I’m trying something a bit different in terms of software development process - here’s my attempt to document it.
What we’re doing is to create notebooks which start with a fairly specific solution to a particular problem, and then we show how to gradually refactor and generalize that solution. At the end of the notebook, we hope to have a solution to the class of problems of which the initial notebook section showed one specific instance. Also, the last section of the notebook should show that different types of model/dataset/etc can be tackled with only a small amount of simple code for the user.
Then when that all looks pretty good, I download the notebook as a python file, remove all the code that isn’t necessary for the final approach, and save that as a module. The notebook names start with a number (eg 002), and the python module created from that notebook is then named eg nb_002.py.
When I start the next notebook (eg 003), I start by importing everything from (eg) nb_002.
The net result of all this is that we build up over a few notebooks a complete solution to some problem (such as “create a training loop”, or “do data augmentation”). Once we’ve got a good solution to a whole problem domain (like computer vision), we can combine the various modules build along the way into a well-designed set of one or more modules, which we can then add tests and docs to.
Some reasons for this approach include:
I work best in an interactive notebook environment
We can include pictures, tables, etc so that people understand exactly what’s going on, and we can have visual “tests” of correctness
I’m planning for the next version of fast.ai part 2 to be a “bottom up” approach, where students learn how fastai is made and why it’s made that way. The notebooks we create as we build fastai_v1 will form the basis of this.
