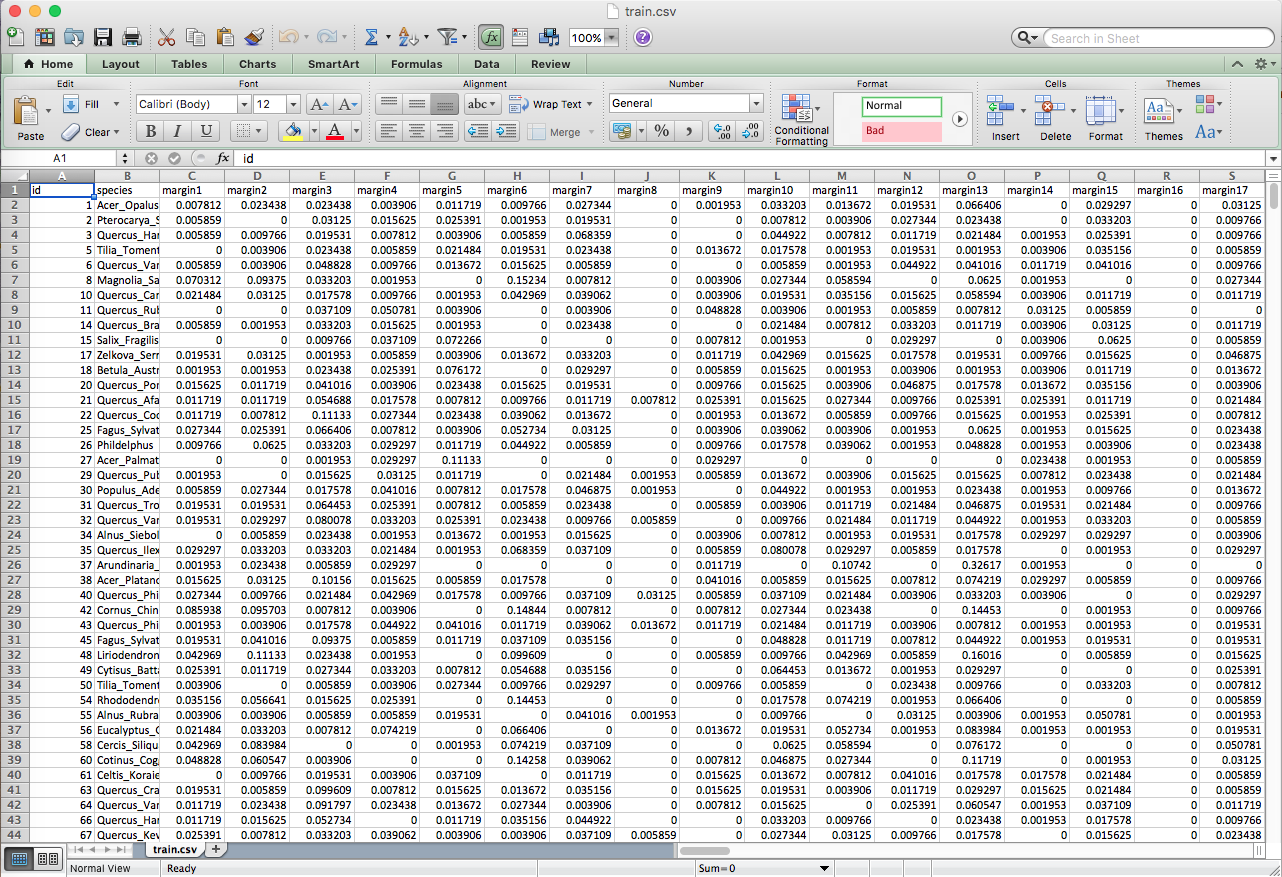
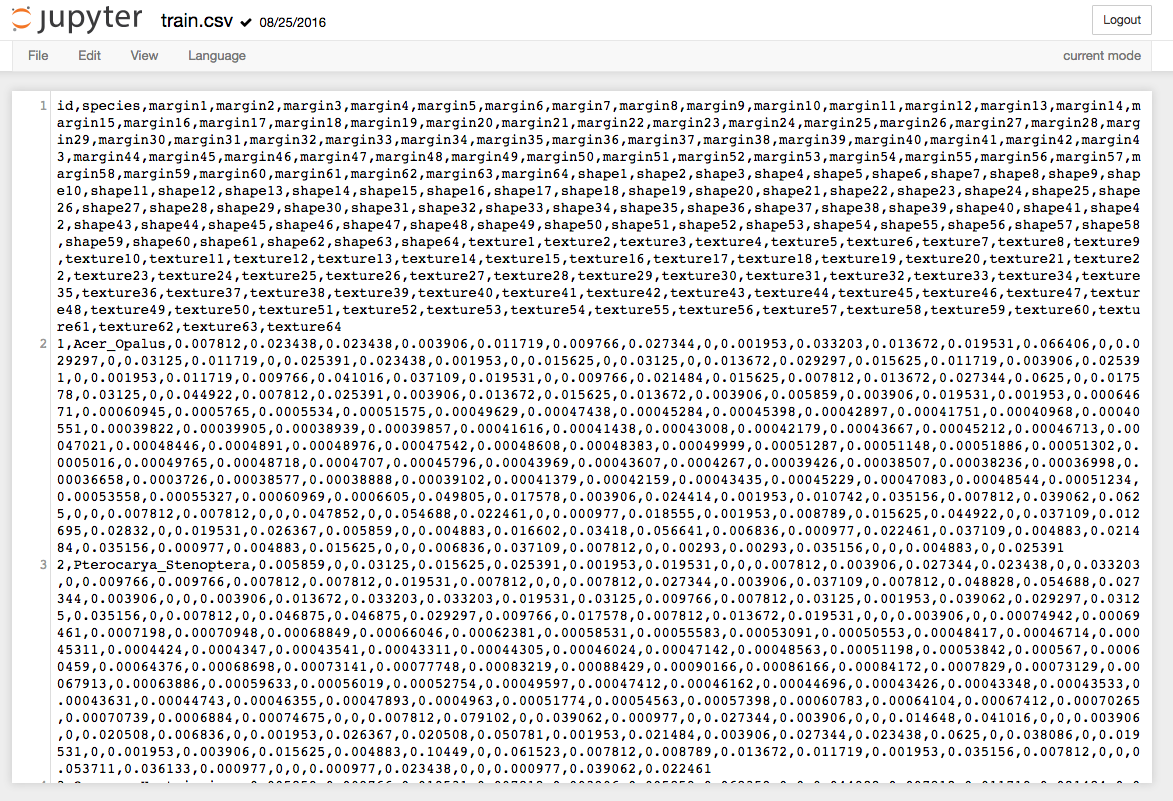
I’m currently looking at the Kaggle Leaf Classification Competition. They give .csv files for train and test, and a file of images called “images”. I am guessing that I need to use a system like you did with MNIST to filter the given image. However, I’m not exactly sure how I take the data (Image below) and access it in a script. I saw that for MNIST, you did “data = np.load(“MNIST_data/train.npz”)”. Why did you write .npz even though Kaggle gives the MNIST data as .csv?
I ran into a memory issue running the 2nd notebook on my p2 instance when using get_data(path + ‘train’) from the most recent utils.py. This is the output of free -m after loading train and valid sets using get_data:
total used free shared buff/cache available
Mem: 61406 56423 3294 8 1688 4576
Swap: 0 0 0
Even with a batch_size of 4 this didn’t leave me enough resources to run the rest of the notebook. However, I found that if I saved the arrays using save_array and then restarted the kernel and loaded the data using load_array, my memory usage was this:
total used free shared buff/cache available
Mem: 61406 29426 24046 8 7932 31572
Swap: 0 0 0
I was not executing the load_array lines on the original runthrough, so it’s not just an issue of duplicating the data. I was also not running any other notebooks or processes at the time. Any ideas what’s causing this behavior?
If you’re having memory troubles, use get_batches instead of get_data. get_batches only loads a batch of images into memory at a time. get_data loads the entire dataset into memory at once!
The lesson 2 notebook contains the code below for training multiple dense layers. What I don’t understand is:
This code doesn’t seem to call finetune (as is done in the code above in the notebook to retrain the final dense layer in vgg), so I think we would need to call it for all the dense layers when implementing this code for a particular model?
The note above this code in the notebook indicates to not skip the step of fine-tuning just the final layer first. Again, fine-tuning the final layer doesn’t seem to be called in this code, correct?
layers = model.layers
Get the index of the first dense layer…
first_dense_idx = [index for index,layer in enumerate(layers) if type(layer) is Dense][0]
…and set this and all subsequent layers to trainable
for layer in layers[first_dense_idx:]: layer.trainable=True
The earlier section ‘Retrain last layer’s linear model’ is where the final layer was modified and trained. The section you’re looking at uses the model that was trained in that earlier section.
