Thanks for the lesson! I went through the dog breeds competition exercise and was able to successfully submit a score on kaggle!
A gotcha that I had as a Windows user is that my csv submission was saved with line endings CRLF instead of LF which resulted in an error when uploading to kaggle:
ERROR: Unable to find 10357 require key values in the 'id' column
ERROR: Unable to find the required key value '000621fb3cbb32d8935728e48679680e' in the 'id' column
...
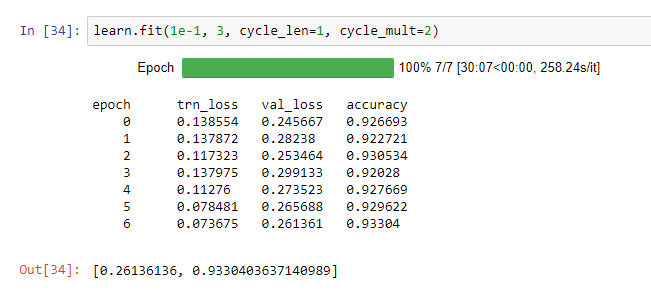
I followed Jeremy’s steps with some minor deviations (used a learning rate of 1e-1, didn’t use as many iterations) and got a score of 0.23567.
I noticed that used an additional method parameter ps=0.5 when creating the initial learner. What was the reason for this? (perhaps I missed it during the lecture video).
I also noticed that my training loss was a lot lower than my validation loss:
What would be the suggested approach to dealing with this?
Hey guys and @jeremy , I still struggle with the rationale behind starting to train and apply the model with precompute = True, then after that turn off precompute and train the net again with augs. After that process unfreeze the shallow layers and train it for another round.
My question is, why are we having a detour through precompute = True? Why not starting from scratch with creating augs, feeding it in a unfrozen net with precompute = False right away, when we have to do that either way? Is it only for saving time? Thanks for helping!