The only problem with this approach, is that overtime this will lead to divergence between the original notebook and its .py derivative - sometimes one modified, sometimes another. We don’t have to travel far for examples of that in v0. One will either have to be very strict to always update both with any change, or perhaps there can be some facilitation added to the notebook so that its .py derivative is always autogenerated and is never edited directly. Thoughts?
I’ve just finished going through the 001a_nn_basics.ipynb notebook and I think it’s fantastic!!
A couple of notes:
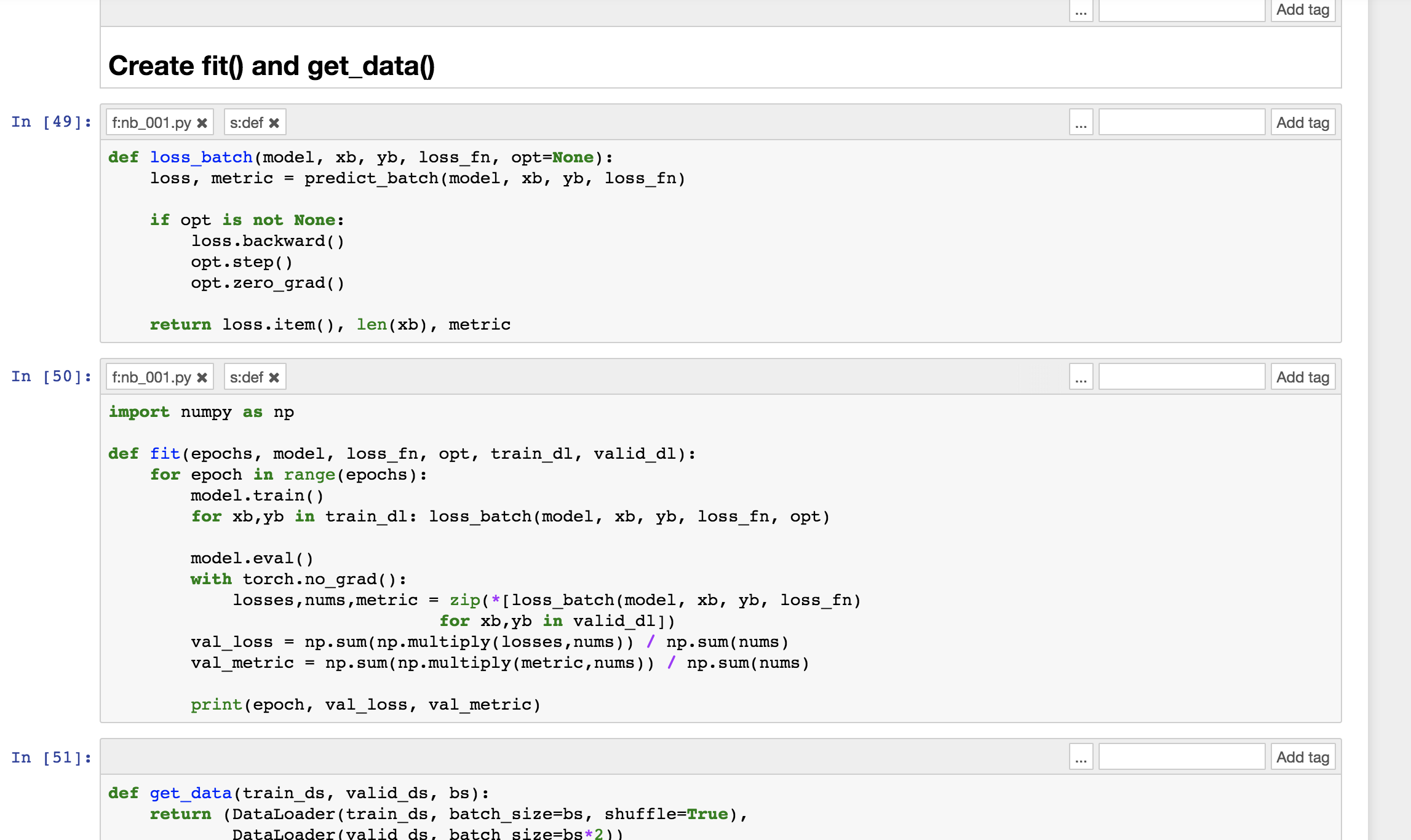
1.) The function fit takes the loss_fn parameter but it isn’t used in the method since the loss_batch function doesn’t take that parameter and always uses loss_fn.
2.) In the section Create fit() and get_data() the data loaders train_dl and valid_dl are defined, yet in the next section Switch to CNN the first batch is still gotten in a couple of different places via indexing
loss_fn(model(x_valid[0:bs]), y_valid[0:bs])
