I’m trying to understand the region proposal network in faster rcnn. I understand what it’s doing, but I still don’t understand how training exactly works, especially the details.
Let’s assume we’re using VGG16’s last layer with shape 14x14x512 (before maxpool and with 228x228 images) and k=9 different anchors. At inference time I want to predict 92 class labels and 94 bounding box coordinates. My intermediate layer is a 512 dimensional vector.
(image shows 256 from ZF network)
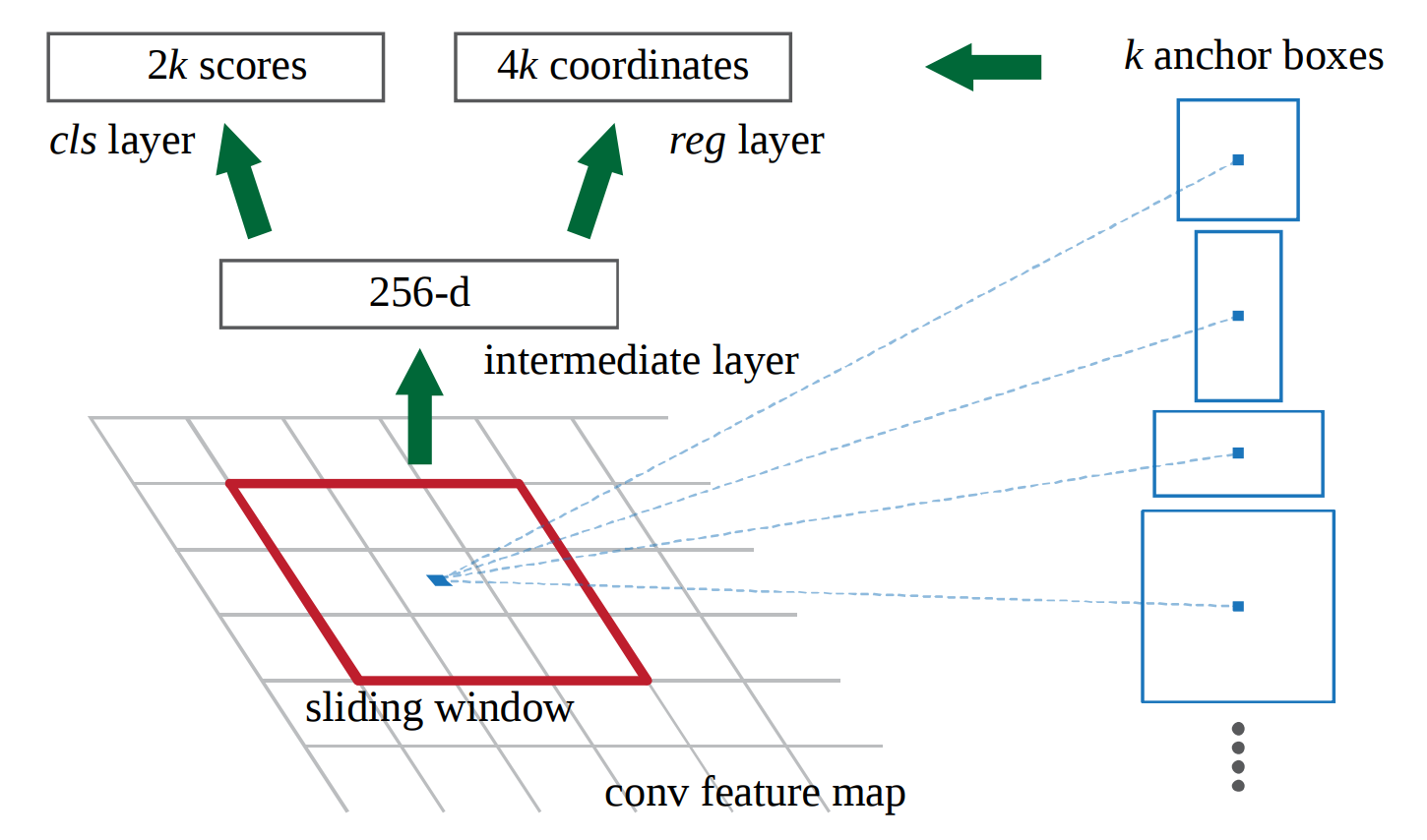
In the paper they write
“we randomly sample 256 anchors in an image to compute the loss
function of a mini-batch, where the sampled positive and negative
anchors have a ratio of up to 1:1”
That’s the part I’m not sure about. Does this mean that for each one of the 9(k) anchor types the particular classifier and regressor are trained with minibatches that only contain positive and negative anchors of that type?
Such that I basically train k different networks with shared weights in the intermediate layer? Therefore each minibatch would consist of the training data x=the 3x3x512 sliding window of the conv feature map and y=the ground truth for that specific anchor type.
And at inference time I put them all together.
I appreciate your help.