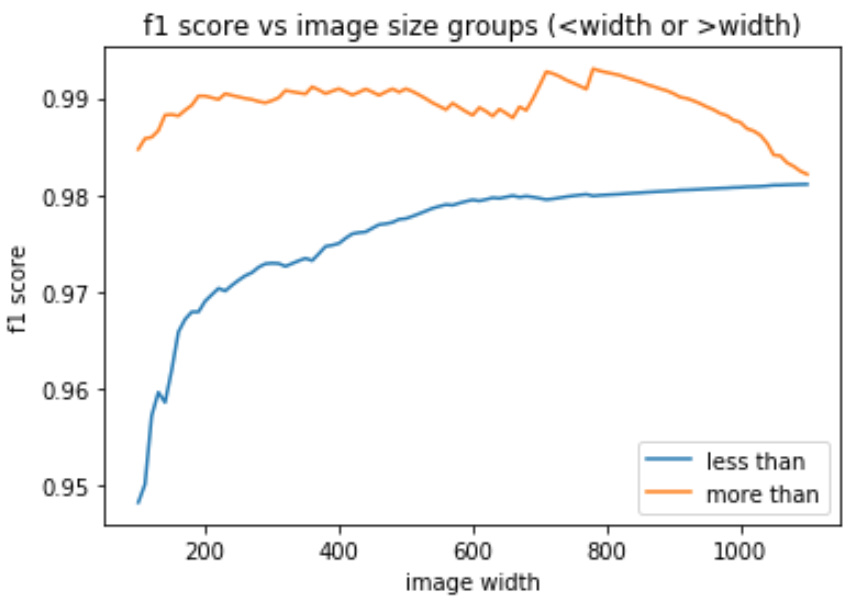
Thanks, @jamesrequa. Black-grass turned out to be the worst category with f1 at 0.87 only. Sad news is that local cv does not correlate with leaderboard.
2 Likes
Indeed - but can you see why?
(I’ll give you a tip - do the same prelim analysis that I showed in class for the dog breeds comp, and it should be obvious).
1 Like
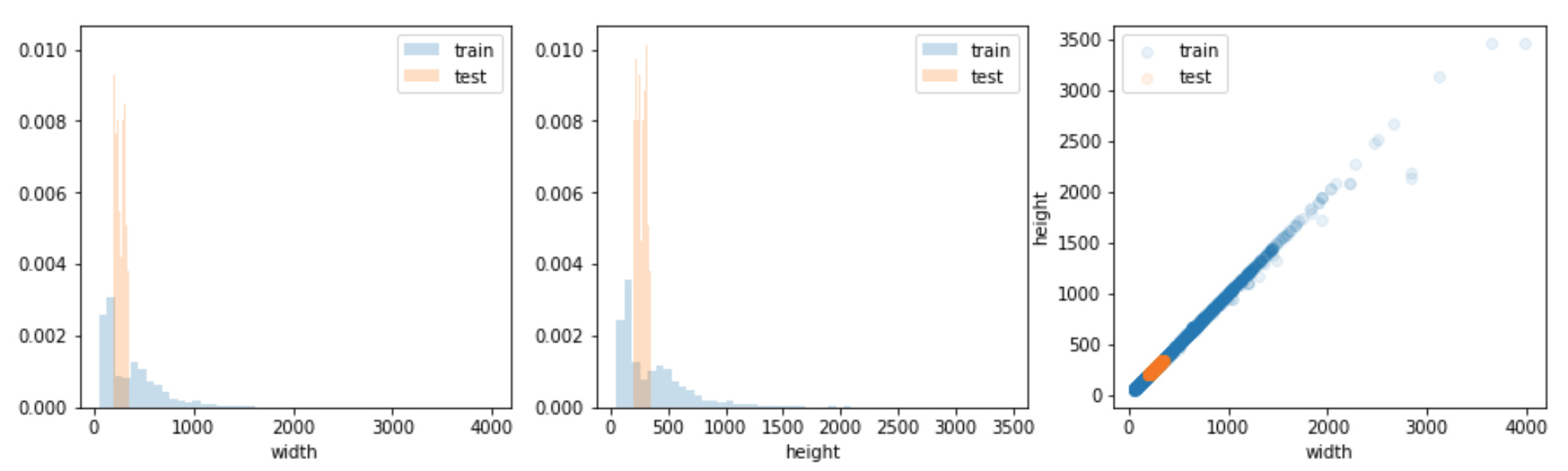
Jeremy, frankly I do not see an obvious answer so far. I have a couple of hypothesis but non of them if being true can help me to do something about it:
- train set is relatively small
- I do 5-fold cv, so I cant improve the accuracy of my validation score
- images sizes vary significantly but still look similar train-test
- we have one category with significantly lower predictive accuracy, but its imbalance can only make valid-leaderboard scores different, not uncorrelated
- f1 score is step function, it shows improvement only if prediction for correct label becomes max amongst others
Obviously I am missing something
One of those 5 bullet points is incorrect - so you should check your assumptions 
1 Like
You should show that in a kaggle kernel or at least forum post @sermakarevich if you have a moment, since that’s an important insight that we should make available to other competitors
3 Likes
Done.
1 Like
Was the 3rd bullet point wrong?
Couldn’t follow which one is wrong?
Nice Visualisations…
Yep, it turned out I was checking train images width vs train images height 
Can you post a link to the kaggle kernel here?
Nope, there is no kaggle kernel, just a post with two pictures which are already here, so nothing to share.
Is anyone ensembling models in this competition ? I’ve tried averaging ove probabilities gotten from two models with very similar f score on leaderboard but it gave the worse result than either of those models.