What does the f' actually do in label_csv = f'{PATH}train_v2.csv'? I realize that it has to do with files and the {PATH} expansion, but what does it do exactly? Are there differences in python versions / platforms?
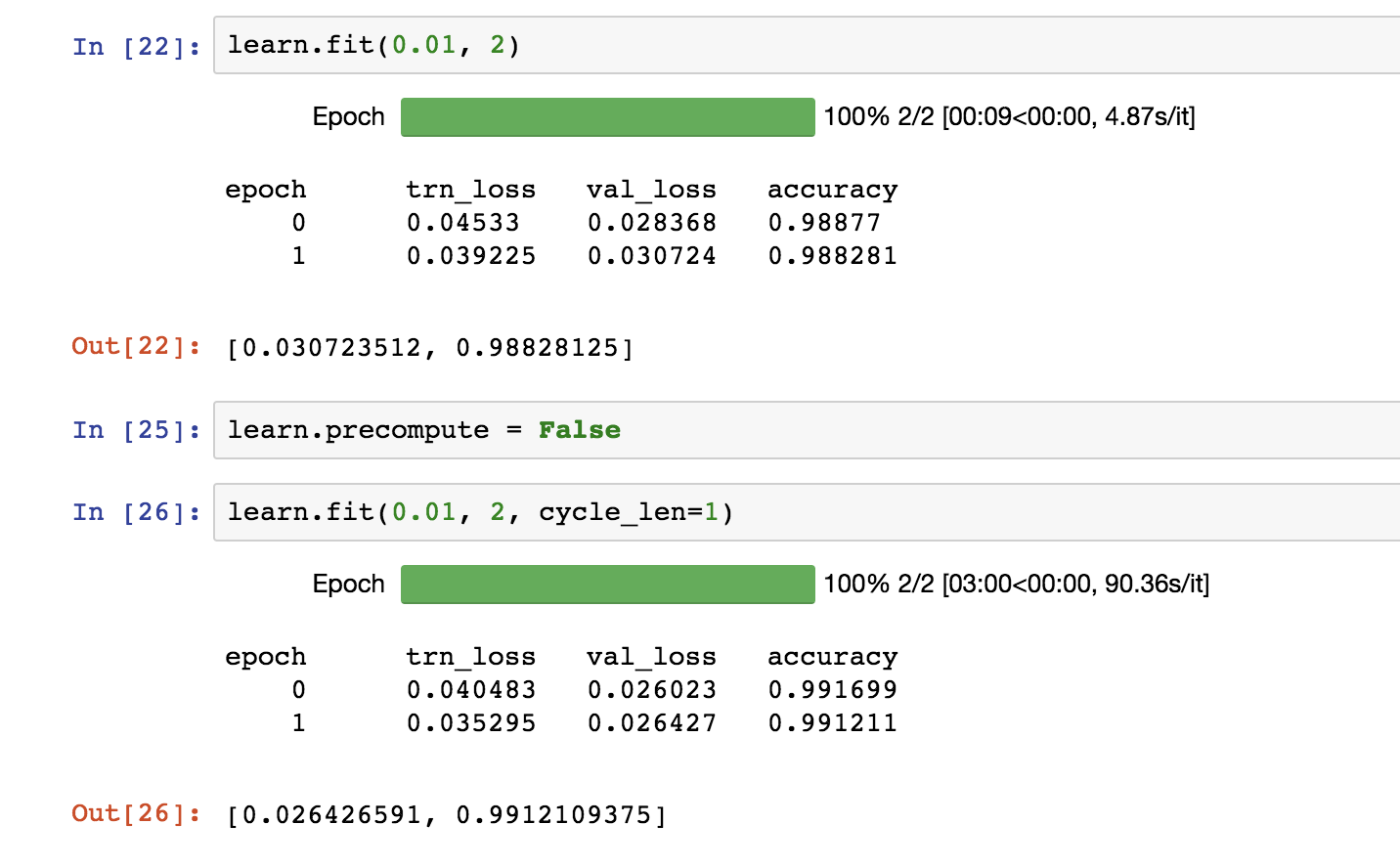
Hi all! I hope this topic is the right place for my question: when we set precompute to ‘False’, should learning slow dramatically?
In my notebook, with precompute set to ‘True’, learn.fit takes 9 seconds. But when I set it to ‘False’, it slows to 3 minutes. Is this normal? I tried my original lesson1.ipynb and it’s the same. Lecture 2 video doesn’t display learning time so I can’t compare to Jeremy :).
I figure that disabling precomputed activations would slow learning a bit, but I’m not sure if something is wrong since it is sooo much slower. Is anyone else’s acting the same way?
I am doing the dog breeds competition. My accuracy is kinda stuck at 84% and whatever I do max I got is 86%. how are Jeremy and others getting 92%? did anyone else face the same issue? Am i missing something?
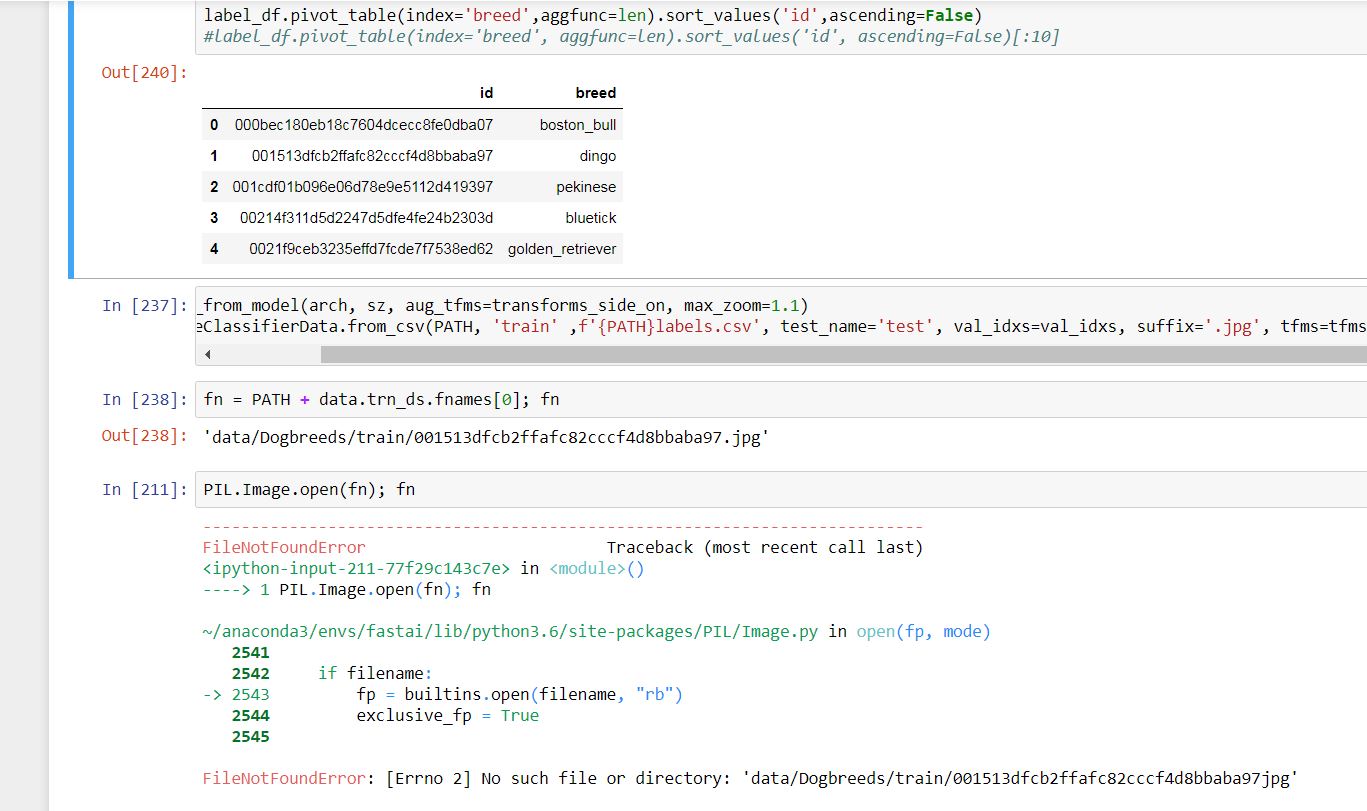
Instead of getting picture 000bec180eb18c7604dcecc8fe0dba07 .jpg as I correctly got in out[240] , I`m getting 001513dfcb2ffafc82cccf4d8bbaba97.jpg , which the next one .
but then in that case, why not just run the different learning rates on separate models to avoid this ambiguity and to be able to know for sure that no learning rate is benefiting from preceding ones and to be able to properly judge which learning rate is for sure the best?
