I’ll give it a try and will probably come back to the forums soon with a ton of questions! Thanks
FYI I found this recent baseline paper for Chinese language and the competition is opened till the end of this month.
2 Likes
btw I speak Mandarin fluently and read/write Chinese (Simplified mostly - but also Traditional) so if you wanted any help tackling Chinese let me know! This looks like an interesting challenge.
I wonder if characters could be treated more like images for the CNN to recognize? I know when I am reading Chinese its kind of like an instant recognition of the whole character as one unique “object” which is quite different from reading English or other phonetic-based languages.
Most Chinese characters, especially with Traditional, have a meaning component aka the “Radical” and also a phonetic component. In fact, to look up a word in a Chinese dictionary the process is to first search for the radical - and then in that subset of that radical you locate the word based on the number of strokes. So I’m also wondering if the characters could be broken down in some meaningful way to capture these features which are embedded in the characters.
1 Like
I’ve begun to train a French Language Model on Wikipedia.fr (well part of it). Tokenizing always made me run out of memory so I’ve changed a bit Jeremy’s functions to save the tokens on each chunk instead of concatenating them in one big array. All the details are in this notebook if someone has the same problem.
I discovered afterward that I had 600 million tokens so be sure to listen to Jeremy’s advice regarding this!
I’ve begun to train with high learning rates (it will go up to 8!) and Leslie’s 1cycle policy. First results are looking good since the first epoch gave me a validation loss of 3.98 and 27,7% accuracy (one epoch is 33K iterations though). I’ve launched a cycle of 10 epochs (might be a bit of an overkill since it represents 330K iterations) and will share the results tomorrow!
7 Likes
That’s exciting - no-one has looked at this before AFAIK so there’s probably a paper to be written there, if you’re interested (and I’m happy to help if wanted). I think it would basically be a case of doing lots of experiments to show how 1cycle impacts learning rates, gradient clipping, and regularization in AWD LSTM and NLP classification. Ideally you’d find you can decrease the regularization quite a bit, which should help particularly where you have less data.
6 Likes
That sounds super interesting but I’m not sure I would know where to begin. Let’s also see the final results first, the training has plenty of time to diverge yet 
To get an idea of what represents good results, what was the validation loss (or perplexity) and accuracy of your final model trained on wiki103 we finetune after?
You may find this paper interesting. Enjoy 
You really know how to appreciate the Traditional Chinese characters. I was born in Hong Kong and studied ancient Chinese literature. While I am still working on the “modern” Traditional Chinese, hopefully, the future step is to build the language based on 四庫全書
1 Like
So I couldn’t resist launching another machine on the same training but with less epochs overnight. In two epochs (still 64K iterations), I got a validation loss of 3.53 (perplexity 34.28) and an accuracy of 31.5%.
To detail the steps that led me there, the model is exactly the same as in the imdb notebook, and I took the dropouts Jeremy shared
drops = np.array([0.25, 0.1, 0.2, 0.02, 0.15])
I didn’t use Adam since it doesn’t seem to work well with high learning rates, so my line for opt_fn is:
opt_fn = partial(optim.SGD, momentum=0.9)
I admit I forgot the weight decay, so I just ran the lr_finder (the version 2 to avoid running for a full epoch since it’s sooooooo long) and here is the plot
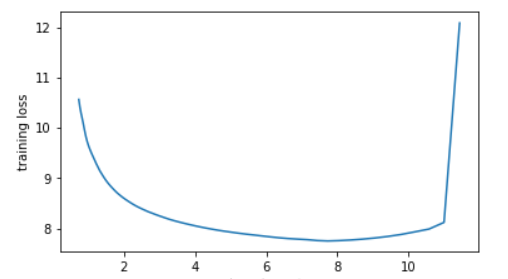
10 sounded a little bit too dangerous so I picked 8 for my maximum learning rate, then ran my favorite line
learner.fit(lr, 1, cycle_len=2, use_clr_beta=(10,10,0.95,0.85))
And here are the results for a cycle of length 2:
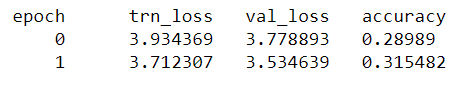
Now waiting for the cycle of length 10 to be completed on my other machine, but it’s already at 3.48 of loss on epoch 6, so it should be better.
I’d love to test this on the wiki103 set, since there are benchmarks available. Jeremy, if you have a mean to share the numericalized version of it it would be tremendously helpful since I wouldn’t have to spend the day tokenizing it.