but it seems it might be more instructive to use valid_dl to get the batch.
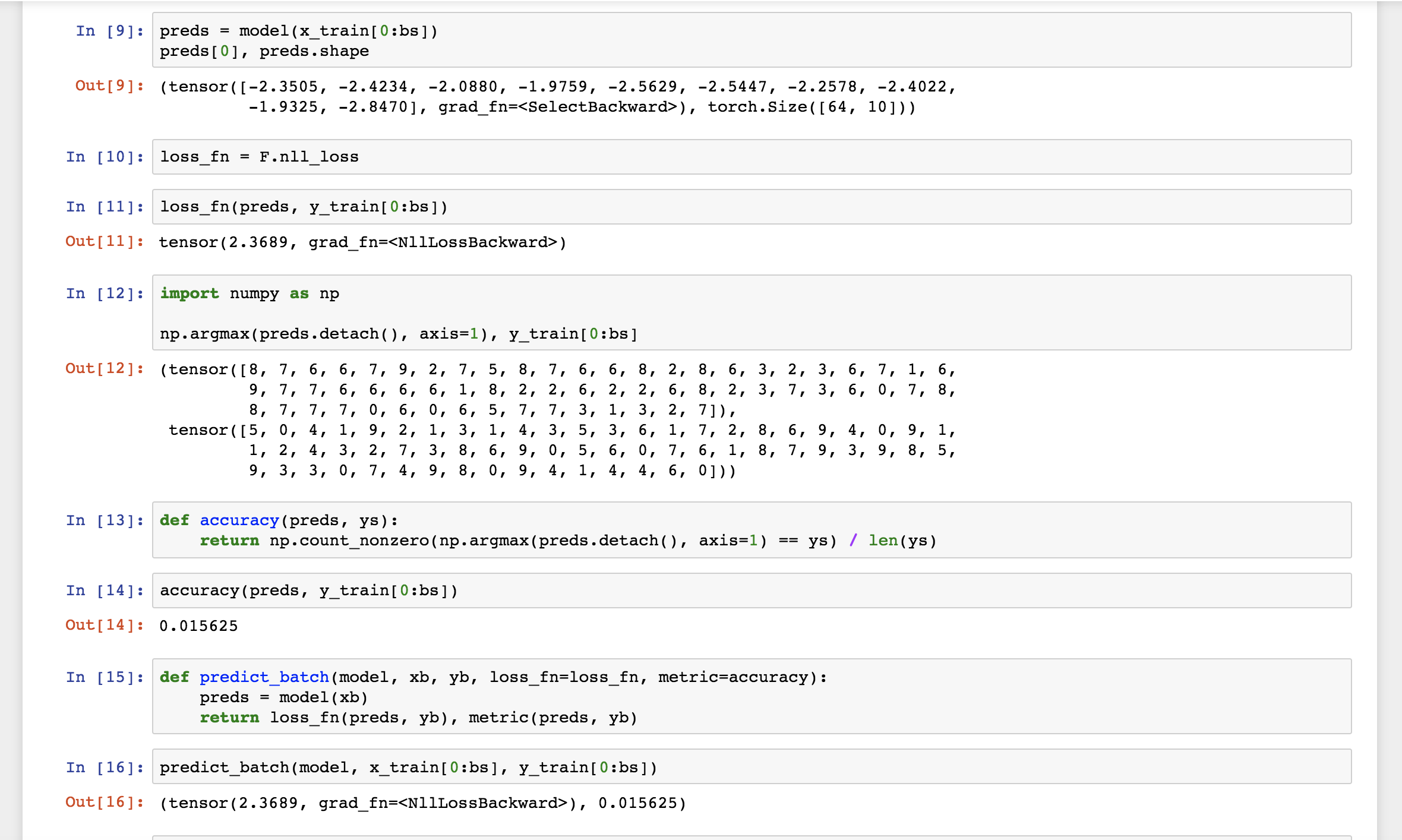
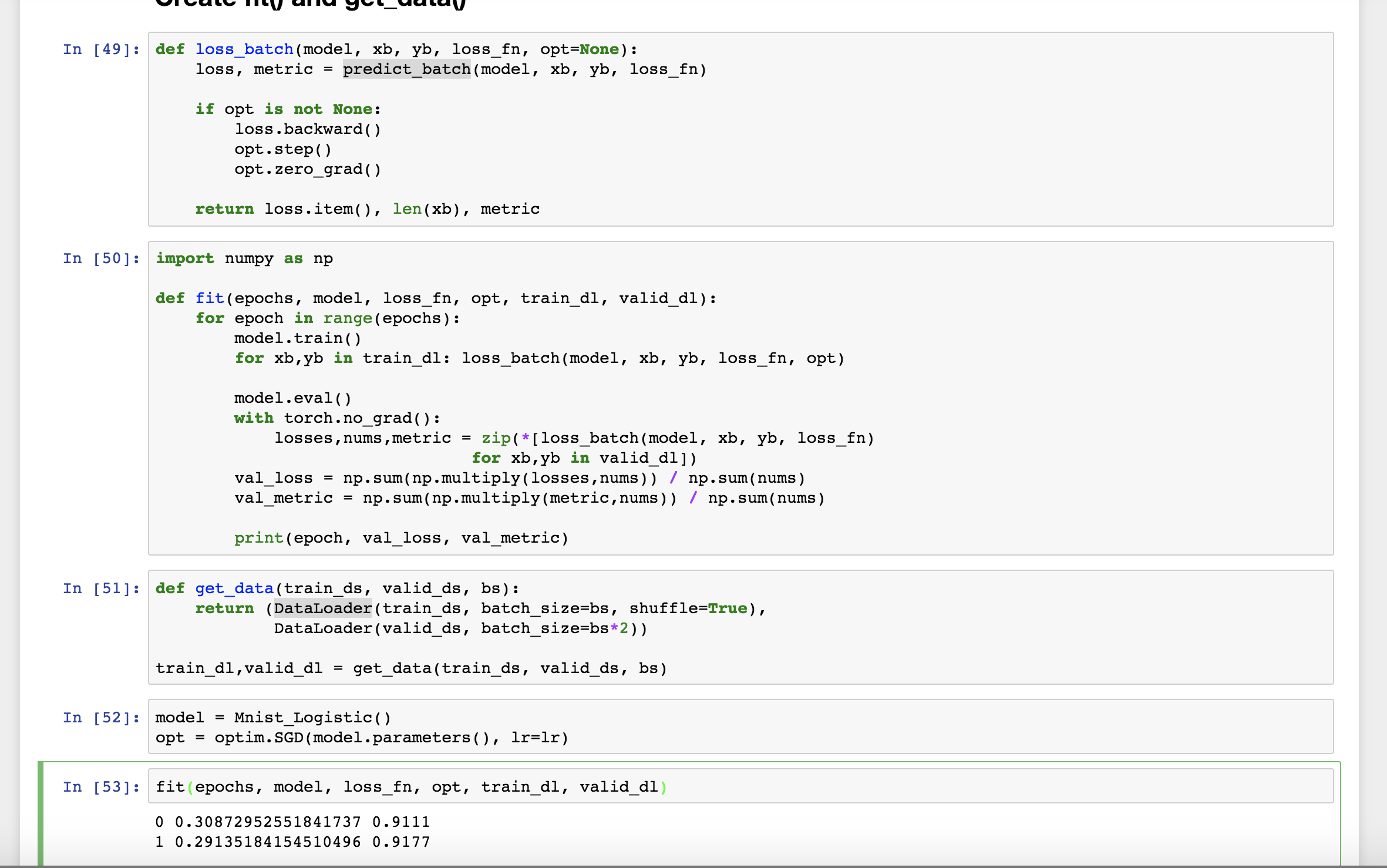
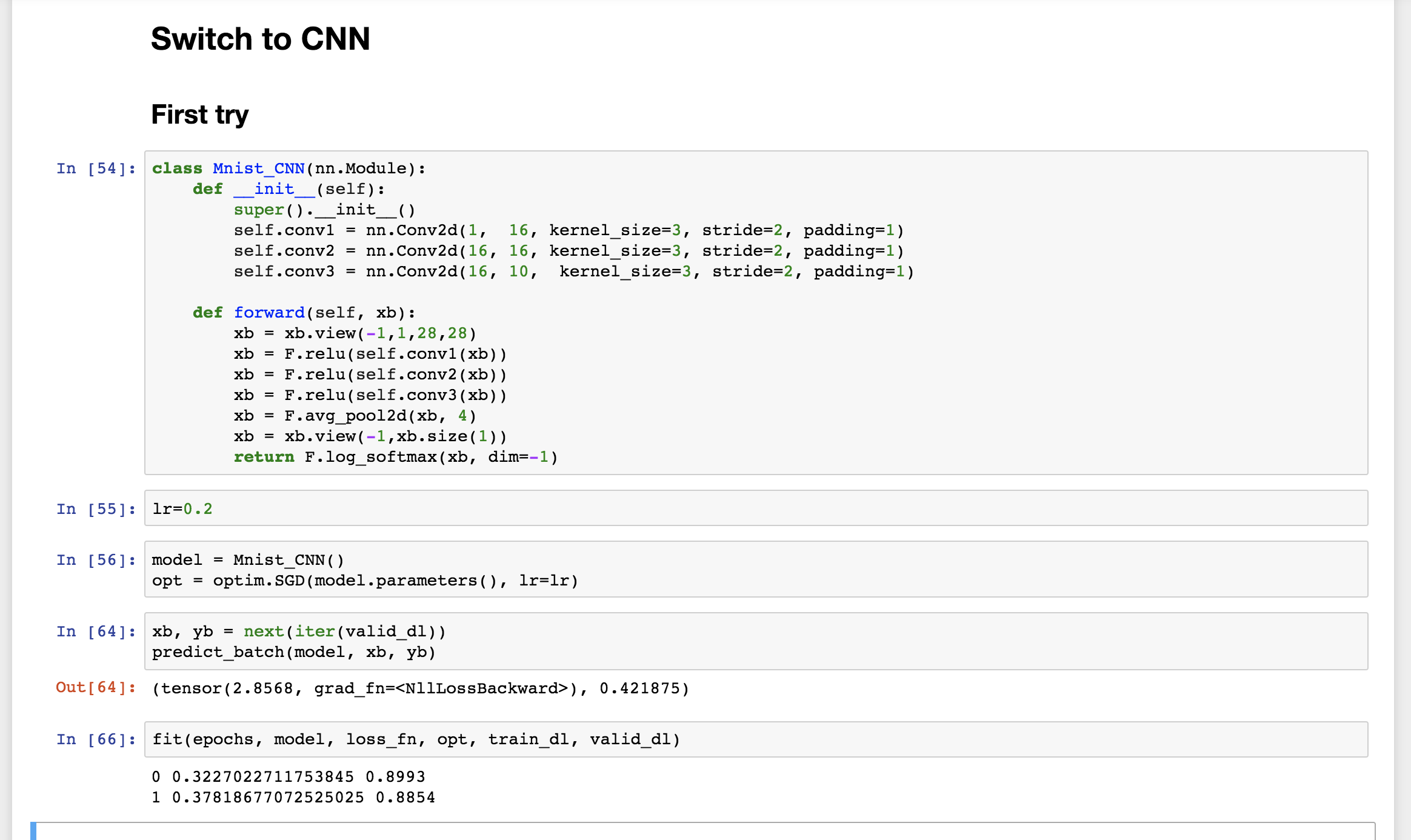
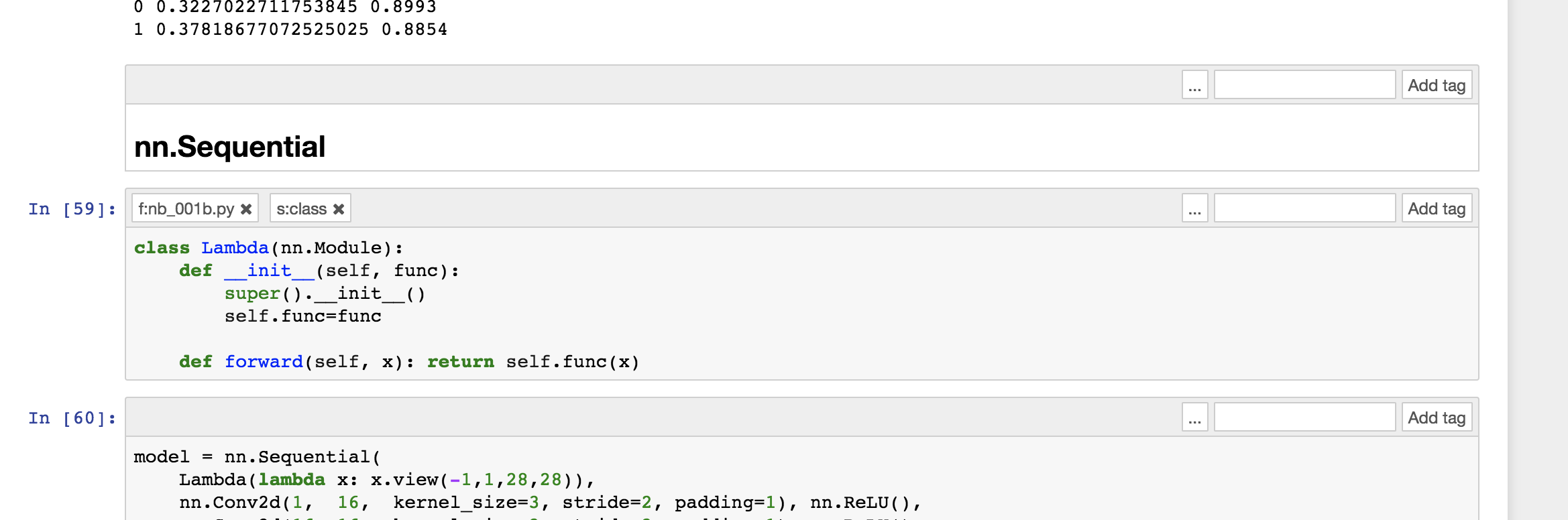
3.) This is a little bigger change and it may have been omitted for simplicity reasons, but it seems it might be useful to also show how to view/interpret the predictions and calculate accuracy. The images below show what I’m suggesting with the predicted digits vs. the target digits, an accuracy function and a predict_batch function and then the predict_batch is used throughout the notebook to calculate the loss and the accuracy in place of loss_fn(model(x_valid[0:bs]), y_valid[0:bs]). The loss_batch method is also modified to use this method and the fit method is modified to also output the validation accuracy metric.
@stephenjohnson these are great suggestions! @stas do you want to add these to the naming PR? The only thing I’d suggest is avoiding using numpy in the accuracy etc stuff - the plan is to use tensors wherever possible.
@jeremy, can you please merge what has been submitted so far and then it’ll be easier to do other tweaks gradually and others like stephenjohnson could submit bigger changes as well - thank you! I’d like to nail the namings first.
@stephenjohnson, could you post the actual code with the suggested changes in #3 - thank you
Oh I like that idea! We could add a comment or some cell metadata to cells to include in the .py file.
OK let’s do it. How about the make the first line of a cell #EXPORT if we want to include it in the py file?
Do you want to try writing a little script to do that? The ipynb files are just json, so when I’ve written similar scripts in the past I’ve just used the python json module directly (or, if required for performance, ujson). Or I think there’s some official jupyter libraries you can use to access them, but I haven’t tried that myself.
