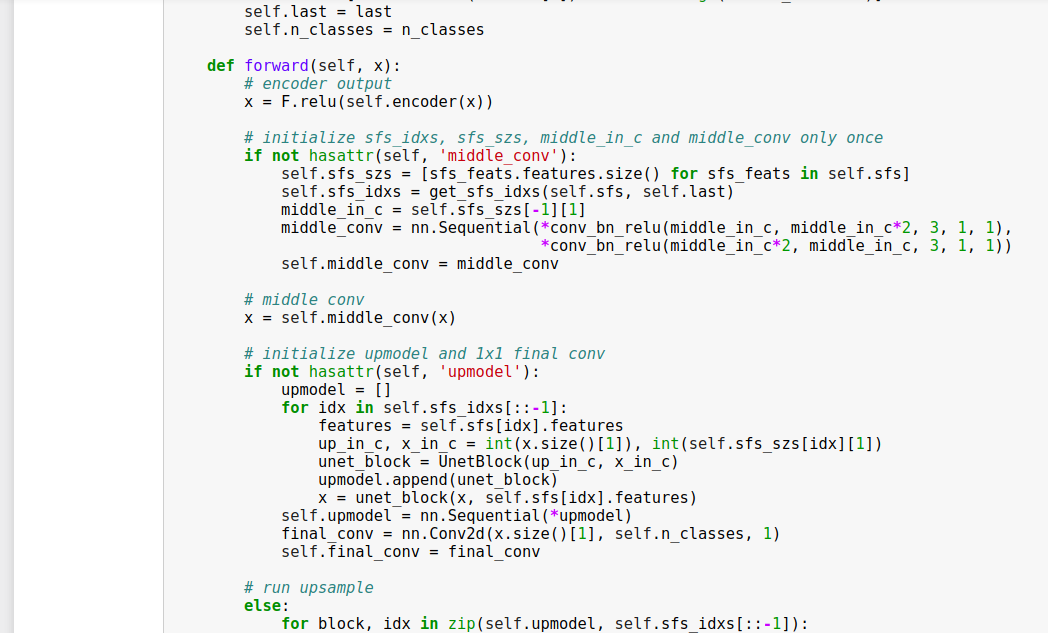
As we were discussing yesterday as a first part of semantic/(later to be instance) segmentation task I’ve implemented a dynamic Unet. This model takes any encoder you define and generates the decoder part as first forward pass is completed. I’ve tested it with Resnet18, Resnext50 and VGG16. Of course you can also define any encoder you like. Here is the notebook link https://github.com/KeremTurgutlu/deeplearning/blob/master/datasciencebowl2018/FASTAI%20-%20DSBOWL%202018.ipynb. Would this be something worth implementing into Fast.ai @jeremy ?
Very much so! Great idea, and looking great. The notebook has a note about problems with resnet, but you say above it works - is the note wrong?
Why are you using setattr rather than just setting the attribute directly?
It’s somewhat tricky code so would love to see some extra care around comments, code structure, naming, etc so that it’s as clear as possible. Also, look out for memory leaks. I had a lot of trouble with memory leaks when I was doing unet, and am not sure I got rid of them. Make sure you can re-create that model a few times in a notebook without GPU RAM filling up.
Right, I also felt those problems. That’s why wanted to ask about them to you, I believe this is more of a pre-release for those who want to use it as soon as possible but risk would be on them.
I used VGG16 since it’s outputting in original image size and I thought a simpler architecture would be more suitable for this kind of data. About resnet I will add an argument for allowing a final conv-transpose to met the original size of the input image as you did in Caravana notebook.
How can I substitute setattr? It didn’t seem to be the best option to me as well but couldn’t think of anything else fast.
Now I am fixing for Resnet or any encoder which down samples as soon as the first layer.
