Damn! Works like a charm now 
That was quick! It works fine now 
Trying to understand if this conversation is about how to train with the entire data and all of the intelligence of the resnext model - what is meant by not “removing the last layer from pretrianed models” and " they are using the fully connected layers where we take those off and calculate our own"?
How can I do what is being talked about here - what is it that we do that removes the last layer, what can we do that preserves it?
Also, how can we retain all of the data to train with?
If you just want to remove the last layer you may need to do a little bit of extra work. One possibility is what I did here.
https://github.com/yanneta/pytorch-tutorials/blob/master/modified_VGG.ipynb
This could be simplified with the new API that Jeremy just wrote. See an example here.
https://github.com/fastai/fastai/blob/master/courses/dl1/cifar10.ipynb
I am happy to help if you have any questions. My example work for vgg16 you would have to understand the network that you are trying to change.
I’ve got an example of how to cut layers off custom models that I’ll be pushing soon-ish. We’ll be discussing it later in the course.
2 Likes
OK this is at the more advanced end for now - but for those interested in understanding fastai more deeply:
I just added nasnet.ipynb . It shows how to use a new pretrained model type that’s not already in fastai. (This particularly one is really slow BTW, although it should be better with 0.3).
Note that I also changed fastai.models.nasnet to optionally skip that classifier section.
10 Likes
Actually I am quite confused about what is being discussed here.
What I was asking here was for someone to explain exactly what were these guys getting at when they said that the (I presumed standard) approach is “removing the last layer from pretrianed models” - because the guys that are NOT doing that are getting better results. I was not asking how to remove the last layer - but how to understand what the contributors @bushaev, @jamesrequa and @KevinB meant that we should NOT be removing it, and that they (the better scoring people) are “using the fully connected layers where we take those off and calculate our own”. Do they mean that we shouldn’t set precompute to false? It didn’t make sense to me…
I was asking for clarification, but if I understand it correctly, they are doing well because the data is literally being trained on the same images that are in the test set. So this would be comparable to training using our validation set. It would give us a very good score, but it doesn’t really help in any real-world scenario. They are basically exploiting the fact that they know what data the set comes from and choosing a model that starts with that and keeping those activations. I was and still am asking for clarification on whether I actually understand why they are doing so well, but that is what I was asking in my post.
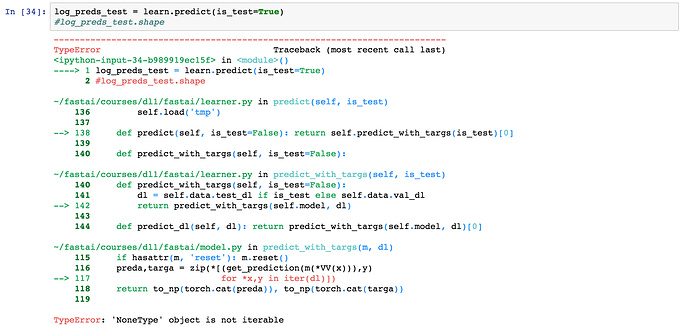
I have tried this, and val_idxs = 0, and also val_idxs = get_cv_idxs(n, val_pct=0.01), but I continue to get an error (below). Does anyone know how to do this reliably?
Should we have one image per class in our validation set?