Will fastai_v1 require Pytorch 0.4.0 or 0.3.0? For some reason, Pytorch 0.4.0 no longer supports my GPU but it also has newer features (and I can still run it on Paperspace) so I’m kinda torn either way.
Just ran the first two notebooks, the ‘Refactor using…’ sections are a great add and focus on one concept at a time. In 002b, the TODO mentions metrics, are these performance based or things like the confusion matrix, MSE etc.
You mean there will be just one #EXPORT, and everything else under it will be be exported. Otherwise that’s going to be a lot of #EXPORT cells.
Hmm, perhaps it’d be easier to simply have a new notebook for just that? So instead of one long notebook there will be several parts - ala ml1/*rf series? And the last one will always be 00XX-99final.ipynb or something similar. And to convert it to .py we already have tools for that. ipython nbconvert --to=python.
Since it’ll need to have all the imports/dataset loading/etc/, it can’t build upon the earlier parts of the notebook anyway.
so now we will have:
001a_nn_basics.ipynb
001b.ipynb
001c-final.ipynb
Also, currently nb_001b.py only has functions in it, it doesn’t have a “running code”.
in the first post you wrote:
The net result of all this is that we build up over a few notebooks a complete solution to some problem (such as “create a training loop”, or “do data augmentation”). Once we’ve got a good solution to a whole problem domain (like computer vision), we can combine the various modules build along the way into a well-designed set of one or more modules, which we can then add tests and docs to.
So why does nb_001b.py at the moment have only functions and none of what you wrote above?
and we also need to think about docs and tests as you describe above - do you already have an idea of how this would be implemented - because this information is needed to complete this design issue - can we supply tests/docs using notebook - or somehow have them work side by side - perhaps we can use 001 as a guinea pig and build test/docs right away? (and then not worry about it for the rest if you feel it will delay the development at this stage)
edit: I think I have a better idea. The last notebook will be .py, and .ipynb will be auto-generated from it. I see there have been all kinds of attempts at py2ipynb out there but they require a pretty noisy input (indicating what kind of cell the following code should go to). I was thinking to simply split the code on double new lines to create distinct cells. Or perhaps we could have a simple ###\n tag that will stand for split here… thoughts?
I personally like - (minus) separator for filenames, keeping _ is for variables in the code.
and consistent case? s/Cifar/cifar/?
and I suppose you decided to have notebooks starting with 00X for future lessons, and non 00X (Cifar10-) to cover supplementary topics which won’t be directly worked on the new editions of fastai MOOC, correct?
Finally, can we have better hints in the name of the notebook of what it is about? e.g. img-reg (image regression), img-class (image classification), structured-classification, etc.
In v0 at the beginning it’s very confusing when notebook names only have the name of the kaggle competition or what objects they work with (rossman, cats-dogs, dog-breed). these are all fine and easy to refer to, but perhaps some abbreviation added to what type of a problem they are trying to solve: reg/class and type of input (img/nlp/structure).
With respect to exporting notebooks. We can write custom templates and preprocessors for nbconvert. So for example if we need to include a single cell, it should start with ‘#EXPORT’ and if we need to include multiple cells, then they must be wrapped in ‘#EXPORT START’ ‘#EXPORT END’ block. In case one of the cells must be excluded inside that block, it should start with ‘#EXPORT EXCLUDE’ or something. That probably should work, but need to test it on one of the notebooks, to see how that looks.
There’s an recent alternative to Jupyter notebooks that work very well for me in rapid explorations: Pycharm’s scientific mode using code cells. Essentially you can use ‘#%%’ to divide a python script into cells that can be executed just like Jupyter notebook cells, with the output sent to the Python console and any plot displayed in the Plot pane. You get the full power of an IDE (or just your favorite text editor) to support refactoring and such. Once the python script is more or less stable, you can export it to Jupyter notebooks and share with others.
If you don’t love editing text in a browser, you should look at Pycharm’s scientific mode.
