Just released the language model of Bangla from the wikipedia corpus. Performance can certainly be improved, as I have barely scratched the surface.
4 Likes
I haven’t started the Esperanto corpus yet and was wondering how long it is taking people to train their models (and on what hardware). How long did it take for you all?
For me one epoch takes around 1 hour 10 minutes. I have had 380.000 documents from Wikipedia as corpus.
Until now I have trained the models 10-15 epochs.
Hardware: 1080ti, 32 gb ram
1 Like
Swahili  : Progress so far.
: Progress so far.
I now have about 9.8 million words, with lots of nonsense from tesseract errors, mixed in with a number of single and double-letter OCR errors. I’ve used sentencepiece on a single file with 45560 words (calculated using cat file.txt | wc -w). I used a vocabulary of 30000, and the results (from sentences obtained from the same file) are promising. Now I just need to use the sentencepiece model as the source for my tokenizer. I’m writing this one up in a blog post because I’m quite happy with how things look so far.
Edit: I’ve just started a process to build a tokenizer from all 144 files.
Update: 231 files now, 10,439,411 words.
4 Likes
Just wonder do you come across performance issues when running the above codes? Based on the %time, it should be a quick process. However, it took over 5 minutes or so to run it for sample datasets (1000 items for training; 100 items for validation).
Most of them but not all. My teacher did not recommend one of them to us.  My favor book is The Art of War (孫子兵法). From my knowledge, few MBA courses study it for business strategies as well.
My favor book is The Art of War (孫子兵法). From my knowledge, few MBA courses study it for business strategies as well.
The following website offers lots of free Chinese e-books. Based on lesson6 RNN notebook, I trained a generative model using text from Su Shi (Chinese poet). It was a fun mini project.
1 Like
Try %prun and google for ‘python profiler’.
3 Likes
Using AWS p3.2xlarge, each epoch takes just over an hour for 100 million+ tokens.
Note: AWS offers alert services, so I can get an email if CPU is running below certain level. Normally, that means something went wrong.
5 Likes
I haven’t experienced performance issues at this step - it took a couple of seconds to run.
1 Like
Update on Xhosa language model.
@YangL and @Antti thanks for your feedback! it really helped.
I’m getting great results from my learning model! (they’re similar to the ones @jeremy had in the notebook).
I haven’t quite got my text to predict the next few words – working on that later today.
I’d like to put up a simple flask app on my website that people can use – if it works I’ll write up a tutorial. Having used Flask/Python years, I’m hoping this is a breeze.
.
9 Likes
Awesome! Can you do a Xhosa classifier?
3 Likes
Dope! Congrats!
I love flask: They’re small and simple.
Where are you going to deploy it?
Heroku is an absolute nightmare on fuel, and I’m looking for an alternative to pythonanywhere.
1 Like
I’m gonna deploy it on a private server, or last bet use Digital Ocean as I’ve done for most of my Python projects. Heroku is a big no!! I’d recommend Digital Ocean.
Definitely, I’d like to do that. I’d like to do a news classifier for classifying news items into their respective categories.
1 Like
thoughts on this Dataset for minority languages
Has anyone worked with http://wortschatz.uni-leipzig.de/en/download? It seems to be news articles translated into multiple languages and is designed especially for minority languages and training translation services.
@poppingtonic They also have Swahili – I’m not sure how useful this will be.
4 Likes
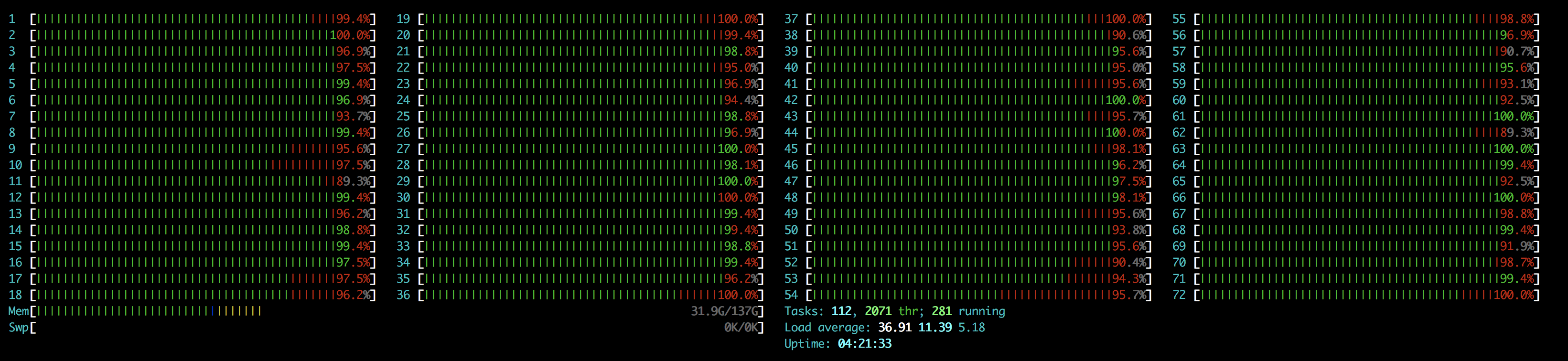
Decided to get a beefy non-GPU AWS instance to do my tokenization, happy to see all those cores working!