6 Likes
My beginning step would be to ask Sebastian Ruder to help us 
I didn’t find a great way of comparing, because I found that depending on dropout I could get the same effectiveness after fine-tuning on imdb for a wide range of different ppl and accuracy on wt103. Ppl of anything under 50 is pretty great. Here’s a table from smerity’s latest:
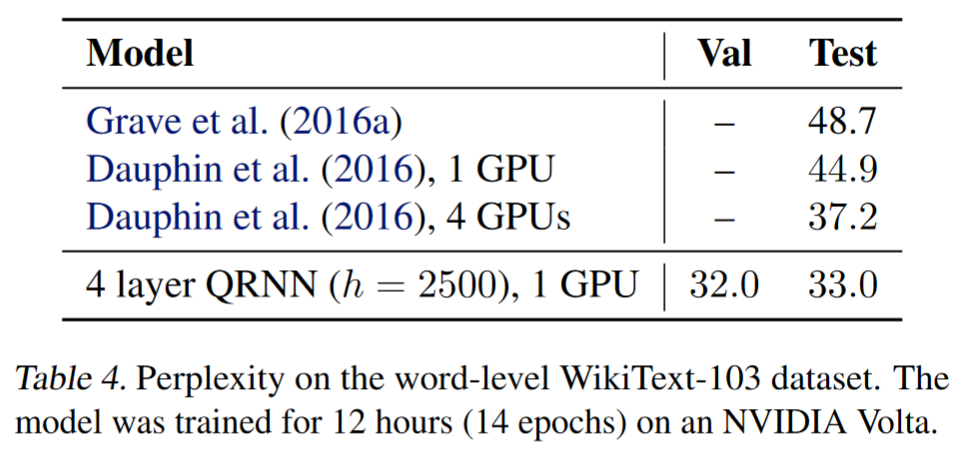
5 Likes
Let’s ask him then.
Not sure if you saw my earlier post since we replied at the same time, but training didn’t diverge and gave some pretty good results.
Again, not sure if you saw my earlier post but if you happen to have your numericalized wiki103 available it would be great for me to begin testing on this dataset.
2 Likes
For Swahili, I’ve collected a set of 1573 pdfs from Tanzania’s Parliament website. I wrote a bash script to read all of them in sequence, convert the pdfs to TIFFs, and extract the raw text using tesseract, and so far this has got me 101 files from the hansard, totaling about 4M words, obtained using cat * | wc -w. This is already bigger than Wikipedia, but there are OCR errors that make this estimate inaccurate, and mistaken tokens might be elided when tokenizing by using min_count=3 or something like that. The process is ongoing, and I’ll be updating the dataset in multiple phases until we get to 10M.
7 Likes
I didn’t see that - quite terrific! Looks like you should be able to drop your dropout by a lot and get much better ppl, FYI.
I’ve popped the numericalized file and vocab here for you: http://files.fast.ai/data/wt103_ids.tgz
3 Likes
 that would be amazing if you could create your LM based on 四庫全書! Have you read all of 四大名著?I used to read a lot of those books when I was in school
that would be amazing if you could create your LM based on 四庫全書! Have you read all of 四大名著?I used to read a lot of those books when I was in school 
Also thanks for sharing the paper on using CNNs for classifying sentiment in Chinese text although it looks like they are just using 1D CNNs as an alternative to RNNs. I was still thinking to use RNNs but instead of just using a tokenization from Unicode I thought perhaps it could be possible to treat each unique character as an image (represented by CNN feature extraction) and so in the same way that video is a sequence of images here we are applying the same technique with the RNN only it’s a sequence of feature-rich characters.
1 Like
Thanks for the files!
I hadn’t realized that the vocab size for the Language Model wasn’t truncated to 60k words like in our fine-tuning (which makes sense if we want it to be as general as possible) so I can’t use the same batch size (128) and it’ll probably impact the loss since it’s harder to predict one word out of that many.
Speaking of which, training on a longer cycle the French Model (10 epochs) with very high learning rate allowed the model to find a better minimum: the final validation loss was 3.33 (27.9 perplexity!) and the accuracy was around 33%.
On all my experiments, Leslie’s 1cycle policy works best when we train a new model from scratch than when you finetune something, and it can give you a decent model very fast with super convergence, but it’ll also gain in precision if you let the cycle be longer. And 1 long cycle is far better than two shorter ones in a row.
2 Likes
Oh I apologize I didn’t mean to give you that one - my attempts at using a larger vocab didn’t result in better models, and were much harder to train. I’ve uploaded a replacement now to the same place with 30k vocab. That’s what I used in practice.
BTW when we don’t use the same vocab size as a paper we’re comparing to we can’t exactly compare, since it impacts the difficulty of the problem. Also, IIRC French is an easier language for an LM. Will be very interested to hear how the en model goes with similar settings - that fr model result is really encouraging.
2 Likes
Try using sentencepiece. Should give the a nearly-optimal segmentation.
1 Like
Do you recommend using sentencepiece in a situation where one does not have a readily-available tokenizer? I’m buliding a Swahili AWD-LSTM model on Wikipedia, fine-tuned to the Hansard I posted about earlier, but spacy doesn’t have a model for it, and there are no publicly available tokenizers.
30k words is much easier indeed, thanks for the new file. I can now go to a batch size of 256 and even higher learning rates! 
2 Likes
Ndiyo!
4 Likes