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-24-0708a7145fb8> in <module>()
----> 1 learn = ConvLearner.pretrained(arch, data, precompute=True, ps=0.5)
~/fastai/courses/dl1/fastai/conv_learner.py in pretrained(cls, f, data, ps, xtra_fc, xtra_cut, **kwargs)
92 def pretrained(cls, f, data, ps=None, xtra_fc=None, xtra_cut=0, **kwargs):
93 models = ConvnetBuilder(f, data.c, data.is_multi, data.is_reg, ps=ps, xtra_fc=xtra_fc, xtra_cut=xtra_cut)
---> 94 return cls(data, models, **kwargs)
95
96 @property
~/fastai/courses/dl1/fastai/conv_learner.py in __init__(self, data, models, precompute, **kwargs)
85 elif self.metrics is None:
86 self.metrics = [accuracy_multi] if self.data.is_multi else [accuracy]
---> 87 if precompute: self.save_fc1()
88 self.freeze()
89 self.precompute = precompute
~/fastai/courses/dl1/fastai/conv_learner.py in save_fc1(self)
132 self.fc_data = ImageClassifierData.from_arrays(self.data.path,
133 (act, self.data.trn_y), (val_act, self.data.val_y), self.data.bs, classes=self.data.classes,
--> 134 test = test_act if self.data.test_dl else None, num_workers=8)
135
136 def freeze(self):
~/fastai/courses/dl1/fastai/dataset.py in from_arrays(cls, path, trn, val, bs, tfms, classes, num_workers, test)
296 ImageClassifierData
297 """
--> 298 datasets = cls.get_ds(ArraysIndexDataset, trn, val, tfms, test=test)
299 return cls(path, datasets, bs, num_workers, classes=classes)
300
~/fastai/courses/dl1/fastai/dataset.py in get_ds(fn, trn, val, tfms, test, **kwargs)
264 def get_ds(fn, trn, val, tfms, test=None, **kwargs):
265 res = [
--> 266 fn(trn[0], trn[1], tfms[0], **kwargs), # train
267 fn(val[0], val[1], tfms[1], **kwargs), # val
268 fn(trn[0], trn[1], tfms[1], **kwargs), # fix
~/fastai/courses/dl1/fastai/dataset.py in __init__(self, x, y, transform)
160 def __init__(self, x, y, transform):
161 self.x,self.y=x,y
--> 162 assert(len(x)==len(y))
163 super().__init__(transform)
164 def get_x(self, i): return self.x[i]
AssertionError:
Can you post your data variable generation too?
PATH = "data/dogbreed/"
arch=resnext101_64
sz=224
bs=64
tfms = tfms_from_model(arch, sz, aug_tfms=transforms_side_on, max_zoom=1.1)
data = ImageClassifierData.from_csv(PATH, ‘train’, f’{PATH}labels.csv’, bs=bs, tfms=tfms,
val_idxs=val_idxs, suffix = ‘.jpg’, test_name = ‘test’,
num_workers=4)
OK, thanks Kevin
As you can tell from my other post, I am trying to find ways to (lawfully) increase my training data. The idea of using all of the data was recommended by @jeremy but I still have not found a way to work out how to do that!
Another thing that puzzles me (if I understand it correctly) is that our augmented data is only used in testing via the .TTA method. I thought that we should have the augmented data available to increase the size of our training set!
Hi fellows,
I am getting the following error when trying to generate the predictions for test data.
My train, valid and test folders look right. I generated them using the following scripts.
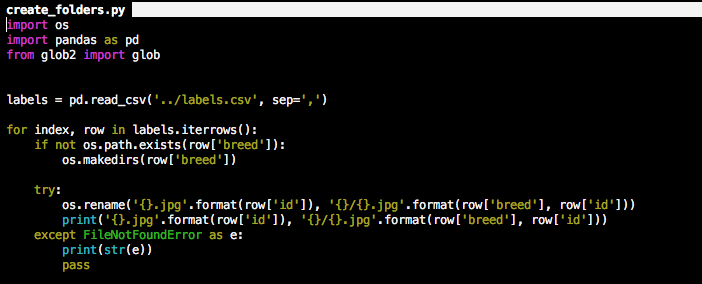
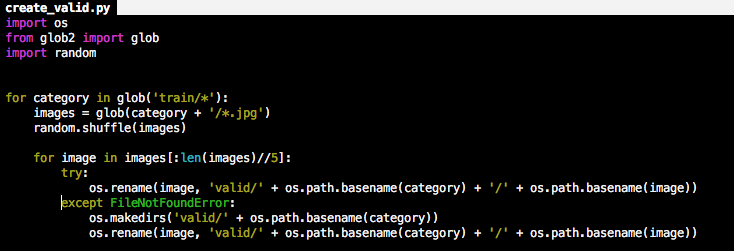
Looking back, I should have just used the ImageClassifierData.from_csv method.
It means data is None.
Screen shot of your directory might help…
Just to clarify, you are just trying to use all of your data as train and none as validation? if so, just set val_idxs=[0] This isn’t exactly what you want, but it is the easiest way to do things currently. It puts one image into the validation set and the rest into training. You won’t get very much feedback at this point though so it’s important that you already have your model all set up how you want it before making this change.
Did you set your test directory in your ImageClassifierData? do an !ls {PATH}test/ to make sure there is date in that location that you set
Hi @KevinB and @ecdrid ,
Thanks for the response.