I’m averaging the probabilities of each k-fold. It improved a bit my score.
4 Likes
Have you compared that to simply retraining on the full dataset? If so, did you see much of a difference?
1 Like
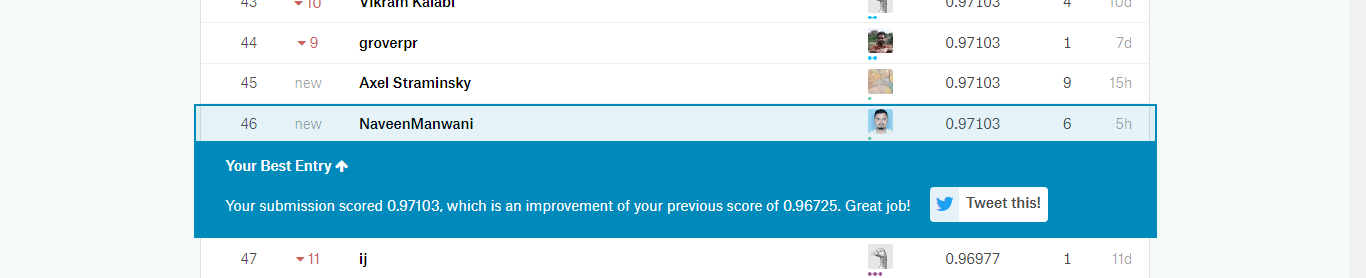
Yes, I got 0.98488 (2nd place) on the leaderboard using the full dataset. To tell you the truth, it’s not clear to me why the averaging result was better (0.98992, 1st place), but it worked! 
Maybe if I had just picked the best fold I could get a better score, I don’t know.
4 Likes
There’s a nice explanation here in case you haven’t seen it: https://mlwave.com/kaggle-ensembling-guide/
edit: Oh, you averaged the folds, I thought you were bagging
1 Like
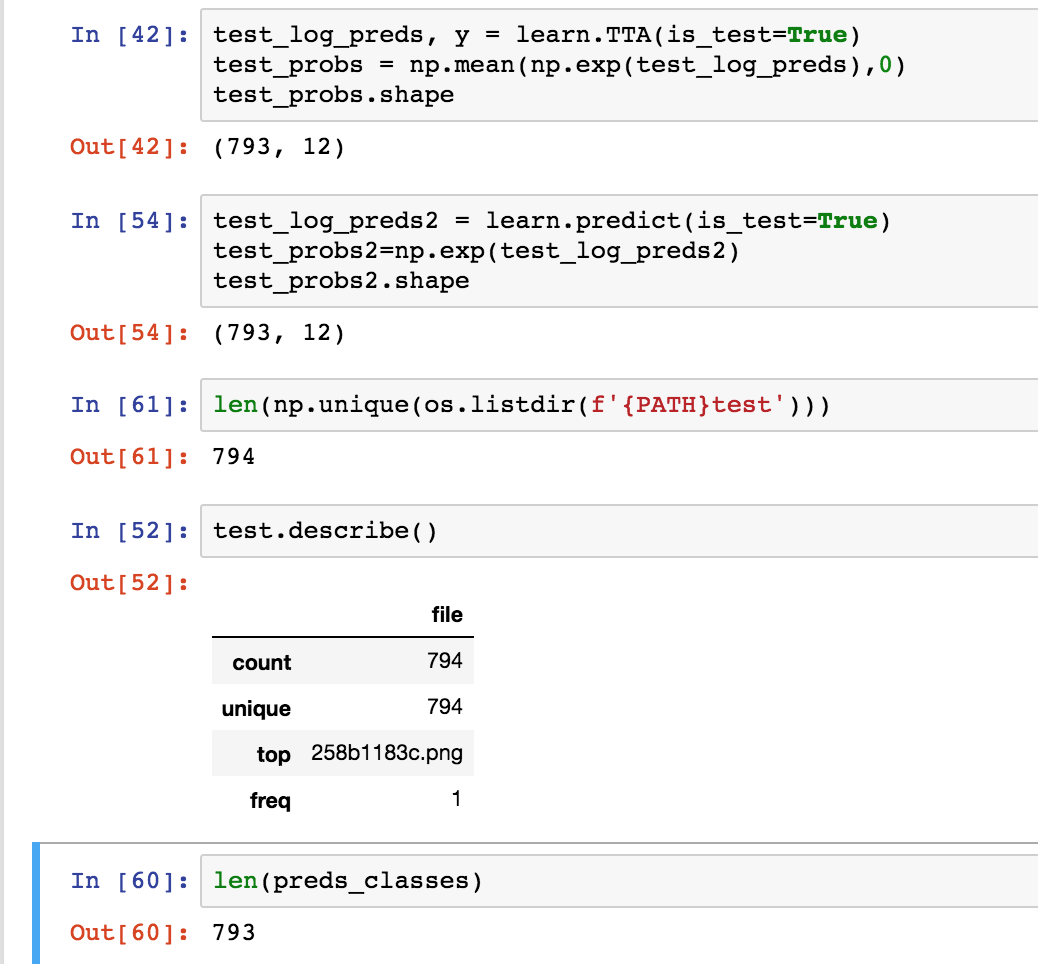
The test set contains 794 samples, however, when I run learn.TTA(is_test=True) or learn.predict(is_test=True), I keep getting 793 predictions instead of 794 (see attached ss). As a result, I am unable to create a submission file due to the mismatch in counts. The correct number of rows is 794 according to the Kaggle site. Has anyone else experience the same issue.
2 Likes
Yeah, I am facing this issue too
2 Likes
Can you ensure all files in os.listdir have extension .png ?