I am working in insurance company, so I have a task to build damaged car recognition and estimation model. I have to predict how much it costs to repair the car. Currently I am in the middle of the third lesson of this course, so if your advice will be from the next lessons please make a note about it.
I think we have to divide the task into several parts.
- we have to find the location of the damaged parts.
- we have to estimate the repairing cost for each part.
- we have to sum it up.
I’ve researched a lot about this task and I’ve found this paper (https://www.ee.iitb.ac.in/student/~kalpesh.patil/material/car_damage.pdf) which I thought would be a good starting point. The main idea is to divide the damage into types like Bumper Dent, Door Dent, Glass Shatter and so on ( you can see the example below) and train the classifier. We are working on the task 1 to find locations of the damaged parts.

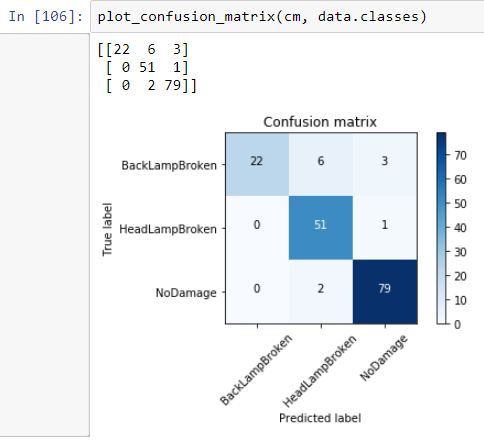
In the paper there is 8 types (output) but I decided to take 3 just for testing. So in my case I have Head lamp broken, Tail lamp broken and No damage.
Back Lamp Broken - 80 picture (Train set) 31 picture (Valid set)
Head Lamp Broken - 145 picture (Train set) 52 picture (Valid set)
No Damage - 243 picture (Train set) 81 picture (Valid set)
The examples of the training set of each type is here.
All the original images have 480 x 640 resolution, I crop the damaged parts with 320 x 320 resolution (+ - 20 )
Head Lamp Broken

Back Lamp Broken

No Damage

I’ve used lesson 1 material. The final results are below ( I used resnet34). The Accuracy is 0.926829268292683
Now if we want to localize the damaged part, As the paper says, "For each pixel in the test image, we crop a region of size 100×100 around it, resize it to 224×224 and predict the class posteriors. A damage is considered to be detected if the probability value is above certain threshold (0.9) " I think for each pixel would be too much so I took 100x100 square and shift 20 pixel each time (sliding window), then I am predicting the result for each 100x100 image and if the probability is more than 0.9 I’m saving the image.
below there are some examples of this process
Starting Image :
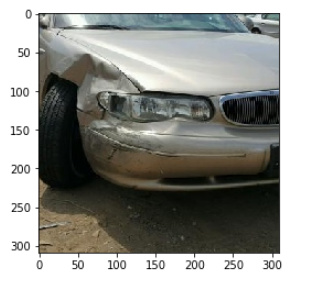
100x100 images prob > 0.9

Final result to localize the damaged parts:

In this case it works fine, but in the list of 100x100 pictures the 4th picture is not damaged but the probability is 0.95, Also taking into consideration that this image was not the original (480 x 640) and was the croped one( 320x320) the result might not be that good. so lets take a look 480 x 640 case.
First Case :
Starting image :

100x100 images prob > 0.9

final image localization :

In this case it works fine, but there is still error the snow on the ground has prob > 0.9
Second Case :

100x100 images prob > 0.9 :

result localization :

As you can see in the second case the result is worse, It can’t detected the broken Lamp but detect the unbroken middle part of the car. In some cases I have even worse results but there are also good results …
So there are several tasks to do next. I have to add damaged types (The problem here is that in some picture there will me more than one damaged type), I have to collect more data, somehow I have to differentiate between good localized parts and bad localized parts (but both of them have >0.9 probability and I don’t know how) and I have to start the second task which is to Estimate the repairing costs (I have no idea how to do this).
So any tips, advice and help from those who have some experience would be great for me. Thanks in advance !
 )
)