2 Likes
Also if you’re running everything in the cloud, I think this could be a more cost-effective approach than running tokenization for a few hours on your DL machine. I used a c5.18xlarge which is $3.06/hour on demand, and the tokenization took me ~5 minutes.
6 Likes
Very nice!
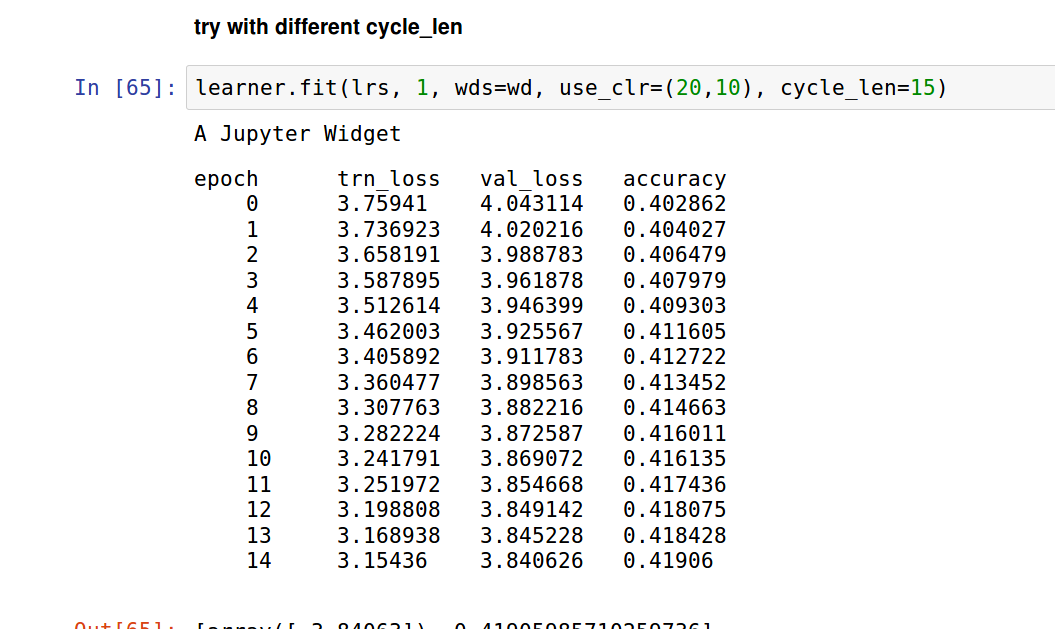
Would be interesting to compare results since I did Spanish too.
I extracted only the articles with more than 10,000 words each and kept about 1/2 of them for my dataset (this way my dataset was ~120M tokens large).
I used these params:
wd=1e-7
bptt=70
bs=32
em_sz,nh,nl = 400,1150,3
opt_fn = partial(optim.SGD, momentum=0.9)
drops = np.array([0.25, 0.1, 0.2, 0.02, 0.15])*0.5
lr=2 #used lr_find2 to find the optimal one
Then ran:
learner.fit(lr, 1, cycle_len=10, use_clr_beta=(10,10,0.95,0.85))
Result:
epoch trn_loss val_loss accuracy
0 4.243111 4.193037 0.257854
1 4.01907 3.969443 0.272689
2 3.908034 3.872785 0.278616
3 3.844105 3.821897 0.282531
4 3.803215 3.780296 0.285598
5 3.7653 3.746013 0.28916
6 3.780881 3.710472 0.293218
7 3.728705 3.676514 0.296869
8 3.685521 3.627796 0.303029
9 3.641547 3.587603 0.308747
Currently @cheeseblubber is running some experiments by varying the batch size and learning rate.
1 Like
Like I said on another thread, using gradient clipping (learn.clip = 0.25 for instance) can really boost your performance by allowing you to go to higher learning rates (gained 0.1-0.15 validation loss with that on wikitext).
And when you’re all done, you can use the continuous cache pointer described here for free and gain another 0.1-0.2 validation loss. I’ve implemented it and am writing a blog post/notebook to explain that I’ll share later today or this weekend.
It may be specific to wikitext, or the high learning rates I use, but I’m also gaining a few points by allowing a longer time to relax at the end: use_clr_beta = (10,33,0.95,0.85).
8 Likes