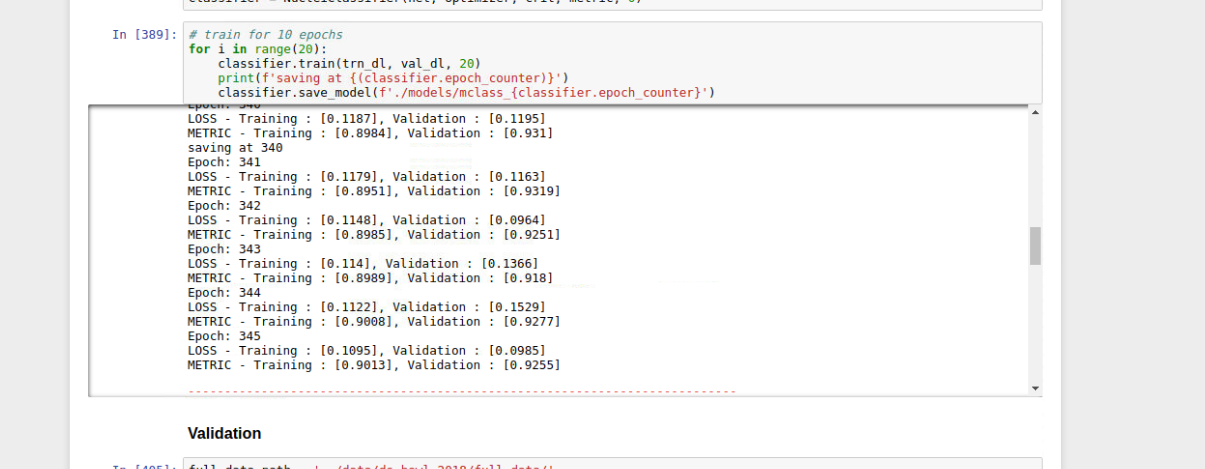
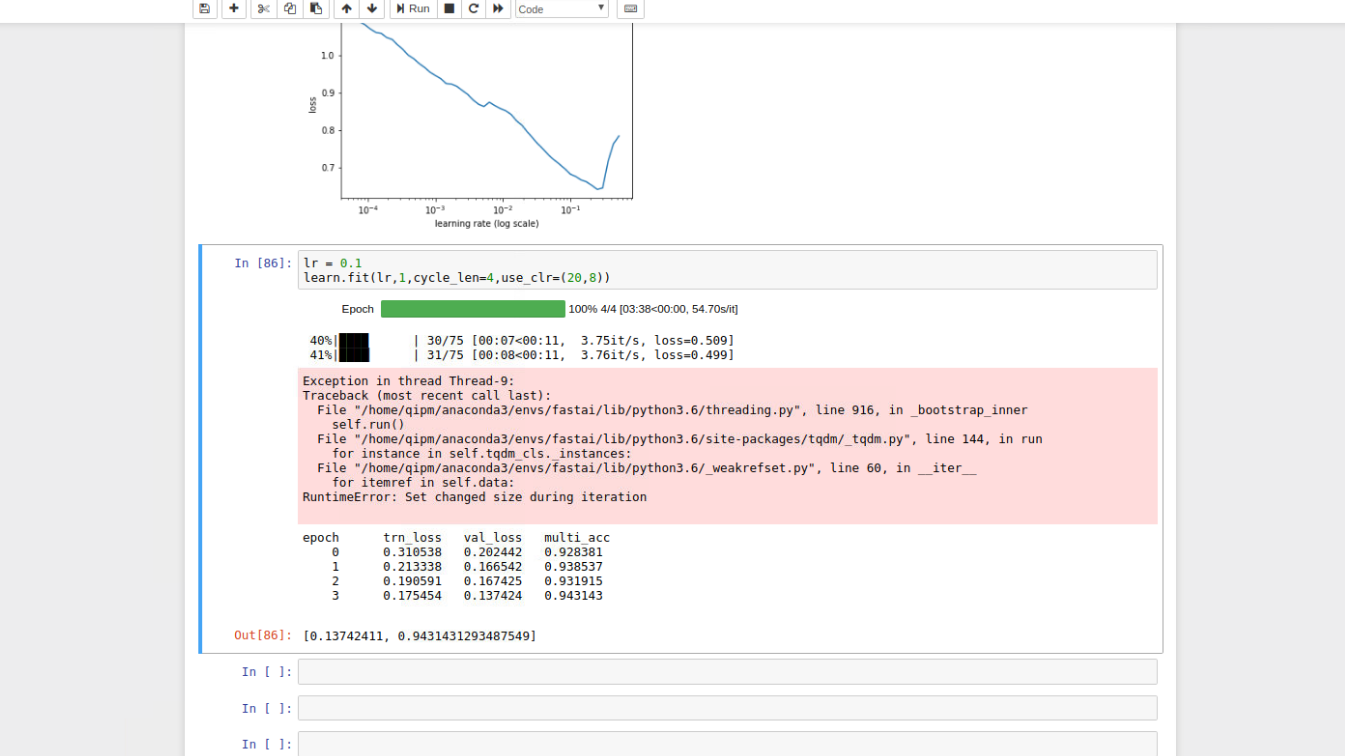
Ok I fixed ResNet like situations + setattr. I also added step by step walk through in the notebook. In total of 7 steps you can start your segmentation training in fastai with any desired encoder. By the way ResNet is slightly worse than VGG16 multi_acc = 93.86% but of course lot of self decisions are effecting the result (like cut_lr and cut).
Can I implement neural style transfer first as I’ve learned forward hook from you Would it be something interesting? I believe it’s fairly simple since we already have a bunch of models in our own zoo.
Yes that’s not surprising - part of the reason I’m working on imagenet training is to prepare a demo of why this is, and create a better resnet for localization…
Absolutely. Maybe start out by looking at the ‘enhance’ notebook where I’ve had a first attempt at super-resolution, which is nearly the same thing. You could try to finish/clean that up, and then add style transfer to that notebook, if that sounds reasonable. Feel free to dynamicize what’s there!
Before you work on the new stuff, perhaps think about the best place to integrate this into fastai and send in a PR, with a brief docstring saying what it is and how to use it?
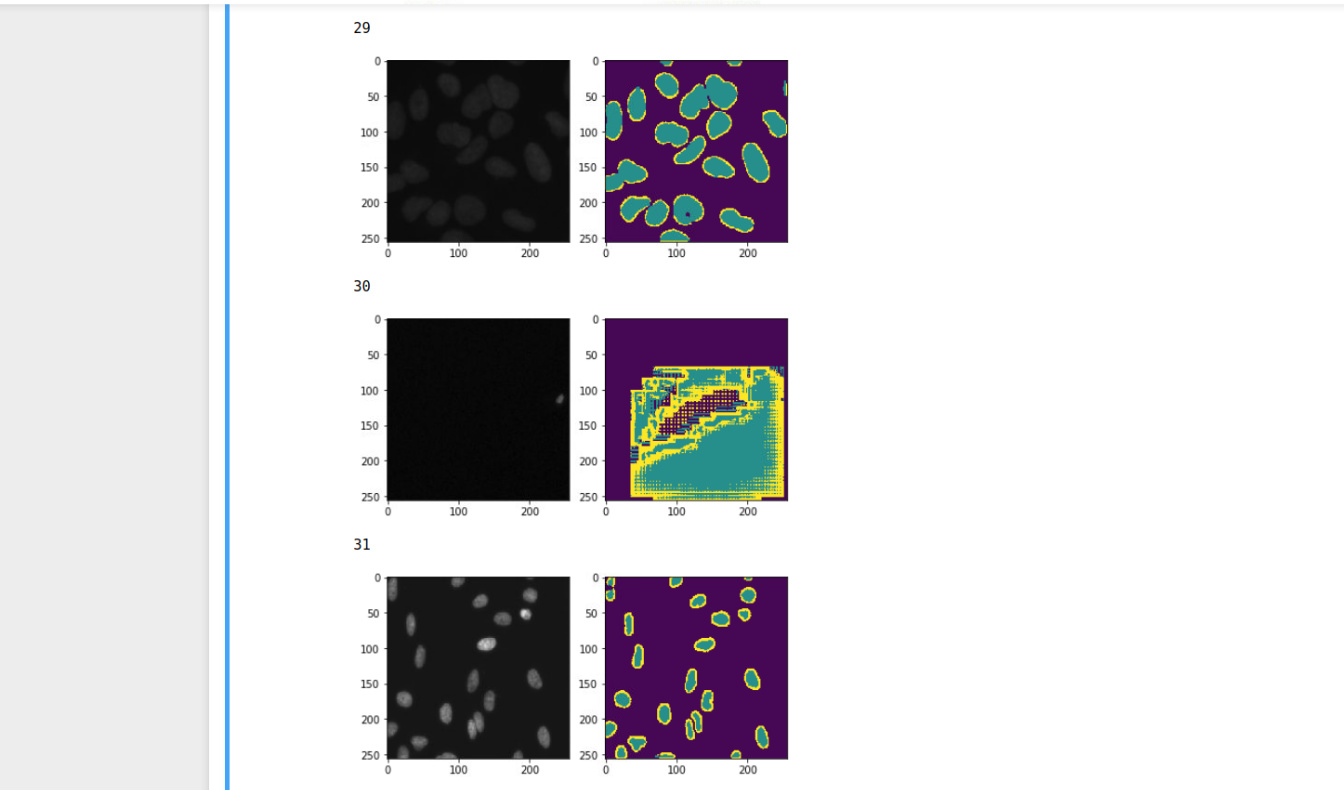
