You may have noticed that the first modules of fastai_v1 appeared on github yesterday. They cover the notebooks 1, 3 and 4 (everything in dev_nb apart from data augmentation) which represents everything that has to do with training.
Even if a lot of stuff is still missing, the structure is already there: the imports folder will contain specific imports module separated by topics (core, torch, vision, text, structured/tabular). Basically each module will depend on imports.core then we add the stuff we need depending on the situation.
Inside the library, the lowest modules are core and torch_core, which contains the utility functions that will be used in the other modules. Following the conclusion of this topic, there won’t be systemic import * in fastai_v1, so the conventions are to import core as c and torch_core as tc. In the other modules, we import the specific functions/classes needed.
Above core is data, which contains the Dataset/DataLoader and DataBunch (an object regrouping the different data loaders). It will depend on the module transforms once this one exists.
Just on top of data is the basic module that defines the callbacks, callback. It also contains the wrapper around the optimizer and the Recorder (since this callback is always created by Learner objects). Then we have basic_training, where the training loop is as well as the Learner object.
The more advances features are defined in callbacks, a separate folder where each separate callback is defined in his own file for more readability. The imports.callbacks module is there to regroup all the names of those callbacks, and the convention is to import it as cb in the other modules.
Then the highest module is train, which contains the helper function that will create the callbacks and launch training (for instance lr_find(learn), or fit_one_cycle(learn, lr, cyc_len)). Lastly there is a fastai.everything just to be able to type from fastai.everything import *, which is going to be the norm in the notebooks of the course.
Here the graph of dependencies:
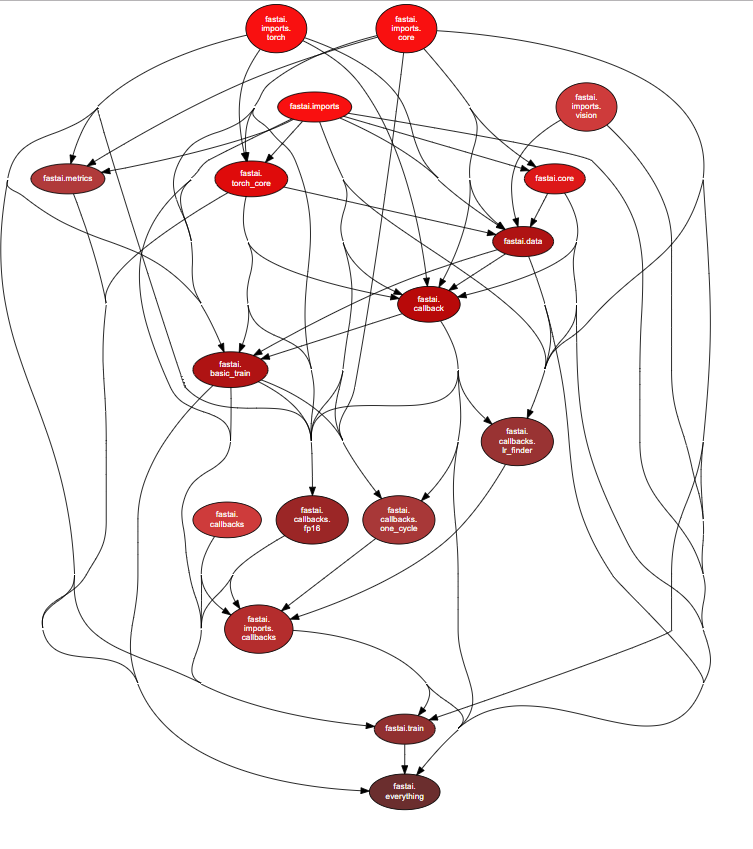
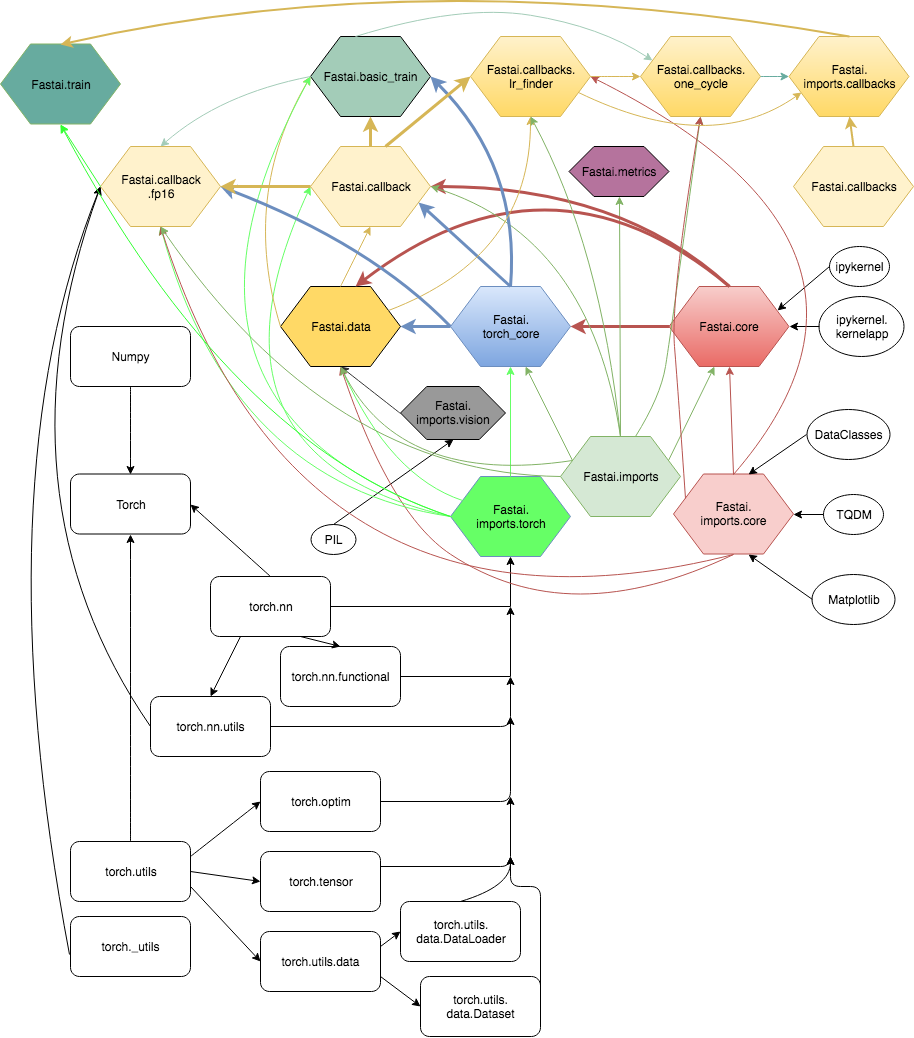
Full file is here if you can’t see properly, and the bigger one with external modules is here.
{kind=link}
{kind=link}