I realized that I was confused conceptually with fine tuning and training. In particular, I was thinking that the code I referenced was designed to replace and retrain the additional dense layers in that model (beyond the first dense layer), when in fact it’s just retraining those additional dense layers.
In some cases we may need to replace (and then retrain) multiple dense layers, correct?
You only really need to replace the last layer, so that it’s predicting the correct number of classes. You can still retrain the others. The only reason to replace more layers is if you want to change the architecture.
In running a test case, I saw that onehot only encodes for the categories you give it, whereas to_categorical encodes for all categories between [0,max] for the max value you give it (even if you don’t use some of those values).
onehot(np.array([3,0,0,4]))
array([[ 0., 1., 0.],
[ 1., 0., 0.],
[ 1., 0., 0.],
[ 0., 0., 1.]])
to_categorical(np.array([3,0,0,4]))
array([[ 0., 0., 0., 1., 0.],
[ 1., 0., 0., 0., 0.],
[ 1., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 1.]])
@janardhanp22@rachel it so happens I was looking at this with @bckenstler today - it appears that to_categorical() is better, since (for the reason Rachel mentions) it will consistently encode the validation set and training set in the same way.
I took some time off work this week to go over the contents of the class, especially the code I didn’t have a chance to really seriously dive into. I decided to explore the ResNet model. I learned that to do this, first I had to save some VGG weights with which to build ResNet.
So I looked back at Lesson 2. I pulled out both the Lesson2.ipynb and the redux.ipynb. Both of them have the basic VGG model.
Starting with the lesson2.ipynb, everything is going great, the model is fine. The prediction are made here, and I believe should have a shape of (22500, 1000). I’m trying to return the basic ImageNet-style results, which consist of 1000 classes. But after
trn_features = model.predict(trn_data, batch_size=batch_size) val_features = model.predict(val_data, batch_size=batch_size)
I run trn_features.shape
which gives me (22500, 512, 7, 7)
Clearly, after the final conv layer, I’ve got 512 channels of 7x7. But I need to have the normal ImageNet output of 1000 classes, so I can send it into this linear model:
Why is the vanilla VGG no longer returning 1000 classes? Has the VGG class changed so much between weeks 2 and 7? I’ve rewatched tons of different parts of the videos, but most likely, I’ve absolutely completely missed something (probably fundamental).
Unless I’m misunderstanding, that doesn’t sound right. Are you using the model from http://www.platform.ai/files/nbs/resnet50.zip ? If so, it should download its own resnet weights automatically and then cache them on your machine.
Looking deeper at Lesson 2, I had a few general comments / observations:
There is one section in the notebook, titled ‘Training the model.’ I’m wondering if this might be a misnomer. We really aren’t training a model, at least not at that point. We are just running the images from the Cats and Dogs Redux through the pre-built VGG model. I was a little confused by this title back in Week 2.
Soon afterwards, we use val_batches = get_batches.
Then, we use val_data = get_data(path+'valid')
If get_data actually calls get_batches in it, are we repeating ourselves?
Finally, I can’t seem to stop my Jupyter notebook from timing out at the point: K.set_value(opt.lr, 0.01) fit_model(model, batches, val_batches, 3)
I’ve read that the solution is to disable the progress bar in Keras’ fit call since it is somehow interfering with pings from the notebook server to the AWS instance. I was hoping that by modifying out fit_model wrapper by including verbose=0 would do the trick, and indeed the progress bar is now absent, but unfortunately the timeouts are still happening (along the lines of WebSocket ping timeout after 119952 ms). I’ll keep battling it, but it’s cathartic to mention it here!
Thanks for the tip about the misleading title - feedback like this is very helpful for updating the notebooks for the MOOC.
get_data() used to take the return value of get_batches as its param, but I later changed it to take a path. So perhaps the earlier call is now redundant. Although I always like to have a batch generator available in my notebook since it comes in handy sometimes. So you’ll see this happen in lots of notebooks!
If your websocket isn’t responding after 2 mins, that’s a bad sign. Are you on a particularly iffy internet connection?
I think I don’t completely understand how we should use get_batches() to replace get_data(). If we simply replace it directly, it won’t work because get_data() returns array multidimensional array, while get_batches() returns a DirectoryIterator.
Also at this state, I’m not sure if get_batches() would help (since I’ve passed the lines where it uses get_data().
Do you have any other tips for this situation? Should we simply rent a bigger EC2 instance (I’m using P2)?
@jeremy So I am trying to figure out how to get the layer output visualization you showed in lesson 0. The 9 pictures that show what exactly the layer is looking for .
How do I get that sort of visualization for VGG ?