Dumb question - at 1:35:00 ish you say that most modern architectures can handle images of various sizes.
I was under the impression that in order to feed forward an image through a network, it has to be of a consistent size. In other words, whatever architecture you have, the number of inputs has to match the number of pixels.
So if you have a CNN with 400 input nodes, then your images can only be 20x20 (or something that multiplies to be 400). Am I missing something?
How can you create one architecture that accepts images of varying sizes?
I got the same:
IndexError: arrays used as indices must be of integer (or boolean) type
But there’s no tmp folder. I set ‘val_idxs’ from a csv file.
can anyone suggest me how to fix it?
My label column is formatted as [‘36’, ‘19’, ‘66’, ‘153’, ‘164’, ‘76’, ‘42’]. I am not sure what’s the correct format for label column. do I need to format it as our csv file from planet: haze primary?
I was trying to reproduce the dog breed identification challenge.
Using AWS instance p2.xlarge. Downloaded the data set from kaggle.
Used learn.TTA() to predict the labels of the validation set.
learn.TTA() returns 2 values : i) log_preds (log probabilities ) ii) true labels
Strangely, the shape of the log_preds is (5 x 2044 x 120) . This produces error when metrics.log_loss() is calculated. The expected shape is (2044 x 120) because there are 2044 samples in the validation data set and its predicting the probabilities of 120 classes
After doing learn.TTA() , one needs to compute the mean to give the average of all data augmented images. After adding this line after learn.TTA(), I get expected results
Hi @jeremy ,
I am using an AWS p2.xlarge Instance.
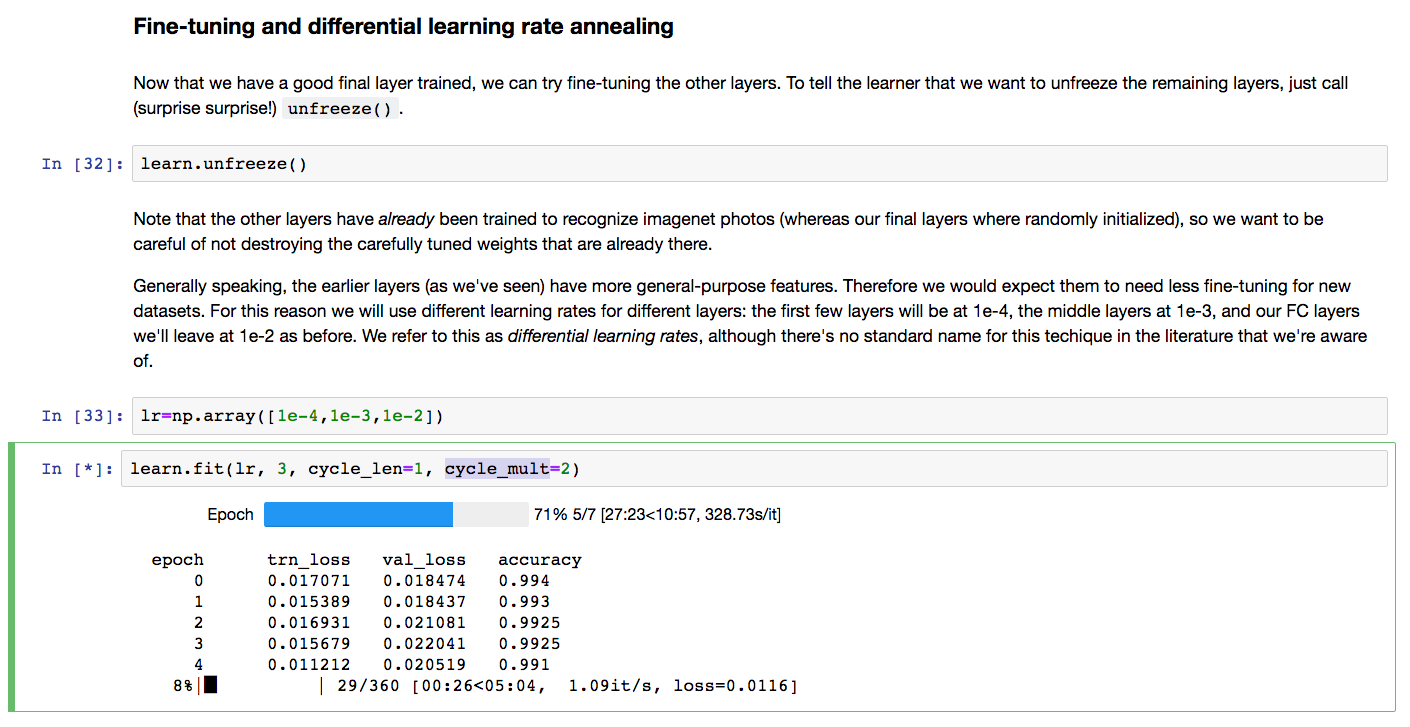
In lesson - 2, section 7.2
when I run the
learn.fit(lr,3, cycle_len=1, cycle_mult=2) statement, It is taking longer time sometimes more than 40 minutes.
May I know what is the normal time for running this statement in lesson 2 with a GPU?
Can anyone provide an snippet explaining how is it possible to unfreeze the first layers of a model and freeze the rest? I have network that I am going to train only the first few layers of it.