batchnorm. Under what circumstances does Batchnorm give 10 * speed improvement?
I think that faster here means that the model will improve in accuracy faster not speed.
So if for example your model was taking 10 epochs to get to 80% acc with batchnorm it could reach the same accuracy in 5.
If anything the speed on adding batchnorm will be slower as the gpu is doing (a little) more calculations
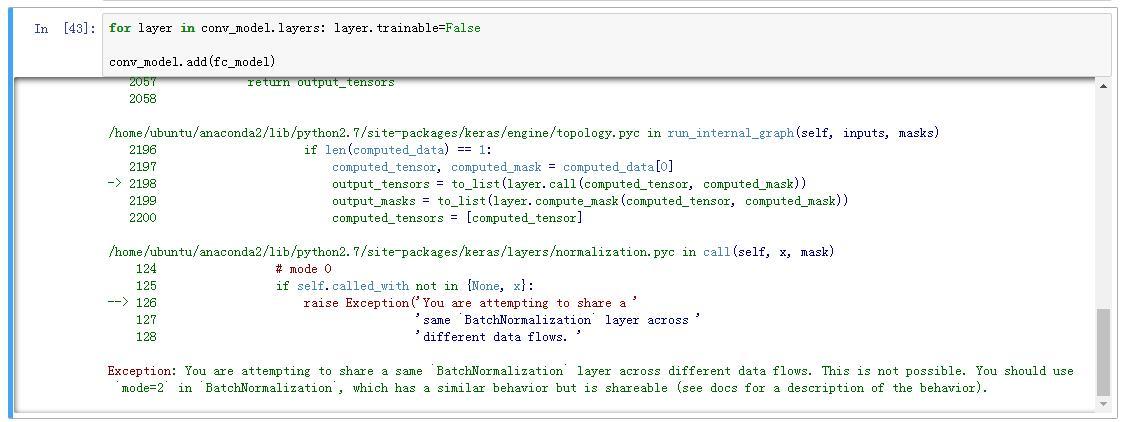
Hi guys,
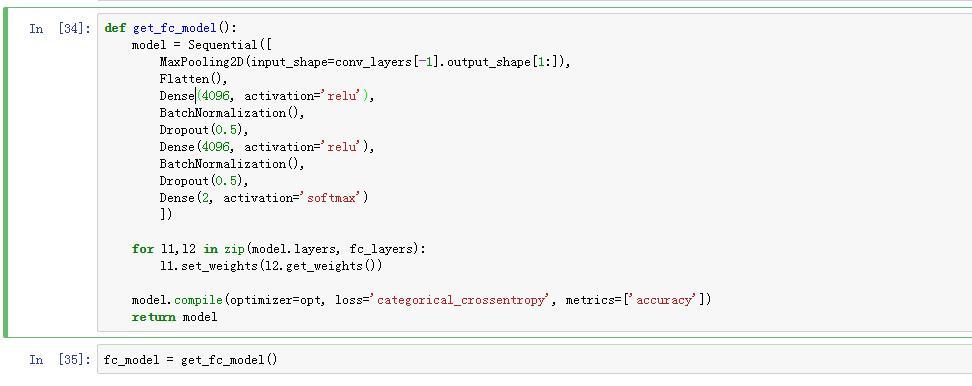
I’m working on the vgg16bn model, first I import the vgg16bn model, and then I separated the conv layers and fc layers, also changed the dropout.
After I fit the fc_model a few times, I want to add the fc_model to the conv_models, but it raised an error:
"You are attempting to share a same BatchNormalization layer across different data flows. This is not possible. You should use mode=2 in BatchNormalization, which has a similar behavior but is shareable (see docs for a description of the behavior).
"