I’m working on the Amazon dataset using my own computer with a Titan Xp. I have trained the network using the images. First with the size of 64, then I increased it to 128 and finally to 256. When training the data set with images with size 256, during the first epoch, Jupyter Notebook gives the next message:
Kernel Restarting
The kernel appears to have died. It will restart automatically.
I also tried to check if the issue could be reproduced using the dogcats data set and that is the case (for this I had to copy the data set multiple times in the same folder). It occurred after running:
I found out that the cause of the freezing is that the CPU RAM is full and the swap is as well. The CPU memory is used during the batch training process. The memory use is (linearly) increasing. So it looks like something from all batches is kept in memory during training. And space used by former batches is not freed.
It also looks like if only during the first epoch the memory usage increases this much.
I checked if the GPU is used and that is also the case.
I found the issue several times less explicitly in other topics on the forum, but nowhere a solution was given. When googling, I could not find the same issue when using solely PyTorch. So I hope somebody can point out if I made a mistake or if this is an issue of the fastai library (or PyTorch library).
Hi @BartP, I am having the same issue with the same dataset. I am also using my own computer, which is an i7 16gb of ram, and a gtx 1080ti with 11gb of ram. I tried only changing the size to 224 instead of the 256 and I still run into the kernel died problem. I was thinking about going out and getting another 16gb of ram just so I know I’m able to get the best results.
I also ran into this same problem in the dogs vs cats supercharged notebook with the image size at 299. For that one I just changed it to 224 and it ran perfectly.
If you don’t mind me asking, what are the specs of your computer?
Thanks,
Bill
edit:
I did double my ram for a total of 32gb and have been able to successfully run through the planet notebook with the default batchsize and image sizes. Also note that my accuracy increased 2% with the slightly larger images.
Also, the dogcats supercharged notebook which uses resnet model used to give me the same kernel shutdown error with the image sizes being 299. After doubling my ram I was also able to successfully run through that with the default 299 image sizes.
Thank you for responding.
I changed the code, but for me it doesn’t work. I think the cause (loading all batches in memory) is the same, but I changed the dataloader with your code. I checked if the new code has been imported in Python and that was the case, but it did not change the memory usage.
@, I have an i7 with 16GB of RAM. Increasing the memory does onlysolve the problem for some datasets. Increase the size twofold and the problem will arise again.
@Alex.Nikitin, this does not solve the issue (it might solve OOM-errors for gpu’s). The problem seems to be that after each batch the memory used in that batch does not seem to be freed. So this solution does not solve the issue.
Thanks for you investigations guys! Loading everything in RAM seems like a doomed approach sooner or later as datasets increase…
I’m having the same issue when trying to use ImageClassifierData on the google landmark training data (500k+ images) on paperspace with 30 GB of RAM and 8GB GPU mem. Kernel dies even with sz=64 and bs=4
EDIT: Oh, and Farhan’s fix isn’t helping me either. Worth a try, thanks anyways…
Even I am working on replicating the planet classification challenge on Google Landmark Recognition Challenge (will use softmax instead of sigmoid) on Kaggle. It fails at the get_data(sz = batch_size) step even for a batchsize of 16. Fills up all the RAM and crashes(then restarts) the notebook. Is there a way to lazily load a batch at a time? The dataset is about 336 Gb large and I am working with 56 GB RAM + K80 graphics on Azure’s NC6 VM.
It’s possible that ThreadPoolExecutor is being used elsewhere too. I faced the issue in lesson1.ipynb. I used tracemalloc to drill down to the exact location that was allocating memory. It was the np_collate() function which was being called by thread pool executer’s run() function. In my case it was happening when creating batches and saving them. It’s very likely that the same is happening when loading the batches for training.
I think there are two seperate issues here. Farhan’s workaround is for issue 184 which manifests in DataLoader.
I believe the issue I’m experiencing with the Landmark dataset is the same one Bart and Deepak reported (at least all symptoms are same). It manifest before DataLoader is used. I’ve pinpointed it to dataset.py:138 in the label handling and am looking to fix it.
I did a temporary for the ThreadPoolExecutor problem, while keeping multithreading.
I just copied the _DataLoaderIter object from pytorch and added a few lines. I hope that a better solution can be found soon.
Did anybody find out why python changed this behavior?
Yeah, I know. Making predictions seems surprisingly memory intensive :-/. I haven’t had an in depth look at it. There might well be an easy mitigation like the one in the PR above. I have only worked around the issue by predicting in smaller batches. Which is a pain.
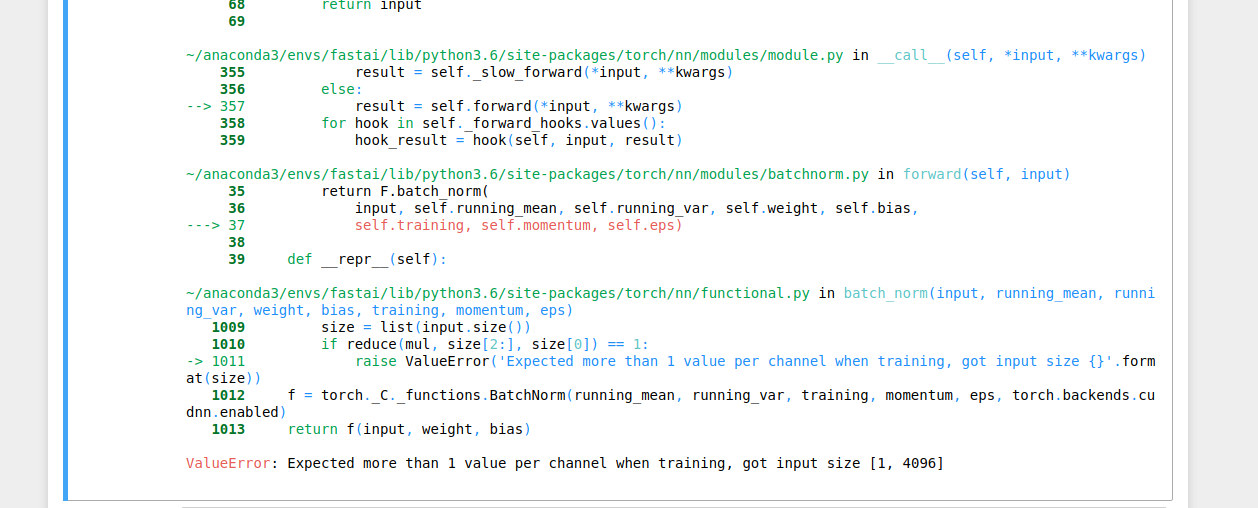
Yea. During validation, my kernel jus dies, there are around 20000 images of 1mb each, might be causing the problem. Any idea how do I stop the kernel from dying during validation? Running GPU+ instance on paperspace (8gb vRAM with 30gb ram)
With ConvLearner.pretrained (resnet34), GPU memory usage was 30%, (batch size 48), but all 32 GB of RAM was eaten up and virtual memory usage grew to 80 GB before the Kernel crashed.
After Farhan’s fix:
With ConvLearner.pretrained (resnet34), GPU memory continues to remain 30%, (batch size 48), but only 3 GB of RAM is used and virtual memory is at a steady 20 GB (no Kernel crashes).
Just checked with the fastai repo, so right now when using 0 workers it will not load all into memory, but if you try multi threading it will. If the fix works I could submit a pull request @jeremy
cheers Johannes
Okay so it was zipping along fine during training and seemed to make use of multiple threads while not keeping every batch in memory, but then failed at the end of the learn.fit() call with the following err: