I made a notebook which has the visualizations after each convolution step. If anyone wants to see it, please check out the notebook in my github repo . The images becomes too small at around 20th step and becomes difficult to figure out as to what exactly it is trying to do.
It would be nice if somebody could help me figure out images maximally activating the neuron.
Hi, As I was watching the lesson2 videos @jeremy mentioned when we precompute the features from convolutional layers, it prevents us from doing data augmentation. A similar note is mentioned in the Keras blog post.
With data augmentation, every image is randomly changed in every batch. So the features are different in every batch. So you can’t usefully precompute something that always changes!
Thanks Jeremy. So is this limitation specific to the data augmentation ImageGenerator in Keras? When I think of data augmentation, it can also be done prior to training sometimes, right?
If I were given 1000 images, I can apply some image pre-processing like shifting, rotating, rescale, zoom on the images and create may be additional 4000 images for example. This will bring my training set to 5000 images which I can then use to pre-compute the convolutional layers. If I’ve some process that can do this, will it then cause any problems with pre-computing convolutional layers?
Yup you can do that - and indeed in the course I show how to do that with keras. However it’s not as good as having truly random augmentation, since you’ve limited your dataset size.
HI I was going through the notes of Lesson 2. I am trying to understand how the python implementation of log_loss works in the link http://wiki.fast.ai/index.php/Log_Loss. I tested the 2nd line of code “p = max(min(predicted, eps), eps)” which always returns the value of eps. The log loss returned by this function also remains constant when actual variable is 1 and 0. Am I missing something.
@VishnuSubramanian Good catch, that is a typo. The formula should be p = max(min(predicted, 1 - eps), eps). This line is to clip the probability (since log-loss is undefined for p=0,1)
In practice we use the numpy method np.clip, so I’ve updated the wiki to use p = np.clip(predicted, eps, 1 - eps) instead
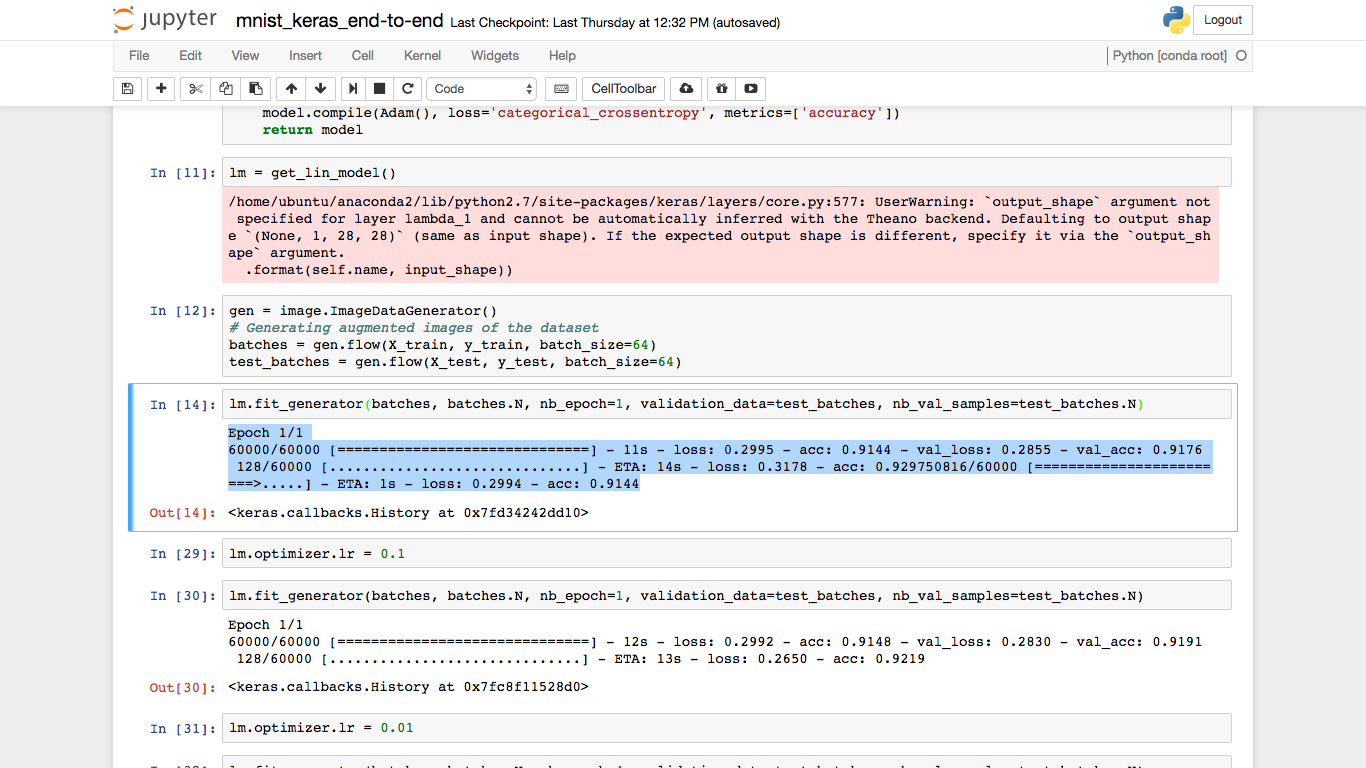
Hi @jeremy, I don’t know what is causing this error, but lately when I am trying to run fit_generator, I am getting a weirdly formatted summary. This is what it looks like.
Hi @kelin-christi, I am not an expert, but just looking at your screendump to me it looks like an issue of your Jupyter notebook configuration. I googled for “jupyter notebook line wrap” and it seems like you need to change your configuration file “custom.js”, but it is not clear from the posts where this file is located, I found several versions on my system. Does this only happen by “fit_generator” method, or is it a general probem of the output? Regards, Jonas
Jonas, thanks a lot for your reply. I figured it was a jupyter issue, so I just started a new p2 instance for the time being, and everything is running smoothly. I will however try to figure out what the issue with my previous instance was by medling with some jupyter settings/updating files. Thanks again
I’ve been working through lecture and the dogs_cats_redux notebook on the git and I am having trouble getting the vgg16 model to improve on subsequent epochs. It appears to me that it is “starting over” on each epoch instead of building upon the weights learned in the previous epoch. I have tried reducing the learning rate as suggested by Jeremy. Any thoughts?
The image shows my second and third epochs. The training loss and accuracy was similar for the first epoch (ft0.h5) as well. I’m using a NC6 instance on Azure.
Been working through the notebook for lesson 2. Ran into some error messages in regards to memory when running lines that call get_data. As suggested above I switched to get_batches. Well when you try to run trn_data.shape I get the following error message: AttributeError: ‘DirectoryIterator’ object has no attribute ‘shape’ So I checked out the get_data function and it uses the get_batches and then the return statement appears to be concatenating all of the batches. Thats the line that I believe is causing my memory issues. Below you will see the code I used to sort of play and isolate what I believe is my issue. Has anybody else had that error or might have some suggestions as how to over come it? Thank you.
PS I’m running this on my own machine NVIDIA GTX 1080 8gigs