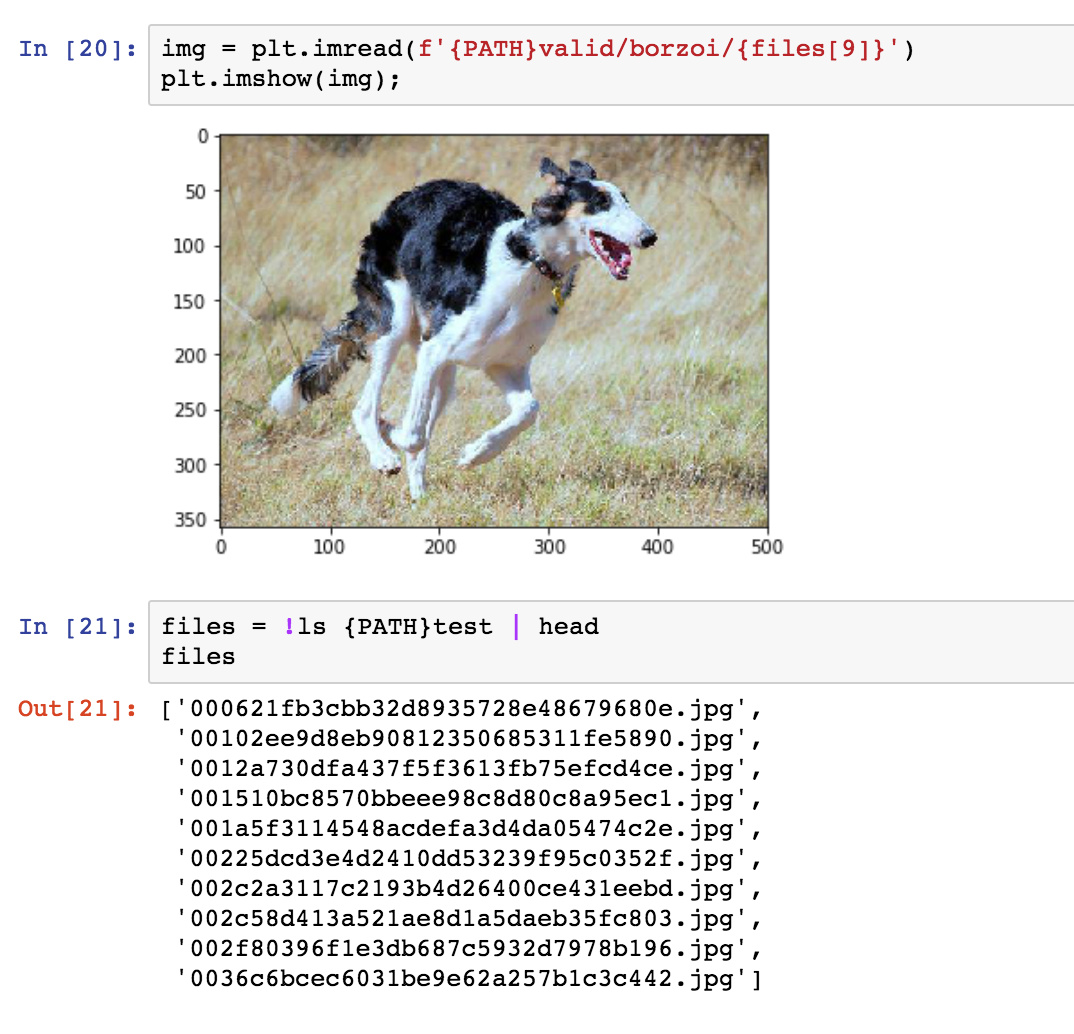
I think I do have test directory. These screenshots should clarify the directory structure.

{kind=link}
To create the valid set, I randomly picked 1/5th of the images of each breed and put them into valid/breed_name folder. Test set is as it was when unzipped from files downloaded from Kaggle.
It will use the augmented data in training only if precompute is set to false when generating the model. If precompute is set to True then things get a little murkier for me. I think at that point, the model is loaded with the activations and won’t change. I would love to hear somebody else answer that better than me though because I am still trying to work through precompute = True vs precompute = False and freeze() and unfreeze()
Augmentation is definitely a way to increase the size of your training set. It takes the picture and looks at it with different rotation, zooming, coloring, etc which can help make a model that is more generic and can help predict the test data better. Maybe there is an image of the same dog breed, but the camera is slightly closer or farther away. This lets you simulate that image possibility.
Can you show where you set data = ImageClassifierData(ALL THE INFORMATIONs)