Is there an AMI that would work on the p3 instances? Or, what kind of tweaks might I try to get this AMI working? This is great for working through notebooks but sometimes I crave the speed I see on paperspace instances when trying stuff out.
No AMI, but if you simply install anaconda, git clone the repo, and conda env update you’ll be ready to go!
2 Likes
Hi Ramesh
I am still not quite getting the results I want.
First of all I do not have a static IP adress do I need one?
Secondly, I still need to tunnel, including -L 8888:localhost:8888, otherwise I cannot connect to Jupyter notebook from my browser
When I connect to http://localhost:8888 I now have to enter a password, so something has "worked"
But if my connection drops, as it did today due to a momentary loss of Internet connection, then even if I reconnect to my running AWS server I have to reload everything in the notebook and start again.
Which is what I am trying to fix.
Is there any way we can get the learning process to proceed without needing to be permanaently connected to the notebook via my flaky internet connection? Should we do it all in the terminal window and bypass the Jupyter Notebook - it really is being a pain and the weak link
If your Internet is flaky, I would suggest don’t use Tunneling to run Jupyter Notebook. Access Jupyter Notebook directly on the browser via AWS AMI available for testing. That does not use localhost:8888 method, but via http://<ec2 address>:8888.
You don’t need static IP for this, but I would recommend that you run Jupyter Notebook inside a tmux session in your AWS. That way if your ssh -i <pem key> ubuntu@<ec2 address> gets disconnected, your tmux session is still running and that’s keeping your jupyter process also running.
1 Like
Thanks for replying again Ramesh!
I think I got confused about the directions and had a mixed up environment. Having started again without using the -L 88888:localhost:8888 in my tunnelling thigs work as you have described.
I haven’t had a chance (luckily!) to test it, but in this scenario, even if I lose my connection to my EC2 instance, that is, even my terminal window as well as my browser are no longer communicating with the server, will the server keep running and I can reconnect once my internet is working again? If so, will I be able to navigate to the running notebook, open it, and I should still see it chugging away through whatever process I had set running?
Glad to be of help. You can pick up from where you left off by opening the same notebook, but you still need to Save the Notebook periodically. One caveat - If a particular cell was running and you lost your internet connection, you may not see the results. You can pick up from the previous cell that executed successfully.
Notebook is not intended to be run and I will check later. Its more for interactive sessions. If you have long running cells, it should ideally be run as .py file on command line.
Is it possible to run the training on the command line and then persist it so you can later load it into a notebook? Does the learn.save do that, or is that more for creating a check point in a currently running model?
1 Like
learn.save does indeed do that. Although I don’t understand what you mean by " is that more for creating a check point in a currently running model"…
1 Like
Hi @Jeremy
I wasn’t sure if learn.save was fully persisting the complete model (weights and all) on the hard disk, so it could be simply loaded in a brand new session / notebook, or if it merely recorded information that is accessible and makes sense only within the currently running session.
To make this clear, if I created something I like and used learn.save, then powered down my AWS instance and came back the next day, can I use learn.load to reload the fully configured model into a new notebook on my newly running instance, without any preparatory work apart from loading libraries (and possibly data?), in my brand new session?
Yup. I mean - you first need to construct the model (e.g. using pretrained()), but then you load the weights into it.
1 Like
Thanks Jeremy
Is this something you could demonstrate, or have demonstrated or blogged about? The reason why this is important is because I have lost heaps of time and work when I drop my internet connection, so I was wanting to see if there is a way to recover more quickly back to my last saved position.
1 Like
Once you’ve created your learn object in the usual way, just type learn.load('filename'), and that’s it!
Just like you have been doing all along?
OK, I will try it on one I saved a few days ago - thanks!
Hi Jeremy
I finally got around to trying this, and got an error. Are you able to help me undertand what I did wrong? I tried finding something that looked like this saved name on my hard disk but couldn’t locate it. Does it get affected by any other process such as updating code through git or conda env upgrade?
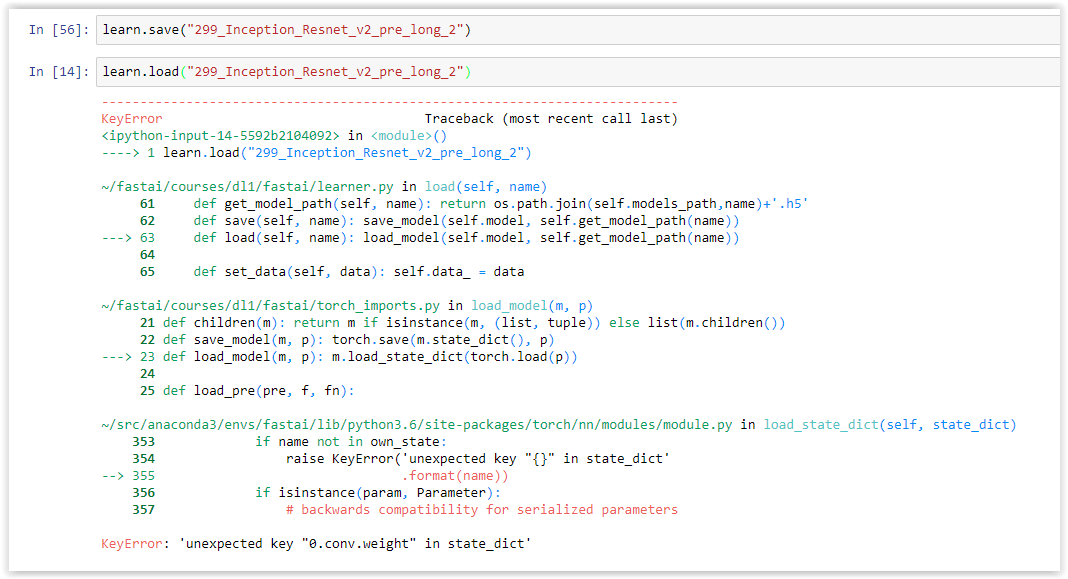
Yes if the model definition has changed it won’t be able to load it. Also, if you save with precompute=False, you must load with the same value (and visa versa).
@jeremy Is it possible to share the script used to create the ami-8c4288f4 gpu-p2 AMI we use for the course?
I would like to see how the compatible versions of Nividia drivers, Cuda, CuDNN, Pytorch, Keras, Tensorflow are installed.
As I mentioned earlier in the thread, there’s nothing to see. Just grab the AWS Deep Learning AMI, and then simply install anaconda, git clone the repo, and conda env update you’ll be ready to go!
3 Likes
At work we do not have access to community AMIs, so I have to recreate the box from vanilla ubuntu. So just wanted to make sure I install the correct and compatible versions of Cuda and CuDNN.
After that I can always install Anaconda, git clone the repo and conda env update to the get the libraries.
This might help. https://aws.amazon.com/blogs/ai/new-aws-deep-learning-amis-for-machine-learning-practitioners/
The AWS Deep Learning AMI is not a community AMI, it’s official. Maybe you can access that?