Of course! That’s my priority right now. By the way do you have any hypothesis on this type of behavior (validation) ? I plotted all validation preds since my loss went crazy while multi_acc metric is still fine…I believe this one is causing that but don’t know why it might give a cross entropy like :
EDIT: Ok found the error, I plotted the histogram of pixel outputs for validation case 30. And max value is xxx10e26 which comes out to be 1 after F.softmax().
Exciting! I’m happy to cooperate on a paper on this if you’re interested; if you don’t have time for that, it at least deserves a blog post. It’s pretty damn cool…
Of course I am interested ! I am done with practicum and I was thinking of allocating all my time to deep learning studies and Fast.ai. It would be a great opportunity for me to learn great things. I am also planning to join every SF group meeting from now on. Should we discuss more about it in the next meeting ?
Very interesting idea @kcturgutlu ! I am happy that you went deeper into unet since our discussion on twitter months ago ! I hope your meningioma project is going well.
It will be easier to test different architectures and network depth with this idea. Most published unet instances are relatively shallow compared to the popular imagenet based classifiers. This frequent relatively low number of parameters explains probably the observed benefit to perform and generalize well on low number of samples. But just retraining the decoder and freezing a pretrained encoder could potentially get interesting results on some problems.
I’ve actually tried what you recommended in our first discussion; first trying a 2d model for each slice then compare it with a 3d model. As you had foreseen, 2d had locality issues since it’s not accounting for dependencies among slices but 3d was able to output a single homogeneous volume. We had good results on meningioma cases but still waiting for more data ! We also ran the 3D model on ventricles, we got ~80% dice score, but it’s the baseline and it can be improved as we will continue to work on ablation. Another idea I have for meningioma or volumetric medical data is to try a 3D-Resnet like architecture to go even deeper but data might be an issue here.
Aside from these, inside fastai we are working on mask-rcnn and will try to implement it. I’ve been reading related papers as well as the RetinaNet paper from FAIR. They propose a single shot object detector with focal loss. Then I thought can we actually add another subnet for mask predictions and do a single shot mask-rcnn. I am probably missing a lot of the components as I am still at the learning stage of these complex architectures. But would this be something possible to obtain ? I also wanted to ask @jeremy about this.
I asked about this on twitter recently and the idea was met with skepticism. I have thought carefully about it yet though. Someone on twitter pointed to a 1-shot instance segmentation paper btw - it should be in my twitter favorites if you want to search.