Hello All,
Use case: I have a web application for K-3 activities. I tend to break UI of one activity or other and testing UI is very tedious – requires eyeballing {Ido have way to generate automatically all screenshots though}
The aim is to let AI handle it and I was thinking of classifying the UI as “BrokenUI” or “OKUI”.
Current status: We have gone through Lesson-0 to Lesson-2 video and corresponding book chapters. The kaggle notebook is BrokenUI | Kaggle
After following the “Lesson-1, 2” steps, I loop through all the images in my DataSet and print whether “BrokenUI” or “OKUI”. By eyeballing we have determined whether UI is broken or not and renamed the images with “Broken” as “BD” and those with “OKUI” as starting with “D”
The predictions are mostly inaccurate and the loss/error_rate are as below
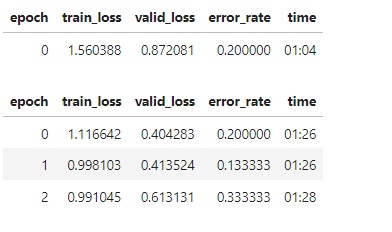
Am I on the right track and should go through the next chapters to see improvements or am I on the wrong path? Any guidance/comments are appreciated.
Thanks