Hello,
I’m currently on lesson2 and seem to be a bit stuck on the using the vgg model for a Kaggle competition - Cervical Cancer Screening. I plan on using this competition as my testing ground for new techniques learned throughout the course and thought perhaps others would to so I wanted to start a thread to share thoughts and progress.
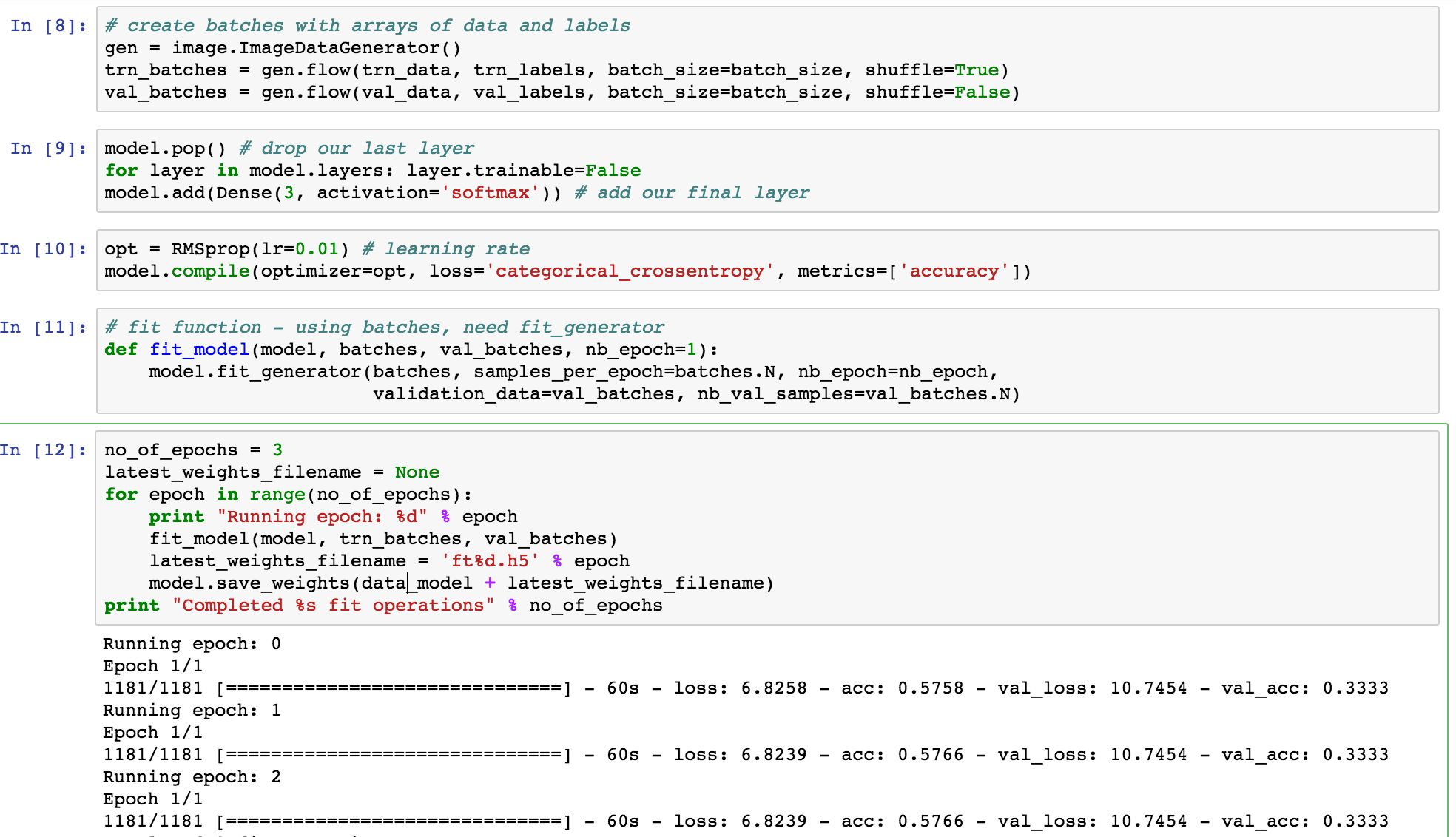
Any ways, I’ve attempted to use the technique of dropping the last layer and adding a linear model to Vgg16. However, my validation loss is coming back with what looks like abnormal numbers and nothing I do seems to improve the val_acc over 0.5 or val_loss under 2.0
From the below image is there anything weird that stands out?