in other words, rerun all the batches at the same learning rate but multiple times for different learning rates and compare?
Dumb question - at 1:35:00 ish you say that most modern architectures can handle images of various sizes.
I was under the impression that in order to feed forward an image through a network, it has to be of a consistent size. In other words, whatever architecture you have, the number of inputs has to match the number of pixels.
So if you have a CNN with 400 input nodes, then your images can only be 20x20 (or something that multiplies to be 400). Am I missing something?
How can you create one architecture that accepts images of varying sizes?
I got the same:
IndexError: arrays used as indices must be of integer (or boolean) type
But there’s no tmp folder. I set ‘val_idxs’ from a csv file.
can anyone suggest me how to fix it?
My label column is formatted as [‘36’, ‘19’, ‘66’, ‘153’, ‘164’, ‘76’, ‘42’]. I am not sure what’s the correct format for label column. do I need to format it as our csv file from planet: haze primary?
I was trying to reproduce the dog breed identification challenge.
Using AWS instance p2.xlarge. Downloaded the data set from kaggle.
Used learn.TTA() to predict the labels of the validation set.
learn.TTA() returns 2 values : i) log_preds (log probabilities ) ii) true labels
Strangely, the shape of the log_preds is (5 x 2044 x 120) . This produces error when metrics.log_loss() is calculated. The expected shape is (2044 x 120) because there are 2044 samples in the validation data set and its predicting the probabilities of 120 classes