Hi all,
First I just wanna say a big thanks to Jeremy and Rachel for putting together this amazing course. And of course to the community here on the forums!
I’m trying to implement my first unsupervised model from this paper:
Learning Temporal Embeddings for Complex Video Analysis
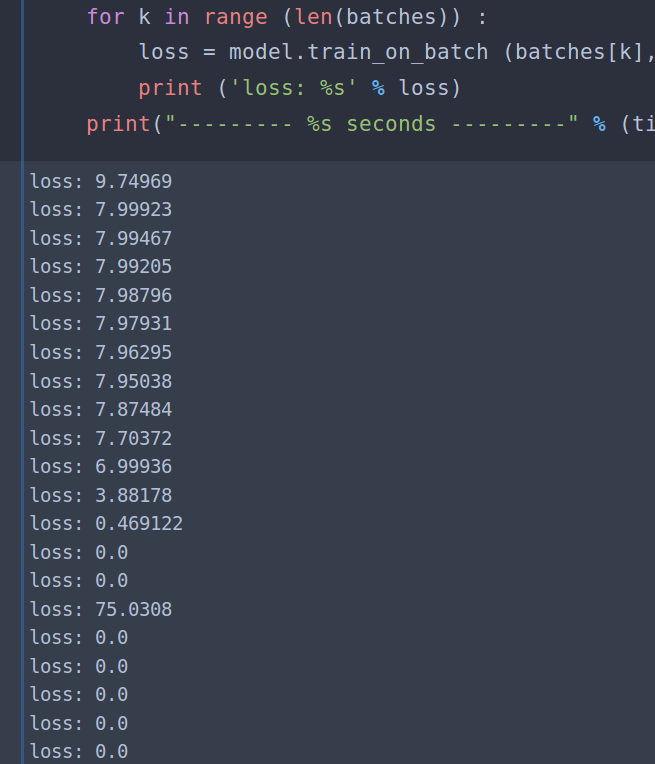
The main idea in the paper is kinda like word2vec but they are trying to encode temporal information into video frame embeddings. Anyway it was all going fine until I started training it. My loss function would nose-dive to zero after only a couple of batches. And it stays there right at exactly 0.0 - presumably learning nothing about projecting the embeddings.
This suggests that I’ve probably messed up the implementation at some point.
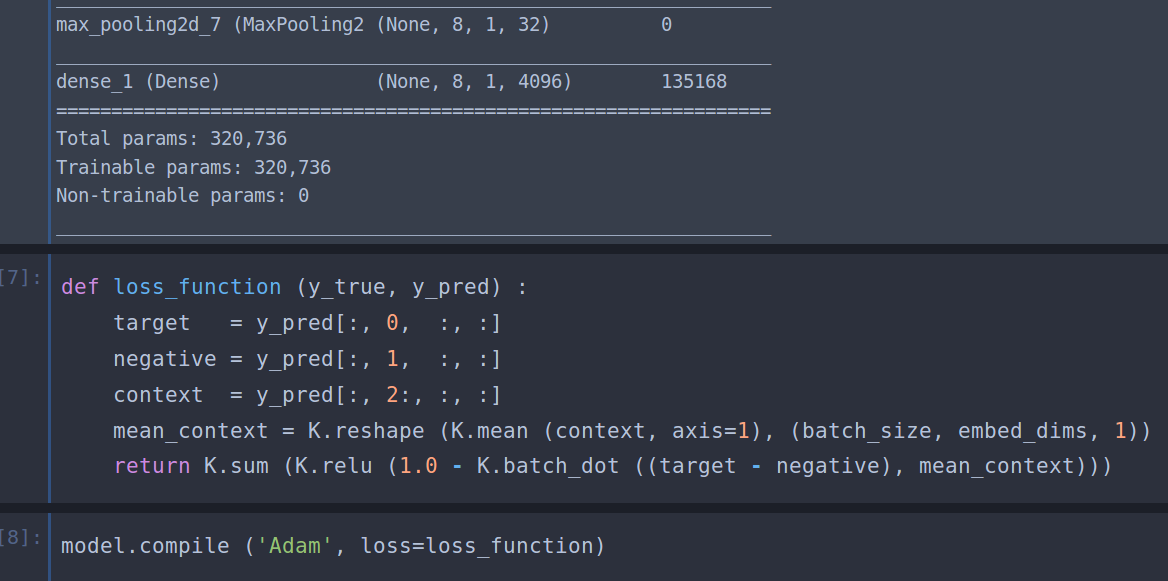
So here’s the loss function from the paper - it’s quite straightforward I think:

And here’s my implementation of the loss function with the keras backend:
And here’s what my loss looks like when I train it:
There is a caffe implementation that the authors kindly provide but I’m not implementing their multi-temporal resolution data augmentation(phew!) version just yet - I’m just sampling at one rate for now. Also I was having a lot of trouble understanding their code as I’ve zero knowledge of caffe unfortunately (my bad).
Hopefully I just made some rookie mistake that’s obvious you all. Any help would be greatly appreciated!
Thanks!