(the competition has 3 categories “type_1, type_2, type_3” which is why I’m using Dense(3, activation=‘softmax’)
If I remove 2 layers (model.pop() twice) I do get better results but still a high val_loss…
I haven’t looked at that specific competition, but my guess is that VGG16 trained on imagenet is going to contain learned kernels that don’t work nearly as well on medical imaging data. It’s been trained to classify animals and objects in the real world, so transfer learning at the final layer where the kernels are more specific to that domain is unlikely to work. It works great for cats and dogs because they’re a part of the imagenet dataset that the model was initially trained on.
It does raise an interesting question though: Are there trained weights for VGG or any of the other common transfer learning architectures that have been trained on medical imaging data and are available for transfer learning?
One option would be to use the pretrained weights as a starting point and then retraining the whole net. My guess is that’s going to overfit unless your dataset is big enough, but it’ll probably work better than just transfer learning.
I was thinking that’s the reason why removing the last two layers worked better than removing just one - the last layer looked for breads of dogs and cats but the one before was more generalized (faces, ears, etc).
Although, that brings up a question…At some point, flowing up the model, should already be trained for things like circles and patterns which would be useful for this competition. Instead of retraining the entire model, just remove all layers up to that point, then add and train new layer(s).
But how does one know how many layers to remove? Trial and error? The art of data science?
In any case, I’ll try out some things and do some googling of trained weights for VGG (thanks for the suggestion!)
I was thinking that’s the reason why removing the last two layers worked better than removing just one - the last layer looked for breads of dogs and cats but the one before was more generalized (faces, ears, etc).
That’s exactly correct
One option that probably makes sense here and is much less extreme than removing the layers is to just make the existing layers trainable. Where to draw that boundary in terms of training/removal is an open question that depends heavily on how close the problem you’re working on is to the original problem that the architecture was trained on.
Hi,
I’m also interested in this competition, looked in to it today for the first time. However, this specific one (and medical imaging competitions in general) are not the perfect one to use as playground for the course. In the following lessons (spoiler alert Jeremy will talk about the state farm competition And the fisheries competition, which are more user friendly.
Having said that, from looking at the images (I also recommend reading an explanation about the types in kaggle forum) you can see that
Images are noisy, shot from different angles, blurry, with obstacles
Type 1,2,3 is determined by examining color and shape and hue of specifc part of the image
Images are in high resolution
So what I would try is detecting and cropping the importent region, and than classifying it (possibly with training some top layers of vgg)
Looking forward to hear about your progress
Thanks @shgidi, I’ve just started lesson 3 and looks like I jumped a head a bit on the trying to use VGG for this competition, but experimenting and failing is good, right? lol
But since I do have more of an interest in this competition than state farm or fisheries, I think I’ll stick it out and try to apply all of the lesson 3 learnings and kaggle forum tips (a few other people are using VGG as well) to practice new techniques and try to improve my score.
Hey @saiprasanna, originally I used only the 5Gb training data.
However, I’m finishing up lesson 3 now and it has great notes advice/tips. Plus I’m also going to try building my own CNN from scratch to train with the additional data (not using VGG) just for experimentation.
I’ve also entered this competition after finishing the course. On the kaggle forums you will find that there are duplicates in the test and train sets, so remove them from the train set. Also it was reported that for these duplicates some of the labels were different in both sets. So that is not very encouraging .
So I just noticed that this is only in the additional data set, which is lower quality and that the problems have been since corrected.
I’m not planning on using the additional data yet because the kaggle discussions are quite negative about it, it doesn’t seem to improve score. But later I might try to mix it in a little bit and see if it improves things. But it hasn’t got my focus.
First my main challenge is fitting a model on 1 GB GPU… which seems impossible.
Hey all, made it to top 31 % with log loss of 0.91
I am under fitting, I use data aug + high dropout, maybe I should try reducing dropout and overfit?
Will tuning stuff like beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0 of Adam optimizer be of any help or should I do that suggested thing of bounding boxes etc?
I don’t like the idea of using bounding boxes, doesn’t seem to deep learning-ish magic.
@jeremy any hints , I know this is a competition though
I think bounding boxes will be important, since the outer areas of the images contain a lot of irrelevant pixels. You could even consider a fixed bounding box. But I’m no where near your results so take that with a grain of salt
You could try Jeremy’s “heat map” that he shows in the last lesson to see if your NN is focusing on irrelevant data or not. If it is then cropping and/or bounding boxes will help.
 Jeremy will talk about the state farm competition And the fisheries competition, which are more user friendly.
Jeremy will talk about the state farm competition And the fisheries competition, which are more user friendly. , I know this is a competition though
, I know this is a competition though