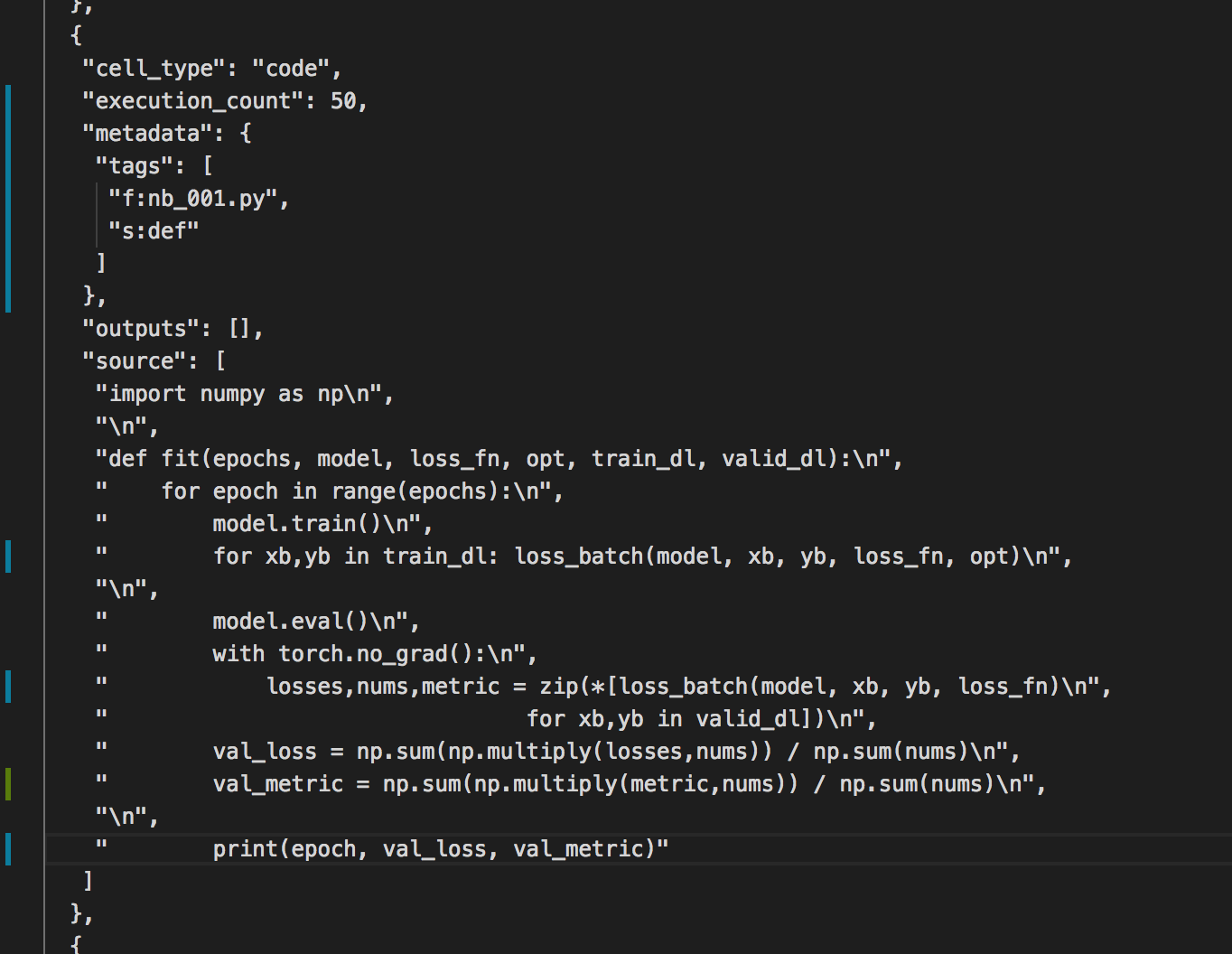
Here’s a thought. How about using tags instead and the tag can be the filename of the .py file that the code should go into. Additional tags can be added to specify other directives when including the code into the file such as a tag for which section of the file the code should be included in. For example, an import section at top, all top-level defs in a def section next and a class section last with the items ordered alphabetically within each section. This way the tags can be hidden and shown when desired. For example, students could show the tags to learn which file that code is in but hidden during lectures, etc… Also, by using the filename you can export the code to whichever file is desired not necessarily tied to that particular notebook. The tags are then easily retrieved from the metadata section of the json. Some screenshots below. The prefixes indicate the directive. For example, f: prefix is “file” and s: prefix is “section”. Just a thought.
I was going through 002_images.ipynb notebook. I came across the line torch.ByteStorage.from_buffer in pil2tensor function. Quick search on google did not help me understand what it does. Can someone help in undesrtanding why we are using it and what it does.